2024. 9. 13. 14:29ㆍGCC/데이터 애널리틱스

데이터 계산 시작하기
데이터 계산
1. 데이터 분석에서의 효율성
- SQL 사용의 중요성: Google에서의 경험을 공유하며, SQL을 통해 데이터를 가져오고 분석하는 것이 업무 효율성을 크게 향상시켰다는 내용을 강조합니다.
- 효율적 작업: 분석 시간 단축과 성과 향상을 위해 SQL을 활용한 사례 소개.
2. 스프레드시트 기본 계산식
- 기본 계산식: 스프레드시트의 기본 계산식을 살펴보고 이를 활용해 효율적인 계산을 진행합니다.
- IF 함수: 조건부 수식을 통해 특정 조건을 충족하는 데이터를 필터링하고 계산할 수 있는 방법을 다룹니다.
3. SUMPRODUCT 함수
- SUMPRODUCT의 활용: 덧셈과 곱셈을 한 번에 처리하여 분석 속도를 5배 이상 향상시키는 방법을 소개합니다.
4. 피벗 테이블
- 피벗 테이블 복습: 피벗 테이블을 처음 다루는 사람도 쉽게 이해할 수 있도록 피벗 테이블의 기능과 계산 결과를 구성하는 방법을 배웁니다.
5. SQL 심화 학습
- 쿼리와 계산의 관계: SQL에서 데이터를 쿼리하고 계산을 수행하는 과정에 대해 설명합니다.
- 임시 테이블: 분석 중 데이터를 임시로 저장하고 처리하는 임시 테이블의 개념을 다룹니다.
일반적인 계산식
1. 실생활과 데이터 애널리스트의 계산
- 일상생활에서는 간단한 계산을 자주 하게 되며, 휴대전화 계산기나 종이와 펜을 사용할 수 있습니다.
- 데이터 애널리스트는 많은 데이터를 다루며 보다 복잡하고 다양한 계산을 하게 됩니다. 이러한 계산을 빠르고 정확하게 하기 위해 스프레드시트와 같은 도구를 활용합니다.
2. 스프레드시트에서 기본 계산 처리
- 스프레드시트에서 수식을 사용하면 데이터를 기반으로 다양한 계산을 할 수 있습니다.
- 여기서는 SUM 함수 등 기본적인 수식을 사용하여 할인 체인점의 연 매출 데이터를 분석합니다.
3. 매출 데이터 분석: SUM 함수
- 연 매출 계산: 주어진 월별 데이터를 더해 연도별 총매출을 계산합니다.
- 수식을 입력할 때, 등호(=)로 시작하고 SUM 함수를 사용해 원하는 셀 범위를 지정합니다.
- 예를 들어, 2011년 매출을 계산할 때 =SUM(B2:M2)처럼 입력합니다.
- 채우기 핸들: 수식을 복사하여 다른 연도의 매출 계산에도 적용할 수 있습니다.
- 예를 들어, 2011년 매출 수식을 작성한 후, 채우기 핸들을 사용해 나머지 연도의 매출을 한 번에 계산할 수 있습니다.
4. 연 매출 증가율 계산
- 매출 증가액: 연도별 매출의 차이를 계산합니다.
- 예를 들어, 2012년 매출에서 2011년 매출을 빼는 수식을 작성하여 증가액을 구합니다: =N3 - N2.
- 매출 증가율: 증가액을 기준으로 각 연도의 매출 증가율을 계산합니다.
- 증가율을 구할 때, 증가액을 전년도 매출로 나눕니다: =O3 / N2.
- 백분율로 변환: 스프레드시트의 백분율 스타일 기능을 사용해 계산된 값을 백분율로 변환합니다.
5. 평균 매출 계산
- AVERAGE 함수를 사용해 월별 매출 데이터를 기반으로 연평균 매출을 구할 수 있습니다.
- 예를 들어, 1월부터 12월까지의 평균을 계산하려면 =AVERAGE(B2:B11)처럼 수식을 작성합니다.
- 평균값을 계산한 후, 다른 달에도 동일하게 적용해 각각의 평균 매출을 구할 수 있습니다.
6. 조건부 서식으로 데이터 시각화
- 조건부 서식을 사용해 매출 데이터를 시각적으로 표시할 수 있습니다.
- 예를 들어, 월평균 매출이 높은 달과 낮은 달을 구별하기 위해 색상 스케일을 적용하여 셀의 색상을 다르게 설정합니다.
- 매출이 가장 낮은 달은 흰색, 가장 높은 달은 짙은 초록색으로 설정해 한눈에 추세를 파악할 수 있습니다.
7. 최솟값과 최댓값 계산
- MIN 함수: 월평균 매출 중 가장 낮은 값을 찾습니다: =MIN(B2:M2).
- MAX 함수: 월평균 매출 중 가장 높은 값을 찾습니다: =MAX(B2:M2).
8. 결과 해석 및 공유
- 분석 결과에 따르면, 매출이 가장 높은 달은 12월, 가장 낮은 달은 1월입니다.
- 이러한 분석 결과는 이해관계자와 공유하거나 추가 분석을 위한 중요한 정보가 될 수 있습니다.
함수와 조건
COUNTIF 함수
COUNTIF 함수는 특정 조건을 충족하는 셀의 개수를 셉니다. 예를 들어, 특정 거래에서 상품 수량이 1인 경우의 개수를 알고 싶다면 COUNTIF를 사용하여 그 개수를 계산할 수 있습니다.
COUNTIF 함수 구조
scss
COUNTIF(범위, 조건)- 범위: 조건을 검사할 셀들의 범위입니다.
- 조건: 셀들이 충족해야 할 조건입니다. 예를 들어, ‘=1’은 해당 범위 내에서 값이 1인 셀의 개수를 셉니다.
예시: 상품 수가 1인 거래 횟수 구하기
- 수량 데이터가 있는 B열에서 1인 거래를 세기 위해 COUNTIF 함수를 사용합니다.
수식을 셀 G11에 입력합니다:
less
=COUNTIF(B3:B50, "=1")이 수식은 B3부터 B50까지의 범위에서 값이 1인 셀을 셉니다.
- 결과는 상품 수량이 1인 거래 횟수로 표시되며, 결과는 25입니다.
조건 변경: 1보다 큰 거래 횟수 구하기
이번에는 수량이 1보다 큰 거래 횟수를 계산합니다:
less
=COUNTIF(B3:B50, ">1")이 수식은 B열에서 상품 수량이 1보다 큰 거래를 계산하며, COUNTIF 함수는 조건을 변경하여 다양한 질문에 답할 수 있게 해줍니다.
SUMIF 함수
SUMIF 함수는 주어진 조건을 만족하는 값들의 합계를 계산합니다. 특정 기준에 맞는 거래의 총 수익을 계산할 때 사용합니다.
SUMIF 함수 구조
scss
SUMIF(평가범위, 조건, 합계범위)- 평가범위: 조건을 평가할 셀의 범위입니다.
- 조건: 합계를 구할 셀들이 충족해야 할 기준입니다.
- 합계범위: 조건을 만족하는 셀에 해당하는 값을 더할 범위입니다. 평가 범위와 다를 수 있습니다.
예시: 상품이 1개인 거래의 총수익 구하기
수식을 셀 H11에 입력합니다:
less
=SUMIF(B3:B50, "=1", C3:C50)이 수식은 B열에서 상품 수량이 1인 거래를 찾아 C열의 수익을 모두 더합니다.
- 결과는 상품이 1개인 거래의 총수익으로 표시되며, 1,555달러입니다.
조건 변경: 상품이 1개보다 많은 거래의 총수익 구하기
상품이 1보다 많은 거래의 총수익을 계산할 때는 조건을 다음과 같이 변경합니다:
less
=SUMIF(B3:B50, ">1", C3:C50)결과는 4,735달러입니다. 이로써 상품이 2개 이상인 거래의 수익이 더 많다는 것을 알 수 있습니다.
거래별 평균 수익 구하기
두 유형의 거래에 대해 평균 수익을 구하려면 총수익을 거래 횟수로 나눕니다. 이때 슬래시(/)를 사용하여 나눗셈을 합니다.
- 상품이 1개인 거래의 평균 수익:계산 결과는 62.20달러입니다.
=H11/G11
- 상품이 1개보다 많은 거래의 평균 수익:계산 결과는 205.87달러로 표시됩니다. 이 값은 상품이 더 많은 거래에서 수익이 크다는 것을 나타냅니다.
=H12/G12
데이터 시각화와 조건부 서식
데이터를 시각적으로 이해하기 쉽게 만들기 위해 조건부 서식을 사용합니다. 조건부 서식은 특정 조건을 만족하는 셀을 강조하는 기능입니다. 예를 들어, 수익이 높은 셀은 진한 색상으로, 수익이 낮은 셀은 연한 색상으로 표시하는 방식입니다.
이처럼 데이터 분석에서는 COUNTIF와 SUMIF 함수가 빠르고 정확한 집계 및 분석을 도와주며, 데이터의 패턴을 찾아내는 데 중요한 역할을 합니다. 특히, 수백 또는 수천 개의 행을 포함한 대규모 데이터 세트에서 이 함수를 사용하면 시간을 크게 절약할 수 있습니다.
조건이 여러 개인 함수
이 읽기 자료에서는 조건부 함수에 관해 자세히 알아보고 여러 조건으로 함수를 작성하는 방법을 배웁니다. 조건부 함수와 수식은 특정 조건에 따라 계산한다는 사실을 떠올려보세요. 앞서 조건이 하나인 SUMIF와 COUNTIF 등의 함수 사용법을 배웠습니다. 조건이 2개 이상인 경우 SUMIFS와 COUNTIFS를 사용하면 됩니다. Google Sheets의 기본 구문을 학습하고 예를 살펴볼 것입니다.
Microsoft Excel의 유사한 함수에 관한 정보는 이 읽기 자료의 하단에 있는 리소스를 참고하세요.
SUMIF와 SUMIFS
SUMIF 함수의 기본 구문: =SUMIF(범위, 기준, 합_범위)
첫 범위는 함수에서 설정된 조건을 찾는 위치입니다. 기준은 적용할 조건이며 합_범위는 계산에 포함할 셀 범위입니다.
예를 들어 지출, 가격, 지출 날짜 목록이 있는 테이블이 있습니다.
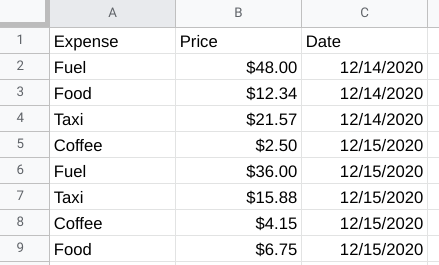
A열: A1 - Expense A2 - Fuel A3 - Food A4 - Taxi A5 - Coffee A6 - Fuel A7 - Taxi A8 - Coffee A9 - Food
B열: B1 - Price B2 - $48.00 B3 - $12.34 B4 - $21.57 A5 - $2.50 A6 - $36.00 A7 - $15.88 A8 - $4.15 A9 - $6.75
C열: C1 - Date C2 - 12/14/2020 C3 - 12/14/2020 C4 - 12/14/2020 C5 - 12/15/2020 C6 - 12/15/2020 C7 - 12/15/2020 C8 - 12/15/2020 C9 - 12/15/2020
다음과 같이 SUMIF를 사용하여 이 테이블에서 총주유비(fuel)를 계산할 수 있습니다.

SUMIFS를 사용하는 경우 조건을 여러 개 작성할 수 있습니다. SUMIF 및 SUMIFS는 매우 비슷하지만 SUMIFS는 조건을 여러 개 포함합니다.
기본 구문: =SUMIFS(합_범위, 기준_범위1, 기준1, [기준_범위2, 기준2, ...])
대괄호는 추가 기준이 선택사항임을 나타냅니다. 문 마지막의 줄임표는 기준 매개변수를 원하는 만큼 추가할 수 있음을 나타냅니다. 예를 들어 테이블에서 한 날짜의 주유비를 합산하려면 다음과 같이 여러 개의 조건을 포함해 SUMIFS 문을 작성하면 됩니다.

이 수식은 조건에 포함된 날짜에 해당하는 모든 주유비의 총액을 계산합니다. 이 예에서 두 번째 기준_범위는 C1:C9이며 두 번째 조건의 날짜는 12/15/2020입니다. 기본 구문을 따르기만 하면 SUMIFS 문에 최대 127개의 조건을 추가할 수 있습니다.
COUNTIF와 COUNTIFS
SUMIFS 함수와 마찬가지로 COUNTIFS를 사용하면 여러 개의 조건으로 COUNTIF 함수를 실행할 수 있습니다.
COUNTIF 함수의 기본 구문: =COUNTIF(범위, 기준)
SUMIF와 마찬가지로 범위를 설정한 다음 충족해야 하는 기준을 설정합니다. 예를 들어 Food가 Expenses 열에 나타난 횟수를 계산하려면 COUNTIF 함수를 다음과 같이 사용하면 됩니다.
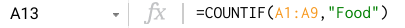
COUNTIFS의 기본 구문은 SUMIFS와 같습니다. COUNTIFS 함수의 기본 구문:
=COUNTIFS(기준_범위1, 기준1, [기준_범위2, 기준2, ...])
기준_범위와 기준은 같은 방식으로 배치되며, 조건을 더 추가할 수 있습니다. 그러므로 Expenses 열에서 12/15/2020을 기준으로 Coffee가 나타난 횟수를 계산하려면 다음과 같이 COUNTIFS를 사용하여 조건을 적용하면 됩니다.

이 수식은 기본 구문에 따라 'Coffee'와 특정 날짜에 관한 조건을 지정합니다. 그러면 두 조건을 충족하는 항목이 모두 계산됩니다.
추가 정보
SUMIFS와 COUNTIFS는 조건이 여러 개인 함수 중 일부에 불과합니다. SUMIFS와 COUNTIFS를 통해 여러 개의 조건을 함수의 기본 구문에 추가하는 방법을 살펴봤습니다. 이외에도 조건이 여러 개인 다양한 함수를 데이터 분석에 사용할 수 있습니다. 조건이 여러 개인 함수를 처음 사용할 때 도움이 되는 다음의 온라인 리소스를 참고해보세요.
- Excel IFS 함수 사용 방법: Excel의 IFS 함수에 대한 설명과 예를 제공하는 리소스입니다. IFS에 관해 더 자세히 알고 싶은 경우 유용한 참고 자료입니다. 예를 통해 쉽게 IFS 함수를 이해하고 사용법을 파악할 수 있습니다.
- 기준이 여러 개인 Excel VLOOKUP: 위 리소스와 마찬가지로 기준이 여러 개인 VLOOKUP 사용 방법을 자세히 다루는 리소스입니다. VLOOKUP에 여러 개의 기준을 적용하는 스킬은 정말 유용합니다. 이 리소스의 자세한 안내를 따라 자체 스프레드시트의 데이터를 사용해 VLOOKUP에 여러 개의 기준을 적용해보세요.
- 기준이 여러 개인 Excel INDEX 및 MATCH: 기준이 여러 개인 INDEX 및 MATCH 함수 사용 방법을 설명하는 리소스입니다. 실제 데이터를 사용한 예를 통해 기준이 여러 개인 INDEX 및 MATCH 함수의 작동 방식도 보여줍니다.
- Excel에서 AND, OR 및 NOT 함수와 함께 IF 사용: IF를 AND, OR, NOT 함수와 결합하여 보다 복잡한 함수를 만들어보는 리소스입니다. 이러한 함수를 결합하면 작업을 보다 효율적으로 처리하면서 더 많은 기준을 한꺼번에 적용할 수 있습니다.
복합 함수
데이터 애널리스트의 분석 작업 및 SUMPRODUCT 함수 활용
1. 데이터 애널리스트의 학습 방법
- 새로운 분석 방법 선호: 데이터 애널리스트는 분석 작업을 할 때 새로운 방법을 발견하고 이를 적용하는 것을 즐깁니다. 분석을 단순화하고 효율화하는 다양한 방법을 배우는 것이 중요합니다.
- 동료와의 협업 및 학습: 새로운 분석 기법을 찾는 데 매번 스스로 고민하기보다는 동료에게 질문하고 도움을 받아 학습하는 것을 선호합니다. 이는 더 빠르게 유용한 정보를 얻을 수 있는 방법입니다.
- 아이디어 출처: 동료 팀원, 온라인 게시글, 검색 등을 통해 아이디어를 얻으며, 다른 사람의 방법을 활용하는 것에 대해 부끄러워하지 않고 당당하게 사용합니다. 항상 출처를 밝히는 것이 중요하다는 것을 기억하고 있습니다.
2. SUMPRODUCT 함수 개요
- 기능 및 정의:
- SUMPRODUCT 함수는 여러 배열의 대응하는 값을 곱한 후, 그 결과의 합계를 반환합니다. 이 함수는 복잡한 계산을 간단하게 처리할 수 있는 유용한 도구입니다.
- 구문:
- =SUMPRODUCT(array1, array2, ...)
- 예: =SUMPRODUCT(B3:B7, C3:C7)
- B3:B7: 첫 번째 배열
- C3:C7: 두 번째 배열
- 각 배열의 대응하는 값이 곱해진 후 그 결과가 모두 더해집니다.
3. SUMPRODUCT 함수를 이용한 총수익 계산
- 문제 상황:
- 주방용품 업체의 데이터에는 제품의 주문 수량과 단가가 포함되어 있습니다. 이 데이터를 사용하여 총수익을 계산해야 합니다.
- 전통적인 계산 방법:
- 각 제품의 수량을 단가로 곱하여 개별 수익을 구한 후, 모든 개별 수익을 합산합니다. 예: 50 x 1.25달러 + 25 x 5달러.
- SUMPRODUCT 방법:
- SUMPRODUCT 함수를 사용하면 이 계산을 더 간편하게 처리할 수 있습니다.
- 수식 입력:
- 셀 G5에 'Total Revenue'라는 라벨을 추가합니다.
- 셀 G6을 클릭하여 수식을 입력합니다. 수식은 다음과 같습니다:
- =SUMPRODUCT(B3:B7, C3:C7)
- Enter를 눌러 총수익을 계산합니다.
- 결과를 화폐 형식으로 지정하여 총수익을 655달러로 표시합니다.
4. SUMPRODUCT를 활용한 이익률 계산
- 문제 상황:
- 총수익 계산에서 이익률을 포함하여 최종 이익을 계산해야 합니다. 이익률은 판매 금액 1달러당 몇 센트의 이익이 발생했는지를 백분율로 나타냅니다.
- 이익률 계산 방법:
- 이익률이 포함된 수익을 계산하기 위해 SUMPRODUCT 함수를 활용할 수 있습니다.
- 수식 입력:
- 셀 G7에 수식을 입력하여 이익률을 고려한 총이익을 계산합니다. 수식은 다음과 같습니다:
- =SUMPRODUCT(B3:B7, C3:C7, D3:D7)
- 여기서 D3:D7는 이익률이 포함된 배열입니다.
- =SUMPRODUCT(B3:B7, C3:C7, D3:D7)
- 수식을 완료하면 이익률이 포함된 총이익이 계산됩니다.
- 셀 G7에 수식을 입력하여 이익률을 고려한 총이익을 계산합니다. 수식은 다음과 같습니다:
5. 결론
- SUMPRODUCT의 장점:
- SUMPRODUCT 함수는 복잡한 계산을 간편하게 처리하고, 여러 배열의 값을 곱하고 더하는 작업을 빠르고 정확하게 수행할 수 있게 도와줍니다. 이를 통해 계산 시간을 절약하고 실수를 줄일 수 있습니다.
피벗 테이블
피벗 테이블 작업 1
피벗 테이블을 활용한 데이터 분석
1. 피벗 테이블의 개요
- 기능 및 장점: 피벗 테이블은 데이터를 다양한 방식으로 요약하고 분석할 수 있는 도구입니다. 이를 통해 데이터의 유용한 정보와 추세를 파악할 수 있습니다. 특히 계산 작업을 간편하게 처리할 수 있는 유용한 기능을 제공합니다.
- 예제 데이터: 영화 데이터 세트를 예로 들어, 연 수익과 영화별 평균 수익을 분석할 수 있습니다.
2. 연 수익 계산을 위한 피벗 테이블 생성
- 데이터 설정: 피벗 테이블을 새 시트에 만들어서 데이터의 계산을 다른 데이터와 분리합니다. 이 시트의 이름을 'Revenue'로 설정하여 결과의 위치를 명확히 합니다.
- 피벗 테이블 구성:
- 데이터 범위 설정: 셀 A1부터 셀 N509까지 선택합니다.
- 'Rows' 필드에 'Release Date'를 추가하여 연도별로 행을 생성합니다. 개봉 연도만 필요하므로, 'Release Date'를 클릭하고 연도별로 그룹화합니다.
- 'Box Office Revenue'를 추가하여 각 연도의 박스 오피스 총수익을 표시합니다. 피벗 테이블은 기본적으로 SUM 함수를 사용하여 데이터를 요약합니다.
- 결과를 확인하면 2014년에 수익이 가장 높고, 2016년에 가장 낮다는 것을 알 수 있습니다.
3. 영화별 평균 수익 계산
- 평균 수익 계산:
- 동일한 피벗 테이블을 사용하여 'Box Office Revenue'를 추가합니다.
- 'Summarize Values By' 메뉴에서 SUM을 AVERAGE로 변경하여 영화별 평균 연 수익을 계산합니다.
- 2015년의 평균 수익이 다른 해보다 훨씬 낮다는 결과를 확인하고, 이 데이터의 의미를 분석합니다.
- 의문 해소:
- 2015년에 영화 편수가 많았다는 사실을 확인합니다.
- 2015년의 전체 박스 오피스 수익이 두 번째로 낮은 이유를 분석합니다. 여러 개의 영화 수익이 다른 연도의 영화에 비해 낮을 수 있기 때문입니다.
4. 분석 심화
- 가설 검증:
- 피벗 테이블을 복사하여 가설 검증을 위한 새로운 테이블을 만듭니다.
- 열 이름을 변경하고 테이블을 수정하여 원본과 다른 방식으로 데이터를 분석할 수 있도록 합니다.
- 다음 단계:
- 필터를 사용하여 2015년에 수익이 천만 달러 미만인 영화가 몇 편인지 확인합니다.
- 계산된 필드를 만들어 2015년 전체 영화 대비 수익이 천만 달러 미만인 영화의 백분율을 계산합니다.
5. 결론
- 피벗 테이블의 활용: 피벗 테이블을 통해 데이터를 효율적으로 요약하고 다양한 분석을 수행할 수 있습니다. 계산된 필드와 필터를 통해 더 깊이 있는 분석을 할 수 있으며, 이는 분석가가 데이터의 숨겨진 인사이트를 찾는 데 도움을 줍니다.
피벗 테이블 작업 2
1. 피벗 테이블 필터 적용
필터링 작업
- 목표: 2015년에 수익이 천만 달러 미만인 영화의 수를 확인합니다.
- 단계:
- 사본 피벗 테이블 선택: 피벗 테이블의 복사본에서 작업을 시작합니다.
- 필터 추가: 박스 오피스 수익 열에 필터를 추가합니다. 필터를 통해 조건을 설정하여 필요한 값만 표시할 수 있습니다.
- 필터 설정: 필터의 조건을 'Less than'으로 설정하고, 값으로 천만 달러를 입력합니다. 숫자를 달러와 센트 형식으로 입력하면 필터 조건이 데이터와 일치하도록 만들어 오류를 방지할 수 있습니다.
- 결과 확인: 2015년에 수익이 천만 달러 미만인 영화가 20편이라는 결과를 확인합니다. 이는 다른 해와 비교했을 때 상대적으로 높은 수치입니다.
2. 계산된 필드를 사용한 평균 수익 확인
계산된 필드 생성
- 목표: 수익이 천만 달러 미만인 영화의 평균 수익을 계산합니다.
- 단계:
- 계산된 필드 추가: 피벗 테이블에서 'Values as' 메뉴를 열고 'Calculated Field'를 선택하여 새로운 필드를 생성합니다.
- 수식 입력: 계산된 필드에 SUM 함수를 사용하여 원본 테이블의 박스 오피스 수익 데이터 합계를 사본 테이블의 데이터 수로 나누는 수식을 입력합니다. 이렇게 하면 필터링된 수익이 천만 달러 미만인 영화의 평균 수익만 반환됩니다.
- 정확성 확인: 수익 데이터의 정확성을 확인합니다.
3. 수익 백분율 계산
백분율 계산
- 목표: 연도별로 수익이 천만 달러 미만인 영화의 백분율을 계산합니다.
- 단계:
- 새 열 추가: 셀 G10에 'Percent of total movies'라는 이름의 새 열을 추가합니다.
- 수식 입력: 새 열에 수식을 추가하여 사본 테이블의 영화 수를 원본 테이블의 영화 수로 나누어 백분율을 계산합니다.
- 수식 적용: 채우기 핸들을 사용하여 나머지 연도에 수식을 적용합니다.
- 백분율 형식 설정: 결과 숫자의 형식을 백분율로 지정합니다.
분석 결과
- 2015년에 개봉한 영화의 16%가 수익이 천만 달러 미만이라는 결과를 확인합니다. 다른 연도는 모두 약 10%로 나타났습니다. 이 결과는 2015년의 평균 수익이 낮은 주요 원인 중 하나로 고려될 수 있습니다.
결론
- 피벗 테이블 활용: 피벗 테이블을 사용하면 데이터의 요약, 계산, 필터링을 효율적으로 수행할 수 있습니다.
- 실습의 중요성: 피벗 테이블, 함수, 수식을 반복적으로 연습하여 익숙해지면 분석 작업이 더 수월해질 것입니다.
분석을 위한 피벗 테이블 사용
이 읽기 자료에서는 데이터 분석을 위해 피벗 테이블을 만들고 사용하는 방법을 배웁니다. 피벗 테이블을 직접 만들 때 참고할 수 있도록 저장해둘 만한 피벗 테이블 관련 리소스도 제공됩니다. 피벗 테이블은 데이터를 다양한 방식으로 보면서 유용한 정보와 추세를 파악하는 데 도움이 되는 스프레드시트 도구입니다.
피벗 테이블을 사용하면 측정항목을 쉽게 비교하고, 계산을 빠르게 수행하고, 읽을 수 있는 보고서를 만들어 대규모 데이터 세트를 이해할 수 있습니다. 피벗 테이블을 만들어 데이터에 대한 특정 질문에 대한 답을 찾아보세요. 판매 데이터를 분석하는 경우 피벗 테이블을 사용하여 '가장 판매액이 높았던 달은 언제였나요?', '올해 최대 수익을 달성한 제품은 무엇인가요?'와 같은 질문에 답할 수 있습니다. 데이터에 관한 질문에 답해야 할 때 피벗 테이블을 사용하면 중요하지 않은 요소는 고려하지 않고 필요한 데이터에만 집중하는 데 도움이 됩니다.
피벗 테이블 생성
피벗 테이블로 데이터를 분석하려면 먼저 데이터로 피벗 테이블을 만들어야 합니다. 여기에서는 Google Sheets의 피벗 테이블을 만드는 단계를 알아보지만 대부분의 스프레드시트 프로그램에서 제공하는 도구도 이와 유사합니다.
우선 툴바에서 Data 메뉴를 열고 Pivot table 옵션을 찾습니다.
다음과 같은 팝업 메뉴가 표시됩니다.
새 시트를 선택하는 New sheet, 기존 시트를 선택하는 Existing sheet 옵션과 Create 버튼이 있습니다.
일반적으로 피벗 테이블을 위한 새 시트를 만들어서 원시 데이터와 분석 데이터를 구분하는 것이 좋습니다. 이렇게 하면 모든 계산 결과를 한 곳에 저장하여 참고하기도 쉽습니다. 피벗 테이블을 만들면 데이터 오른쪽에 Pivot table editor 패널이 표시됩니다.
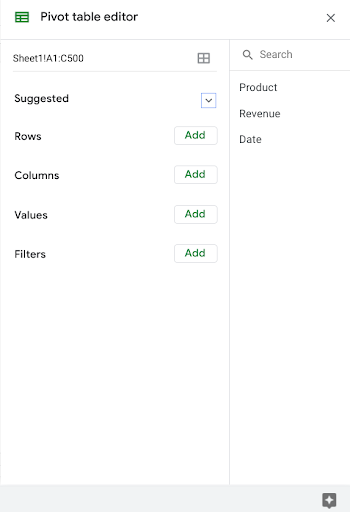
여기에서 분석에 포함할 변수를 선택하는 등 피벗 테이블을 맞춤설정할 수 있습니다.
분석을 위한 피벗 테이블 사용
피벗 테이블에서 데이터를 계산, 정렬, 필터링하는 등 다양한 분석 작업을 통해 유의미한 정보를 빠르게 도출할 수 있습니다. 다음은 피벗 테이블에서 기본적인 계산 방법과 데이터 정렬 및 필터링 방법을 알아보는 데 도움이 되는 온라인 리소스 목록입니다.
계산
| 피벗 테이블에서 값 계산: Excel 피벗 테이블 계산에 관한 Microsoft 지원의 기본 가이드입니다. Excel에서 피벗 테이블을 사용해 계산하는 기본 방법을 알아보는 데 유용합니다. | 피벗 테이블 만들기 및 사용하기: Google Sheets에서 피벗 테이블을 사용하는 방법을 중점적으로 다루며 계산된 필드를 만드는 방법을 설명하는 가이드입니다. 계산된 필드 추가 방법을 간단히 참고할 빠른 안내 가이드로 저장해놓으면 유용합니다. |
| Pivot table calculated field example: 피벗 테이블을 계산에 사용하는 예를 자세하게 확인할 수 있는 리소스입니다. 단계별 안내를 통해 계산된 필드의 작동 방식을 시연하고 이를 분석에 활용하는 몇 가지 아이디어를 제공합니다. | All about calculated field in pivot tables: Google Sheets의 계산된 필드에 관한 종합 가이드입니다. Sheets로 작업하면서 피벗 테이블에 관해 더 자세히 알고 싶은 경우 유용합니다. |
| 피벗 테이블 계산된 필드: 단계별 튜토리얼: 피벗 테이블에서 계산된 필드를 직접 만들어보는 튜토리얼입니다. 계산된 필드를 스프레드시트에 처음 적용할 때 참고할 수 있도록 저장하거나 북마크에 추가해놓으면 유용합니다. | Google Sheets의 피벗 테이블: Google Sheets의 피벗 테이블 및 계산된 필드 기본 내용을 소개하는 초보자용 가이드입니다. 예와 방법 안내 동영상을 사용하여 기본 개념을 시연합니다. |
데이터 정렬
| 피벗 테이블 또는 피벗 차트에서 데이터 정렬: 피벗 테이블에서 데이터를 정렬하는 방법에 관한 Microsoft 지원의 안내 가이드입니다. Excel로 작업하면서 Excel에서 필터링이 어떻게 표시되는지 확인하고 싶은 경우 유용합니다. | 피벗 테이블 맞춤설정하기: Google Sheets에서 피벗 테이블을 정렬하는 방법을 중점적으로 다루는 Google 지원 가이드입니다. Sheets에서 데이터 정렬 작업을 진행하고 단계별 안내가 필요한 경우 간편하게 참고하기에 유용합니다. |
| 피벗 테이블 - 데이터 정렬: 실제 데이터 예를 사용해 Excel에서 피벗 테이블을 정렬하는 방법을 시연하는 피벗 테이블 데이터 정렬 튜토리얼입니다. 데이터 정렬 작업을 처음부터 끝까지 연습해볼 수 있는 좋은 예가 제공됩니다. | 피벗 테이블 열 정렬 방법: 실제 데이터를 사용하여 Google Sheets 피벗 테이블의 정렬 과정을 시연하는 상세 가이드입니다. 실제 Sheets 환경의 스크린샷을 통해 더 자세한 안내가 필요한 경우 유용합니다. |
| How to sort a pivot table by value: 예를 사용하여 피벗 테이블에서 값을 기준으로 정렬하는 방법을 설명하는 리소스입니다. 동영상이 포함되어 있어 정렬 과정을 직접 보고 싶은 경우 유용합니다. | 피벗 테이블 오름차순 및 내림차순: 피벗 테이블의 정렬에 관해 빠르게 복습하고 싶은 경우 유용한 1분짜리 초보자용 가이드입니다. |
데이터 필터링
| 피벗 테이블의 데이터 필터링: Excel의 피벗 테이블에서 데이터를 필터링하는 방법을 설명하는 Microsoft 지원 페이지의 리소스입니다. Excel 스프레드시트로 작업하는 경우 간단히 참고할 수 있도록 북마크에 추가해놓으면 유용합니다. | 피벗 테이블 맞춤설정하기: 피벗 테이블 데이터 필터링 방법을 안내하는 Google 지원 페이지입니다. Google Sheets에서 피벗 테이블로 작업하면서 필터링 과정을 간단히 다시 살펴봐야 하는 경우 유용합니다. |
| How to filter Excel pivot table data: 데이터를 사용해 Excel 스프레드시트의 필터링 과정을 시연하는 피벗 테이블 데이터 필터링 안내 가이드입니다. 피벗 테이블의 필터링 도구를 직접 사용할 때 유용한 팁과 참고사항을 제공합니다. | 피벗 테이블에서 여러 값 필터링: Google Sheets 피벗 테이블에서 여러 값의 필터링 방법을 자세히 설명하는 가이드입니다. 일부 기능에 관해 이미 학습한 내용을 심화하여 Google Sheets에서 보다 복잡한 필터를 만드는 방법을 알아볼 수 있습니다. |
데이터 서식 지정
| 피벗 테이블의 레이아웃 및 서식 디자인: 사전 정의된 스타일, 줄무늬 행, 조건부 서식을 적용하여 피벗 테이블 서식을 변경하는 방법을 설명하는 Microsoft 지원 문서입니다. | 피벗 테이블 만들기 및 수정하기: 피벗 테이블을 편집하여 스타일을 변경하고 데이터를 그룹화하는 방법을 안내하는 고객센터 문서입니다. |
피벗 테이블은 빠르게 계산하고 작업 중인 스프레드시트 파일에서 데이터에 관한 유용한 정보를 바로 얻을 수 있는 강력한 도구입니다. 피벗 테이블 도구를 사용하여 데이터를 계산, 정렬, 필터링하면 즉시 데이터를 전반적으로 살펴보고 이해관계자에게 보고서를 제공할 수 있습니다.
SQL 계산 자세히 알아보기
쿼리 및 계산
1. 산술 연산자 비교
스프레드시트와 SQL에서의 기본 산술 연산자
- 덧셈 (+): 두 값을 더하는 연산자입니다.
- 스프레드시트: =A1 + B1
- SQL: SELECT columnA + columnB AS sum FROM table
- 뺄셈 (-): 두 값의 차를 계산합니다.
- 스프레드시트: =A1 - B1
- SQL: SELECT columnA - columnB AS difference FROM table
- 곱셈 (*): 두 값을 곱합니다.
- 스프레드시트: =A1 * B1
- SQL: SELECT columnA * columnB AS product FROM table
- 나눗셈 (/): 한 값을 다른 값으로 나눕니다.
- 스프레드시트: =A1 / B1
- SQL: SELECT columnA / columnB AS quotient FROM table
스프레드시트와 SQL에서 연산자의 사용
- 괄호 사용: 여러 연산자를 사용할 때 연산 순서를 지정할 수 있습니다.
- 스프레드시트: =(A1 + B1) * C1
- SQL: SELECT (columnA + columnB) * columnC AS result FROM table
- Modulo 연산자 (%): 나누기 연산의 나머지를 반환합니다.
- 스프레드시트: =MOD(A1, B1)
- SQL: SELECT columnA % columnB AS remainder FROM table
2. 집계 함수와 계산
집계 함수
- SUM: 모든 값을 더합니다.
- 스프레드시트: =SUM(A1:A10)
- SQL: SELECT SUM(columnA) AS total FROM table
- AVERAGE: 값의 평균을 계산합니다.
- 스프레드시트: =AVERAGE(A1:A10)
- SQL: SELECT AVG(columnA) AS average FROM table
집계 함수와 그룹화
- GROUP BY: 데이터의 특정 열을 기준으로 그룹화하여 집계 함수를 사용할 수 있습니다.
- SQL 예제: SELECT columnB, SUM(columnA) AS total FROM table GROUP BY columnB
- 이 쿼리는 columnB 값에 따라 그룹화하고, 각 그룹의 columnA 값을 합산하여 total로 반환합니다.
- SQL 예제: SELECT columnB, SUM(columnA) AS total FROM table GROUP BY columnB
3. SQL 계산의 기초
- 기본 쿼리 작성: SQL에서는 SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY 등의 구문을 사용하여 데이터를 조회하고 계산할 수 있습니다.
- 기본 쿼리 예제: SELECT columnA, columnB FROM table WHERE columnC > 100
- 이 쿼리는 columnC 값이 100보다 큰 행을 선택하고 columnA와 columnB 값을 반환합니다.
- 기본 쿼리 예제: SELECT columnA, columnB FROM table WHERE columnC > 100
- 계산된 필드: SQL에서 특정 계산을 수행하여 결과를 반환하는 새 열을 추가할 수 있습니다.
- 계산된 필드 예제: SELECT columnA, (columnB + columnC) AS total FROM table
- 이 쿼리는 columnB와 columnC의 합계를 total로 반환합니다.
- 계산된 필드 예제: SELECT columnA, (columnB + columnC) AS total FROM table
- 스프레드시트와 SQL의 유사점: 두 도구 모두 기본적인 산술 연산자와 집계 함수를 사용하여 데이터를 계산할 수 있습니다.
- 다양한 계산 방법: 스프레드시트에서는 셀에 직접 수식을 입력하고, SQL에서는 쿼리를 작성하여 데이터베이스에서 계산합니다.
- 연습의 중요성: 두 도구를 모두 활용하여 데이터 분석 작업을 효율적으로 수행할 수 있도록 연습하는 것이 중요합니다.
SQL에 간단한 계산 삽입
SQL에서의 계산 및 오류 처리
1. SQL 계산 기초
SQL에서는 계산을 쿼리 내에서 직접 수행할 수 있습니다. 이를 통해 분석 작업의 속도를 높일 수 있습니다. 기본적인 SQL 쿼리 구문은 다음과 같습니다:
- SELECT: 계산할 열과 연산자를 정의합니다.
- FROM: 데이터를 가져올 테이블을 지정합니다.
예시 쿼리:
sql
SELECT columnA + columnB AS Total
FROM tableName;이 쿼리는 columnA와 columnB의 합계를 계산하여 Total이라는 이름의 새 열로 반환합니다.
2. 예제: 아보카도 데이터
- 목표: 아보카도 판매 데이터에서 상자의 총합을 확인하고, 이를 검증하는 쿼리를 작성합니다.
쿼리 작성 과정:
- 열 선택:
sql
SELECT Date, Region, Small_Bags, Large_Bags, XLarge_Bags, Total_Bags
FROM avocado_data.avocado_prices;
계산 추가:
- 계산: 소형 상자, 대형 상자, 초대형 상자의 총합을 구합니다.
sql
SELECT Date, Region, Small_Bags, Large_Bags, XLarge_Bags,
Small_Bags + Large_Bags + XLarge_Bags AS Total_Bags_Calc
FROM avocado_data.avocado_prices;- 검증: Total_Bags와 Total_Bags_Calc 값을 비교하여 데이터가 정확한지 확인합니다.
3. 소형 상자의 백분율 계산
- 목표: 전체 상자 수에서 소형 상자의 백분율을 계산합니다.
쿼리 작성 과정:
- 열 선택 및 백분율 계산:
sql
SELECT Date, Region, Total_Bags, Small_Bags,
(Small_Bags / Total_Bags) * 100 AS Small_Bags_Percent
FROM avocado_data.avocado_prices;
오류 처리:
- 문제: Total_Bags가 0일 경우 나눗셈 오류 발생.
- 해결 방법: WHERE 절을 사용하여 Total_Bags가 0보다 큰 데이터만 포함합니다.
sql
SELECT Date, Region, Total_Bags, Small_Bags,
(Small_Bags / Total_Bags) * 100 AS Small_Bags_Percent
FROM avocado_data.avocado_prices
WHERE Total_Bags > 0;- 대안: SAFE_DIVIDE 함수를 사용하여 0으로 나눌 경우 NULL을 반환하도록 할 수 있습니다.
sql
SELECT Date, Region, Total_Bags, Small_Bags,
SAFE_DIVIDE(Small_Bags, Total_Bags) * 100 AS Small_Bags_Percent
FROM avocado_data.avocado_prices;4. SQL의 유연성
SQL은 다양한 계산과 분석을 쿼리 내에서 수행할 수 있으며, 쿼리에 계산을 포함하면 분석 과정에서 즉시 결과를 얻을 수 있습니다. 이는 분석 작업을 더 효율적으로 수행할 수 있도록 도와줍니다.
다른 문으로 계산
SQL에서 데이터 그룹화 및 집계 함수 사용
1. 데이터 그룹화
SQL에서는 GROUP BY 명령어를 사용하여 데이터를 그룹화할 수 있습니다. 이는 동일한 값을 가진 행들을 집계하여 요약된 결과를 얻는 데 유용합니다. GROUP BY는 SELECT 문과 함께 사용되며, 보통 SUM, COUNT와 같은 집계 함수와 함께 사용됩니다.
2. GROUP BY 명령어 사용 예제
목표: 연간 자전거 타기 횟수를 계산하고 요약하기
- 쿼리 작성:
- 데이터 선택: starttime 열에서 연도별로 자전거 타기 횟수를 계산합니다.
- 집계 함수 사용: COUNT 함수를 사용하여 자전거 타기 횟수를 집계합니다.
쿼리 구문:
sql
SELECT EXTRACT(YEAR FROM starttime) AS year,
COUNT(*) AS number_of_rides
FROM bigquery-public-data.new_york.citybike_trips
GROUP BY year
ORDER BY year;- EXTRACT(YEAR FROM starttime)는 starttime 열에서 연도를 추출합니다.
- COUNT(*)는 모든 자전거 타기 기록의 개수를 계산합니다.
- GROUP BY year는 데이터를 연도별로 그룹화합니다.
- ORDER BY year는 결과를 연도별로 정렬합니다. 기본적으로 오름차순으로 정렬되며, 내림차순으로 정렬하려면 DESC를 추가합니다.
3. 내림차순 정렬
쿼리 수정:
sql
ORDER BY year DESC;
- GROUP BY와 ORDER BY 명령어는 데이터를 그룹화하고 정렬하여 분석을 보다 용이하게 합니다.
- GROUP BY는 데이터를 집계할 때 필요한 집계 함수와 함께 사용되며, ORDER BY는 결과를 정렬합니다.
데이터 검증 과정
확인과 재확인
데이터 검증의 중요성과 방법
1. 데이터 검증의 정의
- 데이터 검증은 데이터의 완전성, 정확성, 보안성, 일관성을 확인하는 과정입니다.
- 비즈니스 목표와 데이터의 정합성을 확인하기 위해 데이터가 타당한지 검토하는 작업입니다.
2. 데이터 검증 과정
- 비즈니스 지식 활용: 비즈니스의 특정 요구사항이나 특성을 이해하여 데이터가 이를 충족하는지 확인합니다.
- 계산 검증: 데이터의 계산이 정확한지 확인합니다. 예를 들어, 판매 가격이 판매 수량과 제품 가격의 곱과 일치하는지 검토합니다.
- 데이터 일관성: 데이터에 있는 값이 예상과 일치하는지 검토합니다. 예를 들어, 할인 적용이 제대로 이루어졌는지 확인합니다.
- 주말 데이터 검토: 비즈니스 운영 일자에 따라 데이터가 일치하는지 확인합니다. 주말에 매출이 없는 것이 정상인지 검토합니다.
3. SQL에서 데이터 검증
- 예제 1: 아보카도 데이터 검증
- 목표: 'Total_Bags' 열의 값이 소형, 대형, 초대형 상자 수의 합과 같은지 확인
쿼리 예제:
sql
SELECT *
FROM avocado_data.avocado_prices
WHERE Total_Bags != (Small_Bags + Large_Bags + XLarge_Bags);-
- 설명: 이 쿼리는 계산된 총계와 'Total_Bags' 열의 값이 일치하지 않는 경우를 반환합니다. 반환값이 없다면 데이터가 정확하다고 가정할 수 있습니다.
- 예제 2: 백분율 계산 오류 처리
- 문제: 0으로 나눌 수 없다는 오류 발생
해결 방법:
sql
SELECT Date, Region, Total_Bags, Small_Bags,
(CASE WHEN Total_Bags != 0
THEN (Small_Bags / Total_Bags) * 100
ELSE 0
END) AS Small_Bags_Percent
FROM avocado_data.avocado_prices
WHERE Total_Bags != 0;-
- 설명: 이 쿼리는 CASE 문을 사용하여 Total_Bags가 0이 아닐 때만 백분율을 계산하고, 그렇지 않을 경우 0으로 설정합니다.
4. 데이터 검증의 가치
- 오류 예방: 분석 결과의 정확성을 높이고, 비즈니스 목표를 달성하는 데 중요한 역할을 합니다.
- 신뢰성 확보: 데이터가 올바르게 검증되면, 분석 결과에 대한 신뢰를 얻을 수 있습니다.
- 데이터 검증은 단순한 데이터 정리 작업을 넘어, 데이터 분석의 신뢰성을 높이는 중요한 과정입니다.
- 다양한 검증 방법을 통해 데이터의 정확성을 확인하고, 분석 결과를 기반으로 올바른 비즈니스 결정을 내릴 수 있습니다.
데이터 검증 종류
다음 표는 데이터 검증 6가지의 목표, 예, 한계를 설명합니다. 첫 5가지는 데이터와 관련된 검증(유형, 범위, 제약 조건, 일관성, 구조)이며 여섯 번째는 사용자 데이터 입력을 통해 데이터를 받아들이는 데 사용된 애플리케이션 코드를 검증하는 데 집중합니다.
주니어 데이터 애널리스트가 6가지 검증을 모두 진행하는 경우는 사실 드뭅니다. 그러나 여러분은 데이터 세트로 작업하기 전에 데이터의 검증 여부와 방법에 대해 질문해보실 수 있습니다. 데이터 검증은 데이터의 무결성을 보장하는 데 도움이 됩니다. 또한 사용 중인 데이터가 클린 데이터임을 확신할 수 있습니다. 다음 목록에서 데이터 검증 6가지와 각각의 목적, 예, 한계를 확인해보세요.

1. 데이터 유형
- 목적: 데이터가 필드에 정의된 데이터 유형과 일치하는지 확인합니다.
- 예: 1~12학년의 데이터 값은 수치 데이터 유형이어야 합니다.
- 한계: 데이터 값 13은 허용되지 않는 값임에도 데이터 유형 검증을 통과합니다. 이 경우 데이터 범위 검증도 필요합니다.

2. 데이터 범위
- 목적: 데이터가 필드에 정의된 값 허용 범위 내에 있는지 확인합니다.
- 예: 학년 데이터 값은 1에서 12 사이여야 합니다.
- 한계: 데이터 값 11.5는 데이터 범위 내에 있으며 수치 데이터 유형이므로 검증을 통과합니다. 그러나 0.5학년은 없기 때문에 허용해서는 안 되는 값입니다. 이 경우 데이터 제약 조건 검증도 필요합니다.

3. 데이터 제약 조건
- 목적: 데이터가 필드의 특정 조건이나 기준을 충족하는지 확인합니다. 조건이나 기준에는 입력된 데이터 유형 및 필드의 기타 속성(예: 문자 수) 등이 포함됩니다.
- 예: 콘텐츠 제약 조건 - 1~12학년의 데이터 값은 정수여야 합니다.
- 한계: 데이터 값 13은 정수이므로 콘텐츠 제약 조건 검증을 통과합니다. 그러나 13학년은 없기 때문에 허용해서는 안 되는 값입니다. 이 경우 데이터 범위 검증도 필요합니다.

4. 데이터 일관성
- 목적: 데이터가 다른 관련 데이터와의 맥락에서 타당한지 확인합니다.
- 예: 제품 배송 날짜의 데이터 값은 제품 생산 날짜 이전일 수 없습니다.
- 한계: 데이터가 일관되더라도 올바르지 않거나 부정확할 수 있습니다. 배송 날짜가 생산 날짜 이후더라도 잘못된 날짜일 가능성이 있습니다.

5. 데이터 구조
- 목적: 데이터가 정해진 구조를 따르는지 확인합니다.
- 예: 웹페이지는 정해진 구조를 따라 적절하게 표시되어야 합니다.
- 한계: 데이터 구조가 올바르더라도 데이터는 올바르지 않거나 부정확할 수 있습니다. 웹페이지의 콘텐츠가 적절하게 표시되더라도 잘못된 정보가 포함됐을 가능성이 있습니다.

6. 코드 검증
- 목적: 사용자 데이터 입력 중에 애플리케이션 코드가 위에 언급된 데이터 검증을 체계적으로 수행하는지 확인합니다.
- 예: 코드 검증에서 흔히 발견되는 문제로는 두 가지 이상의 데이터 유형이 허용되거나, 데이터 범위 확인이 이루어지지 않거나, 텍스트 문자열의 끝이 제대로 정의되지 않는 경우가 있습니다.
- 한계: 코드 검증이 데이터 입력의 변형 사례를 모두 검증한다고 보장할 수 없습니다.
SQL의 임시 테이블 사용
임시 테이블
임시 테이블 소개
임시 테이블은 SQL에서 일시적으로 생성되어 사용하는 테이블로, 데이터베이스 세션이 끝나면 자동으로 삭제됩니다. 이러한 임시 테이블은 주로 다음과 같은 상황에서 유용하게 사용됩니다:
- 다중 테이블 결합:
- 여러 개의 테이블을 결합하여 처리해야 할 때, 중간 결과를 임시 테이블에 저장하고 이후에 필요한 테이블과 결합하여 최종 결과를 생성합니다.
- 데이터 필터링:
- 반복적으로 필터링해야 할 데이터가 있을 때, 처음에 한 번만 필터링하여 임시 테이블에 저장하고 이를 바탕으로 추가적인 쿼리를 실행합니다.
- 쿼리 성능 개선:
- 복잡한 쿼리를 여러 번 실행해야 할 때, 중간 결과를 임시 테이블에 저장함으로써 쿼리 성능을 개선할 수 있습니다.
임시 테이블 사용 예시
1. 임시 테이블 생성
BigQuery에서 임시 테이블을 생성하려면 WITH 절을 사용합니다. 이 절은 서브쿼리의 결과를 임시 테이블처럼 활용할 수 있게 해줍니다.
예를 들어, 자전거 주행 데이터에서 60분 이상의 주행만 필터링하여 분석할 때 임시 테이블을 사용할 수 있습니다.
sql
WITH trips_over_1_hr AS (
SELECT *
FROM bigquery-public-data.new_york.citibike_trips
WHERE tripduration >= 60
)- WITH 명령어를 사용하여 trips_over_1_hr라는 이름의 임시 테이블을 생성합니다.
- AS 뒤에 서브쿼리를 작성하여 조건에 맞는 데이터를 필터링합니다.
2. 임시 테이블에서 쿼리 실행
임시 테이블이 생성되면, 이후 쿼리에서 이 임시 테이블을 사용할 수 있습니다. 예를 들어, 60분 이상의 자전거 주행 수를 계산하려면 다음과 같이 쿼리를 작성합니다.
sql
SELECT COUNT(*) AS cnt
FROM trips_over_1_hr- SELECT COUNT(*)를 사용하여 60분 이상의 자전거 주행 수를 계산합니다.
- FROM trips_over_1_hr로 임시 테이블에서 데이터를 가져옵니다.
임시 테이블 사용의 장점
- 효율성:
- 복잡한 계산이나 데이터 필터링을 임시 테이블에 저장하고 이후 쿼리에서 재사용함으로써 성능을 향상시킵니다.
- 코드 가독성:
- 쿼리의 가독성을 높이고, 중간 결과를 저장하여 쿼리를 더 명확하게 작성할 수 있습니다.
- 협업 용이성:
- 팀원들과 협업할 때, 복잡한 쿼리를 단순화하고 중간 결과를 공유함으로써 분석 작업이 더 효율적이고 명확하게 이루어질 수 있습니다.
임시 테이블 활용 예시
자전거 공유 데이터베이스에서 60분 이상의 자전거 주행을 분석한다고 가정해 보겠습니다. 다음은 임시 테이블을 활용한 쿼리의 전체 과정입니다.
- 임시 테이블 생성:
sql
WITH trips_over_1_hr AS (
SELECT *
FROM bigquery-public-data.new_york.citibike_trips
WHERE tripduration >= 60
)
- 임시 테이블에서 데이터 계산:
sql
SELECT COUNT(*) AS cnt
FROM trips_over_1_hr
임시 테이블을 활용하면, 복잡한 데이터 분석 작업을 더 체계적이고 효율적으로 진행할 수 있습니다. 데이터 애널리스트로서 이러한 기법을 익히고 활용하면, 데이터 처리와 분석의 품질을 높일 수 있습니다.
다수의 테이블 변수
임시 테이블 생성 방법
1. WITH 절 사용하기
- 설명: WITH 절은 쿼리 내에서 일시적인 서브쿼리를 정의하고 이 서브쿼리의 결과를 임시 테이블처럼 사용할 수 있게 해줍니다.
- 장점:
- 쿼리가 간결해지고 가독성이 높아집니다.
- 임시 테이블을 사용하는 쿼리와 함께 작성되므로 데이터베이스에 추가적인 테이블을 만들지 않습니다.
- 단점:
- SQL 세션이 종료되면 임시 테이블이 사라집니다.
- 특정 RDBMS에서는 지원되지 않을 수 있습니다 (예: BigQuery).
예시:
sql
WITH trips_over_1_hr AS (
SELECT *
FROM bigquery-public-data.new_york.citibike_trips
WHERE tripduration >= 60
)
SELECT COUNT(*) AS cnt
FROM trips_over_1_hr2. SELECT INTO 문 사용하기
- 설명: SELECT INTO 문은 기존 테이블의 데이터를 새 테이블로 복사하여 임시 테이블을 생성합니다. 새 테이블은 데이터베이스에 추가되지 않습니다.
- 장점:
- 특정 조건을 만족하는 데이터의 테이블 사본을 쉽게 생성할 수 있습니다.
- 데이터베이스를 깔끔하게 유지할 수 있습니다.
- 단점:
- BigQuery와 같은 일부 RDBMS에서는 SELECT INTO를 지원하지 않습니다.
- 새 테이블이 데이터베이스에 추가되지 않으므로, 테이블을 공유할 필요가 있는 경우에는 다른 방법이 필요합니다.
예시:
sql
SELECT *
INTO AfricaSales
FROM GlobalSales
WHERE Region = 'Africa'3. CREATE TABLE 문 사용하기
- 설명: CREATE TABLE 문을 사용하여 데이터베이스에 새로운 테이블을 추가하고, SELECT 쿼리를 통해 데이터를 삽입할 수 있습니다.
- 장점:
- 테이블을 데이터베이스에 추가하여 다른 사용자와 공유할 수 있습니다.
- 복잡한 테이블 구조나 메타데이터를 포함할 수 있습니다.
- 단점:
- 데이터베이스에 새 테이블이 추가되므로, 관리와 유지보수가 필요합니다.
- 임시 테이블이 아니므로, 사용 후 삭제해야 할 필요가 있습니다.
예시:
sql
CREATE TABLE AfricaSales AS
SELECT *
FROM GlobalSales
WHERE Region = 'Africa'4. CREATE TEMP TABLE 문 사용하기
- 설명: CREATE TEMP TABLE 문은 임시 테이블을 생성하며, 이 테이블은 세션이 종료될 때 자동으로 삭제됩니다.
- 장점:
- 임시 테이블을 데이터베이스에 추가하지 않고, 세션 동안만 유지됩니다.
- 복잡한 쿼리나 중간 결과를 저장하는 데 유용합니다.
- 단점:
- 특정 RDBMS에서만 지원될 수 있습니다.
- 데이터베이스가 아닌 세션 기반으로 테이블을 사용하므로, 데이터베이스에 저장된 테이블과는 구분됩니다.
예시:
sql
CREATE TEMP TABLE TempSales AS
SELECT *
FROM GlobalSales
WHERE Region = 'Africa'임시 테이블 선택 시 고려사항
- 목표에 맞는 선택:
- 데이터베이스에 테이블을 추가할 필요가 있는지, 아니면 세션 동안만 사용해야 하는지를 고려하여 적절한 방법을 선택합니다.
- 쿼리의 복잡성:
- 임시 테이블을 사용하는 쿼리의 복잡성을 줄이기 위해 WITH 절을 사용할 수 있습니다.
- RDBMS의 지원 여부:
- 사용하는 데이터베이스 시스템에서 지원하는 구문을 확인하고, 필요한 경우 온라인 검색을 통해 정보를 찾습니다.
임시 테이블은 데이터 분석의 중요한 도구로, 다양한 방법으로 생성할 수 있습니다. 각 방법의 장단점을 이해하고, 상황에 맞게 적절한 방법을 선택하는 것이 중요합니다. 데이터 애널리틱스 작업을 진행할 때 이러한 다양한 기법을 잘 활용하면 더 효율적이고 효과적인 분석이 가능해집니다.
임시 테이블 작업
임시 테이블은 이름 그대로 영구적으로 저장되지 않는 SQL 데이터베이스의 임시 테이블입니다. 이 읽기 자료에서는 SQL 명령어를 사용하여 임시 테이블을 생성하는 방법을 배웁니다. 임시 테이블 작업을 위한 몇 가지 권장사항도 학습합니다.
임시 테이블 복습
- 임시 테이블은 SQL 세션 종료 시 데이터베이스에서 자동으로 삭제됩니다.
- 임시 테이블은 일련의 계산을 수행할 때 값을 저장하는 보관 영역으로 사용할 수 있으며, 이는 데이터 전처리라고도 합니다.
- 임시 테이블은 각기 다른 여러 쿼리의 결과를 수집할 수 있으며, 이는 데이터 스테이징이라고도 합니다. 스테이징은 수집된 데이터를 쿼리하거나 병합해야 할 때 유용합니다.
- 임시 테이블은 데이터베이스의 필터링된 하위 세트를 저장할 수 있습니다. 작업할 때마다 매번 데이터를 선택하고 필터링할 필요가 없습니다. 또한 SQL 명령을 적게 사용하여 데이터를 정리된 상태로 유지하는 데 도움이 됩니다.
데이터베이스마다 임시 테이블을 만들고 관리하기 위한 저마다의 명령어 세트가 있다는 점이 중요합니다. 이 강좌에서는 BigQuery로 작업하고 있으므로 BigQuery 환경에서 잘 작동하는 명령어를 자세히 알아봅니다. 여기서부터는 BigQuery를 위주로 임시 테이블을 생성하는 방법을 살펴봅니다.

BigQuery에서 임시 테이블 생성
임시 테이블은 다양한 절을 사용해 만들 수 있습니다. BigQuery에서는 WITH 절을 사용하여 임시 테이블을 만듭니다. 이 메서드의 일반적인 구문은 다음과 같습니다.
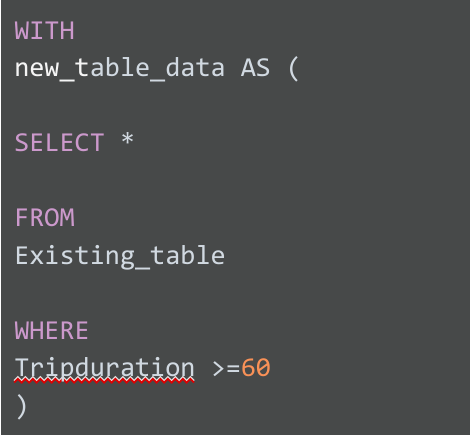
이 쿼리를 해석하면 다음과 같습니다.
- 이 문은 WITH 절로 시작하며, 그 뒤로 생성할 새 임시 테이블의 이름이 이어집니다.
- 새 테이블 이름 뒤에는 AS 절이 있습니다. 이 절은 문의 다음 부분에서 식별된 데이터를 전부 새 테이블에 넣도록 지정합니다.
- AS 절 뒤에 괄호를 열어 기존 테이블에서 데이터를 필터링하는 서브쿼리를 시작합니다. 서브쿼리는 일반 SELECT 문이며 필터링할 데이터를 지정하는 WHERE 절도 나옵니다.
- 괄호를 닫아 AS 절로 생성된 서브쿼리를 끝냅니다.
데이터베이스가 이 쿼리를 실행하면 먼저 서브쿼리를 완료한 뒤 서브쿼리의 결과 값을 임시 테이블인 'new_table_data'로 할당합니다. 매번 데이터를 필터링할 필요 없이 이미 필터링된 데이터로 여러 쿼리를 실행할 수 있습니다.
다른 데이터베이스에서 임시 테이블 생성(BigQuery에서는 지원되지 않음)
다음 메서드는 BigQuery에서 지원되지 않지만 SQL Server와 mySQL 등 대부분의 SQL 데이터베이스 버전에서 지원됩니다. SELECT 및 INTO를 사용하면 임시 테이블에 필요한 정보의 위치를 지정하는 WHERE 절에서 정의된 조건을 기반으로 임시 테이블을 만들 수 있습니다. 이 메서드의 일반적인 구문은 다음과 같습니다.

SELECT * INTO AfricaSales FROM GlobalSales WHERE Region = "Africa"
이 SELECT 문은 FROM, WHERE 등 일반 절을 사용하며, INTO 절은 요청된 데이터를 'AfricaSales'라는 이름의 새 임시 테이블에 저장하도록 지정합니다.
사용자 관리형 임시 테이블 생성
지금까지 데이터베이스가 관리하는 임시 테이블 생성 방법을 알아봤습니다. 그러나 사용자가 관리하는 임시 테이블도 만들 수 있습니다. 애널리스트가 분석을 위해 직접 관리 가능한 임시 테이블을 만들어야 하는 경우도 있습니다. 사용자가 관리하는 임시 테이블은 CREATE TABLE 문을 사용하여 만듭니다. 테이블 작업을 마친 뒤에는 세션 종료 시 해당 테이블을 데이터베이스에서 직접 삭제하거나 드롭합니다.
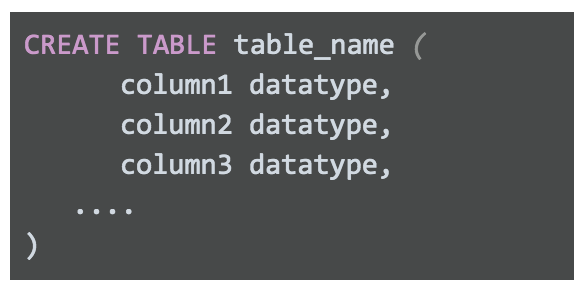
CREATE TABLE table_name ( column1 datatype, column2 datatype, column3 datatype, .... )
임시 테이블 작업을 마친 뒤에는 DROP TABLE 절을 사용하여 데이터베이스에서 테이블을 삭제합니다. 일반적인 구문은 다음과 같습니다.

임시 테이블 작업을 위한 권장사항
- 글로벌 임시 테이블과 로컬 임시 테이블 비교: 글로벌 임시 테이블은 모든 데이터베이스 사용자에게 공개되며, 임시 테이블을 사용하는 모든 연결이 해제되면 삭제됩니다. 로컬 임시 테이블은 쿼리 또는 연결을 통해 임시 테이블을 구성한 사용자에게만 공개됩니다. 대부분의 경우 로컬 임시 테이블로 작업하게 됩니다. 로컬 임시 테이블을 만들어 혼자 사용하는 경우 사용을 마친 뒤 임시 테이블을 드롭합니다.
- 사용 후 임시 테이블 드롭: 임시 테이블 드롭은 임시 테이블 삭제와 약간 다릅니다. 임시 테이블을 드롭하면 테이블 행에 있는 정보뿐 아니라 테이블 변수 정의(열) 자체가 삭제됩니다. 임시 테이블을 삭제하면 테이블 행이 삭제되지만 테이블 정의와 열은 남아 있으므로 다시 사용할 수 있습니다. SQL 세션을 종료하면 로컬 임시 테이블이 드롭되지만, 즉시 드롭되지 않을 수도 있습니다. 임시 테이블을 사용한 뒤에 드롭하는 습관을 갖추면 데이터베이스의 처리량이 많은 경우 데이터베이스가 원활하게 실행되는 데 도움이 됩니다.
추가 정보
- 임시 테이블에 관한 BigQuery 문서: BigQuery에서 임시 테이블을 만드는 구문을 설명하는 문서
- Google BigQuery에서 WITH로 임시 테이블을 사용하는 방법: WITH 사용법을 설명하는 문서
- Introduction to Temporary Tables in SQL Server: SELECT INTO 및 CREATE TABLE 사용법을 설명하는 문서
- SQL Server Temporary Tables: 임시 테이블 생성 및 삭제에 관해 설명하는 문서
- Choosing Between Table Variables and Temporary Tables: SQL 문에서 변수 전달과 임시 테이블 사용 사이의 차이를 설명하는 문서