2024. 9. 12. 12:33ㆍGCC/데이터 애널리틱스

VLOOKUP으로 데이터 집계
분석을 위한 데이터 집계
데이터 집계 및 집계의 중요성
데이터 집계란 여러 개별 데이터를 수집하거나 모아서 하나의 완전한 데이터로 결합하는 과정입니다. 쉽게 말해, 여러 조각의 데이터를 하나의 큰 그림으로 만드는 작업입니다.
1. 집계의 개념
- 집계란 단어는 여러 요소를 모아 하나의 집합체로 만드는 과정을 의미합니다. 예를 들어, 은하수는 별, 먼지, 가스가 모여 이루어진 집합체입니다. 마찬가지로, 데이터 집계는 서로 다른 데이터 소스에서 데이터를 모아서, 하나의 요약된 데이터 모음으로 결합하는 것을 말합니다.
2. 데이터 집계의 예시
- 퍼즐 예시: 캐비닛에 여러 개의 퍼즐이 들어있는 상자들이 있다고 가정해 봅시다. 어느 날 선반이 부서지면서 퍼즐 상자들이 넘어지고, 퍼즐 조각들이 사방으로 흩어집니다. 이 상황에서 다시 퍼즐을 정리하려면 각 퍼즐 조각들을 구분하고, 그 조각들을 알맞은 상자에 다시 넣어야 합니다. 이처럼 퍼즐 조각을 모아 하나로 만드는 과정이 바로 데이터 집계 과정과 유사합니다.
- 퍼즐 조각이 흩어진 상황에서 개별 조각들은 의미가 없지만, 각 퍼즐을 다시 모아 하나의 완전한 그림으로 만들 수 있듯이, 데이터를 집계하면 유의미한 통찰을 얻을 수 있습니다. 퍼즐 조각이 여러 데이터 세트를 나타낸다면, 퍼즐을 완성하는 과정은 데이터 분석을 통한 인사이트 도출에 해당합니다.
3. 데이터 집계의 중요성
- 데이터 집계는 데이터 애널리스트가 데이터를 분석해 추세를 파악하고, 비교하며, 유용한 정보를 얻는 데 매우 중요한 과정입니다. 개별 데이터를 분석하는 것만으로는 이러한 통찰을 얻기 어렵지만, 데이터를 집계하면 전반적인 패턴을 볼 수 있습니다.
- 졸업률 예시: 개별 학생들의 졸업 데이터를 집계하여 학급 전체의 졸업률을 계산할 수 있습니다. 또한 이 데이터를 더 크게 집계하여 지역, 주, 국가 단위의 졸업률을 확인할 수도 있습니다. 이렇게 집계된 데이터는 정책 수립 등에서 중요한 지표로 활용될 수 있습니다.
4. 데이터 집계를 통한 통계적 분석
- 데이터를 집계하면 여러 가지 통계적 지표를 구할 수 있습니다. 예를 들어, 주어진 기간 동안 데이터를 집계하여 평균, 최솟값, 최댓값, 합계 등의 통계 지표를 도출할 수 있습니다.
- 부동산 예시: 지난 10년간 특정 지역의 부동산 판매 데이터를 집계하면 해당 지역의 평균 주택 가격을 알 수 있고, 시간이 지남에 따라 주택 가격이 어떻게 변동했는지 파악할 수 있습니다.
5. 집계에 도움이 되는 함수
- 데이터를 집계할 때 함수는 매우 유용한 도구입니다. 가장 일반적인 함수를 사용해 데이터를 요약할 수 있으며, 이를 통해 필요한 통계 정보를 빠르게 도출할 수 있습니다.
- 서브쿼리 사용: 데이터를 집계할 때 서브쿼리를 활용하는 방법도 배울 것입니다. 서브쿼리는 다른 쿼리 내에 포함된 쿼리로, 내부 쿼리 또는 중첩 쿼리라고도 불립니다. 서브쿼리는 복잡한 데이터 분석에서 필수적인 도구로, SQL에서 데이터를 효율적으로 집계하는 데 사용됩니다.
VLOOKUP 준비
VLOOKUP을 사용하기 전에 데이터 준비하기
데이터 집계 도구인 VLOOKUP을 사용하기 전에 데이터를 적절히 준비하는 방법에 대해 알아보겠습니다. 데이터 집계란 여러 소스에서 데이터를 모아 하나의 요약된 형태로 결합하는 과정입니다. 집계된 데이터는 마케팅, 가격 책정, 광고 성과 분석 등 다양한 비즈니스 의사결정에 중요한 정보를 제공합니다.
1. VLOOKUP의 개념
- VLOOKUP은 "세로 방향 조회"라는 뜻으로, 열에서 특정 값을 검색하여 해당 값과 일치하는 정보를 반환하는 함수입니다.
- 예를 들어, 한 스프레드시트에서 제품 코드를 입력하고, 다른 스프레드시트에 저장된 제품명과 일치시킬 때 VLOOKUP을 사용할 수 있습니다.
- 하지만 이 작업을 수행하기 전에 데이터를 클린 데이터로 정리하는 것이 매우 중요합니다. 클린 데이터는 정확하고 오류 없는 결과를 제공하기 때문입니다.
2. 데이터 정리의 중요성
- 클린 데이터는 데이터 집계와 분석의 핵심입니다. 데이터 형식이 잘못되었거나 일관성이 없는 경우, VLOOKUP은 오류를 반환할 수 있습니다. 따라서, 데이터를 정리하는 작업은 매우 중요합니다.
- 데이터 정리 대상: 스프레드시트의 데이터가 일관성 있게 정리되어 있어야 하며, 숫자 형식이 올바르게 설정되어 있어야 합니다. 예를 들어, 날짜가 숫자 형식으로 되어 있지 않거나, 숫자가 텍스트 형식으로 저장된 경우가 있을 수 있습니다. 이러한 문제는 VLOOKUP에서 오류를 발생시킬 수 있습니다.
3. 데이터 정리 방법
- 텍스트를 수치로 변환하기
- 데이터를 정리할 때 VALUE 함수를 사용하여 텍스트 형식의 숫자를 수치로 변환할 수 있습니다.
- 예시: A열에 숫자가 있지만, 텍스트 형식으로 저장된 경우, 간단한 SUM 함수를 실행해도 0이라는 결과가 나옵니다. 이는 텍스트로 된 숫자가 더해지지 않기 때문입니다.
- 이때 VALUE 함수를 사용하면, 텍스트를 수치로 변환할 수 있습니다. 예를 들어 =VALUE(A2)와 같이 입력하면, 텍스트로 저장된 숫자가 올바른 수치로 변환됩니다. 변환된 값을 확인한 후 SUM 함수를 다시 실행하면 제대로 된 합계를 구할 수 있습니다.
- 공백 제거하기
- 데이터를 복사해서 붙여넣을 때, 추가 공백이 포함되는 경우가 있습니다. 이때 VLOOKUP은 데이터를 찾지 못할 수 있습니다.
- 이를 해결하기 위해 TRIM 함수를 사용하여 불필요한 공백을 자동으로 제거할 수 있습니다. TRIM은 셀의 앞뒤 공백을 제거하여 데이터를 정리하는 유용한 도구입니다.
- 중복 제거하기
- VLOOKUP에서 중복된 데이터가 있으면, 첫 번째로 발견된 값만 반환하기 때문에, 중복 데이터가 문제를 일으킬 수 있습니다.
- 중복된 데이터를 제거하려면, 스프레드시트의 중복 삭제 도구를 사용하면 됩니다. 중복 항목을 자동으로 검색하고 삭제하여, 올바른 데이터를 찾아 VLOOKUP이 정확하게 동작하도록 할 수 있습니다.
4. VLOOKUP 사용 전 클린 데이터의 중요성
- 클린 데이터는 데이터 정리, 집계, 분석의 기초입니다. 데이터를 정리함으로써 VLOOKUP은 보다 정확한 결과를 제공할 수 있습니다.
VLOOKUP 실행
1. VLOOKUP의 개요
- VLOOKUP은 스프레드시트에서 특정 값을 세로 방향으로 검색하여 일치하는 데이터를 반환하는 함수입니다. 주로 서로 다른 시트나 테이블 간의 데이터를 연결하는 데 사용됩니다.
2. VLOOKUP 구문
기본 VLOOKUP 함수는 다음과 같은 구문을 따릅니다:
scss
VLOOKUP(검색할 값, 검색 범위, 열 번호, [정확한 일치 여부])
- 검색할 값: 찾고자 하는 데이터입니다.
- 검색 범위: 데이터를 검색할 범위로, 첫 번째 열에 검색할 값이 있어야 합니다.
- 열 번호: 검색 범위에서 반환할 값이 있는 열의 번호입니다.
- 정확한 일치 여부: TRUE는 근사값, FALSE는 정확한 일치를 찾습니다.
예를 들어, VLOOKUP(103, A2:B26, 2, FALSE)에서:
- 103은 검색할 값,
- A2은 검색 범위,
- 2는 검색 범위 내에서 값을 반환할 열 번호이며,
- FALSE는 정확한 일치만 반환하라는 의미입니다.
3. VLOOKUP을 활용한 데이터 연결
VLOOKUP은 두 개의 스프레드시트를 연결하여 데이터를 결합하는 데 매우 유용합니다. 예를 들어, 직원의 ID 번호와 급여율이 각각 다른 스프레드시트에 있을 때, VLOOKUP을 사용하여 두 데이터를 결합할 수 있습니다.
예제:
- 첫 번째 스프레드시트 'Employee Hours'에는 직원 ID와 근무 시간이 있습니다.
- 두 번째 스프레드시트 'Employee Rates'에는 직원 ID와 급여율이 있습니다.
여기서 VLOOKUP을 사용하여 'Employee Hours'에 급여율을 추가하고, 이를 통해 직원별 급여를 계산해보겠습니다.
4. VLOOKUP 수식 작성
- VLOOKUP 함수 입력: =VLOOKUP(A2, 'Employee Rates'!A2:B5, 2, FALSE)
- A2: 'Employee Hours'에서 첫 번째 직원의 ID 번호입니다.
- 'Employee Rates'!A2: 다른 스프레드시트에서 검색할 범위입니다. 'Employee Rates' 시트의 A2에서 B5까지의 범위를 지정합니다.
- 2: 두 번째 열, 즉 급여율을 반환할 열 번호입니다.
- FALSE: 정확한 일치 항목을 반환하도록 지정합니다.
- 절대 셀 참조 사용: 수식을 복사할 때 참조하는 셀 범위가 변경되지 않도록 절대 참조를 설정할 수 있습니다. 예를 들어, A2:B5 대신 $A$2:$B$5로 작성하면, 복사 시 참조 범위가 고정됩니다.
- 수식 복사: 작성한 VLOOKUP 수식을 열 아래로 드래그하여 나머지 직원들의 급여율을 자동으로 채울 수 있습니다.
5. 급여 계산
급여율을 추가한 후, 간단한 곱셈 공식을 사용하여 각 직원의 급여를 계산할 수 있습니다:
- =근무 시간 * 급여율
이렇게 하면, 각 직원별로 근무 시간에 따른 급여가 자동으로 계산됩니다.
VLOOKUP을 사용하여 두 개의 스프레드시트 간 데이터를 연결하고, 이를 통해 직원별 급여를 계산하는 방법을 배웠습니다. VLOOKUP은 복잡한 함수이기 때문에 꾸준한 연습이 필요합니다.
일반적인 VLOOKUP 오류 파악
1. 문제 해결을 위한 핵심 질문
- 문제의 우선순위를 어떻게 정해야 하는가?
여러 문제를 동시에 해결하려 하기보다는 한 번에 하나의 문제에 집중하는 것이 중요합니다. 이 과정에서 중요한 것은 문제를 명확하게 정의하는 것입니다. 직면한 문제를 한 문장으로 요약해보면 상황을 명확하게 파악할 수 있습니다. - 문제 해결에 어떤 리소스를 활용할 수 있는가?
리소스는 사람뿐만 아니라 인터넷과 같은 도구도 포함됩니다. 검색을 통해 유사한 문제를 해결한 사례를 찾거나, 동료에게 도움을 요청하는 것이 좋은 방법입니다. - 문제가 다시 발생하지 않도록 할 방법은 무엇인가?
문제 해결 이후에는 동일한 문제의 재발을 막기 위한 절차를 마련해야 합니다. 예를 들어, 새로운 지침이나 프로세스를 도입하면 시간을 절약할 수 있습니다.
2. VLOOKUP의 제한 사항과 문제 해결
- VLOOKUP의 첫 번째 제한 사항은, 오른쪽에 있는 값만 반환한다는 것입니다. 즉, 왼쪽에 있는 데이터를 조회할 수 없다는 제약이 있습니다. 이 문제를 해결하기 위해 데이터의 왼쪽에 필요한 열을 복사해 놓고 작업할 수 있습니다.
- 두 번째 문제는, 열 아래로 수식을 드래그할 때 발생하는 오류입니다. 이는 테이블 배열이 고정되어 있지 않기 때문인데, 이를 해결하기 위해 절대 참조(달러 기호 $ 사용)를 적용할 수 있습니다.
- 세 번째 문제는, 참조 스프레드시트가 변경될 때 발생하는 오류입니다. 예를 들어, 새로운 열이 삽입되면 VLOOKUP 함수가 잘못된 값을 반환할 수 있습니다. 이때, 스프레드시트를 보호하여 이러한 변경을 방지할 수 있습니다.
Google Sheets에서 **‘Data’ -> ‘Protected sheets and ranges’**를 선택하여 스프레드시트를 잠글 수 있습니다. - MATCH 함수를 사용하면 데이터의 위치를 찾아, 변경된 열에 대응할 수 있습니다. 이번 시간에는 자세히 다루지 않지만, 나중에 필요할 때 활용할 수 있습니다.
3. 정확한 일치 vs 근사치 일치
- TRUE는 근사치 일치를 찾는 옵션이며, FALSE는 정확한 일치만 반환하는 옵션입니다. 데이터 애널리스트는 주로 FALSE를 사용하여 조회 값과 정확히 일치하는 항목만 반환하도록 설정합니다.
4. VLOOKUP과 문제 해결
VLOOKUP은 많은 데이터 애널리스트가 사용하는 조회 및 참조 함수입니다. 하지만 그만큼 사용 중에 발생할 수 있는 문제들도 다양합니다. 오늘 배운 내용을 바탕으로 문제를 해결하고, 더 나은 방식으로 데이터를 분석할 수 있습니다.
VLOOKUP 핵심 개념
함수를 사용하면 정보를 빠르게 찾고 특정 값을 계산할 수 있습니다. 이 읽기 자료에서는 스프레드시트 열에서 특정 값을 검색한 후 값을 발견한 행에서 해당 정보를 반환하는 VLOOKUP(Vertical Lookup)과 같은 함수의 중요성에 대해 배웁니다.

VLOOKUP은 언제 사용해야 하나요?
VLOOKUP을 사용하는 두 가지 일반적인 이유는 다음과 같습니다.
- 스프레드시트에 데이터 채우기
- 한 스프레드시트의 데이터를 다른 스프레드시트의 데이터와 병합
VLOOKUP 구문
VLOOKUP 함수는 Microsoft Excel과 Google Sheets 모두에서 사용할 수 있으며, 이 강좌에서는 Google Sheets의 일반 VLOOKUP 구문을 소개합니다. (Microsoft Excel의 VLOOKUP에 관한 자세한 내용은 이 읽기 자료의 하단에 있는 리소스를 참고하세요.)

VLOOKUP 구문은 다음과 같습니다.

search_key
- 검색할 값입니다.
- 예: 42, “Cats” 또는 I24
range
- 검색할 범위입니다.
- 범위의 첫 번째 열을 검색하여 search_key에서 지정한 값과 일치하는 데이터를 찾습니다.
index
- 반환할 값의 열 색인이며, 범위의 첫 번째 열이 1번입니다.
- 색인이 범위의 열 개수와 1 사잇값이 아니면 #VALUE!가 반환됩니다.
is_sorted
- 검색할 열(지정된 범위의 첫 번째 열)의 정렬 여부를 나타냅니다. 기본값은 TRUE입니다.
- is_sorted는 FALSE로 설정하는 것이 좋습니다. FALSE로 설정하면 정확한 일치 항목이 반환됩니다. 일치하는 값이 여러 개인 경우 처음 발견된 값에 해당하는 셀의 내용이 반환되고, 일치하는 값이 없으면 #N/A가 반환됩니다.
- is_sorted를 TRUE로 설정하거나 생략하면 가장 가까운 일치 항목(검색 키보다 작거나 같은 값)이 반환됩니다. 검색 열의 모든 값이 검색 키보다 크면 #N/A가 반환됩니다.
#N/A가 반환되면 어떻게 해야 하나요?
위에서 설명한 대로 #N/A는 VLOOKUP의 결과로 반환할 일치 값이 없다는 의미입니다. 데이터에 실제로 문제가 있다는 의미는 아니지만, 보고서에서 오류가 표시되면 사람들이 궁금해할 수도 있습니다. 따라서 IFNA 함수를 사용하여 #N/A 오류를 '값이 존재하지 않음'과 같이 보다 이해하기 쉬운 표현으로 바꿀 수 있습니다.

VLOOKUP 구문은 다음과 같습니다.

value
- 필수 값입니다.
- 셀 값이 #N/A와 같은 특정 값과 일치하는지 확인하는 함수입니다.
value_if_na
- 필수 값입니다.
- 셀 값이 첫 번째 인수의 값과 일치하는 경우 이 값이 반환됩니다. 즉, 셀 값이 #N/A인 경우 value_if_na 인수에 지정한 값이 반환됩니다.
VLOOKUP 팁
- TRUE는 검색 키와 대략적인 일치를 의미하고 FALSE는 정확한 일치를 의미합니다. 검색 키에 사용된 데이터가 정렬된 상태인 경우 TRUE를 사용할 수 있습니다.
- VLOOKUP 수식의 검색 키와 일치하는 열을 데이터의 왼쪽에 두는 것이 좋습니다. VLOOKUP은 일치 항목을 찾은 후에 오른쪽의 데이터만 조회하므로 VLOOKUP 색인은 오른쪽에 있는 열만 나타냅니다. 따라서 VLOOKUP을 사용하기 전에 열을 이동해야 할 수 있습니다.
- VLOOKUP 수식을 사용해 데이터를 채운 후 수식을 삭제하기 위한 목적으로 데이터의 값만 복사하고 붙여넣으면 데이터를 다시 조작할 수 있습니다.
Microsoft Excel의 VLOOKUP 리소스
Microsoft Excel의 VLOOKUP은 약간 다를 수 있지만 전반적인 개념은 대체로 적용됩니다. Excel로 작업하는 경우 다음 리소스를 참고해보세요.
- Excel에서 VLOOKUP을 사용하는 방법: VLOOKUP 함수가 Excel에서 작동하는 방식을 전반적으로 이해하는 데 도움이 되는 동영상과 실제 예가 포함된 튜토리얼입니다.
- Excel의 VLOOKUP 튜토리얼: Excel에서 VLOOKUP 수식을 작성하는 방법과 시간을 절약하는 도움말 및 유용한 정보에 숙달하는 방법을 안내하는 동영상 강의입니다.
- Excel에서 VLOOKUP에 관해 알아야 할 23가지 사항: VLOOKUP에 관한 23가지 사실 및 직면할 수 있는 어려움을 살펴보고 VLOOKUP에 숙달하는 방법을 배울 수 있습니다.
- How to use Excel's VLOOKUP function: VLOOKUP을 적용하여 검색하는 방법에 관한 구체적인 예를 공유한 자료입니다.
- Excel과 Google Sheets의 VLOOKUP 비교: Excel과 Google Sheets의 VLOOKUP을 비교한 가이드입니다.
JOINS를 사용하여 SQL에서 데이터 집계
JOINS의 이해
1. JOIN의 종류
SQL에서 데이터 애널리스트가 자주 사용하는 JOIN에는 네 가지가 있습니다:
- INNER JOIN: 두 테이블에서 일치하는 레코드만 반환합니다. 벤다이어그램에서 두 테이블이 겹치는 부분만 추출하는 것과 같습니다.
- LEFT JOIN: 왼쪽 테이블의 모든 레코드와 오른쪽 테이블의 일치하는 레코드를 반환합니다. 왼쪽 테이블의 모든 데이터를 포함하되, 오른쪽 테이블에 해당하는 값이 없는 경우 NULL 값을 반환합니다.
- RIGHT JOIN: LEFT JOIN의 반대로, 오른쪽 테이블의 모든 레코드를 포함하고, 왼쪽 테이블에서 일치하는 레코드만 반환합니다.
- FULL OUTER JOIN: 두 테이블의 모든 레코드를 반환하며, 일치하지 않는 항목에는 NULL 값을 채웁니다.
2. JOIN과 관계형 데이터베이스
관계형 데이터베이스에서는 기본 키(primary key)와 외래 키(foreign key)를 사용하여 테이블 간의 관계를 정의합니다. 예를 들어, 직원 테이블에서 직원 ID는 기본 키가 될 수 있으며, 부서 ID는 외래 키가 됩니다. JOIN은 이러한 관계를 바탕으로 두 테이블을 결합합니다.
3. INNER JOIN 예시
다음은 INNER JOIN을 사용하여 두 테이블을 결합하는 간단한 예입니다. 이 쿼리는 employees 테이블과 departments 테이블을 결합하여 부서가 있는 직원 목록을 반환합니다:
sql
SELECT employees.name, departments.name AS department_name
FROM employees
INNER JOIN departments
ON employees.department_id = departments.department_id;
여기서 ON 절을 통해 두 테이블의 공통 열인 department_id를 기준으로 데이터를 결합합니다. 결과로 부서가 있는 직원의 이름과 부서 이름이 반환됩니다.
4. LEFT JOIN과 RIGHT JOIN
- LEFT JOIN을 사용하면, employees 테이블에서 모든 직원의 이름을 반환하며, departments 테이블에 해당하는 부서가 없는 경우 NULL 값을 반환합니다:
sql
SELECT employees.name, departments.name AS department_name
FROM employees
LEFT JOIN departments
ON employees.department_id = departments.department_id;- RIGHT JOIN은 오른쪽 테이블, 즉 departments 테이블의 모든 부서를 포함하고, employees 테이블에 일치하는 직원이 없을 경우 NULL 값을 반환합니다:
sql
SELECT employees.name, departments.name AS department_name
FROM employees
RIGHT JOIN departments
ON employees.department_id = departments.department_id;
5. FULL OUTER JOIN
마지막으로, FULL OUTER JOIN은 두 테이블의 모든 데이터를 결합하여 반환하며, 일치하지 않는 데이터는 NULL로 채웁니다:
sql
SELECT employees.name, departments.name AS department_name
FROM employees
FULL OUTER JOIN departments
ON employees.department_id = departments.department_id;
JOIN은 여러 테이블의 데이터를 결합하여 분석할 때 매우 유용한 도구입니다. 이를 통해 관계형 데이터베이스에서 보다 복잡한 데이터 집계를 쉽게 수행할 수 있습니다. 다음 시간에는 SQL에서 데이터 집계에 대해 더 깊이 알아보겠습니다.
다른 이름: 별칭의 중요성
이 읽기 자료에서는 별칭 지정으로 SQL 쿼리를 단순화하는 방법을 배웁니다. 별칭은 SQL 쿼리에서 열 또는 테이블의 임시 이름을 만드는 데 사용합니다. 테이블 또는 열 이름이 쿼리에 사용하기에 너무 길거나 복잡할 때 별칭을 활용하면 SQL 쿼리에서 훨씬 간단하게 테이블 및 열을 참조할 수 있습니다. 테이블 이름이 special_projects_customer_negotiation_mileages라고 가정해봅시다. 테이블을 사용할 때마다 이름을 다시 입력하기는 어려울 것입니다. 별칭을 활용하면 의미 있는 별명을 만들어 분석 중에 사용할 수 있습니다. 이 경우 'special_projects_customer_negotiation_mileages'는 간단히 'mileage'라는 별칭을 지정하면 됩니다. 긴 테이블 이름을 작성하는 대신 직접 지정한 의미 있는 별명을 사용할 수 있습니다.
별칭 지정의 기본 구문
별칭 지정은 별칭을 사용하는 프로세스이며, SQL 쿼리에서 AS 명령어를 사용하여 별칭을 구현할 수 있습니다. 테이블 별칭을 지정하는 다음 쿼리에서 AS 명령어의 기본 구문을 확인해보세요.

AS 앞에는 테이블 이름을 적고 그 뒤에는 새 별칭을 적습니다. 열의 별칭을 지정하는 방법도 이와 유사합니다.

두 경우 모두 별칭을 새 이름으로 사용해 해당 열이나 테이블을 참조할 수 있습니다.
별칭의 대체 구문
작업 중인 SQL 데이터베이스에서 AS가 지원되지 않아 AS를 사용하여 쿼리를 실행한 결과로 오류가 반환되는 경우 AS를 생략해도 됩니다. 이전 예에서 테이블 또는 열에 별칭을 지정하는 대체 구문은 다음과 같습니다.
- FROM table_name alias_name
- SELECT column_name alias_name
핵심을 요약하자면 별칭을 지정하는 쿼리는 AS를 사용하거나 사용하지 않아도 실행되지만, AS를 사용하면 쿼리를 쉽게 읽을 수 있어 별칭이 더 명확하게 도드라집니다.
별칭 지정 실행
별칭 지정을 사용하는 SQL 쿼리의 예를 살펴보겠습니다. 두 개의 테이블로 작업 중인데, 한 테이블에는 직원 데이터가 있고 다른 테이블에는 부서 데이터가 있습니다. 테이블의 별칭을 지정하는 FROM 문은 다음과 같습니다.

FROM work_day.employees AS employees
별칭을 사용하면 테이블에 포함된 내용을 정확히 알 수 있으면서 더 이상 긴 테이블 이름을 수동으로 입력할 필요가 없습니다. 별칭은 길고 복잡한 쿼리에 매우 유용합니다. 테이블에 포함된 내용을 시사하는 별칭을 사용하면 쿼리를 읽고 쓰기가 훨씬 쉬워집니다.
추가 정보
별칭 지정에 관해 자세히 알아보려면 다음의 몇 가지 리소스를 참고하세요. 별칭 지정을 처음 사용하는 경우 유용한 리소스입니다.
- SQL Aliases: 직접 쿼리 작성과 테이블 별칭 지정을 연습하는 데 매우 유용한 별칭 지정 튜토리얼입니다. 또한 별칭 지정이 실제 테이블에서 어떻게 작동하는지 확인할 수 있습니다.
- SQL Alias: 여러 예를 활용해 별칭 지정에 관해 자세히 소개한 리소스입니다. 더 많은 예를 참고해야 하는 경우 정말 유용합니다.
- Using Column Aliasing: 열 별칭 지정을 중점적으로 다룬 가이드입니다. 일반적으로는 전체 테이블에 별칭을 지정하지만, 열에만 별칭을 지정해야 하는 경우 도움이 되는 리소스입니다. 북마크에 추가하여 참고해보세요.
효과적인 JOIN 사용
이 읽기 자료에서는 JOIN의 사용 방식을 검토해봅니다. JOIN에 관해 자세히 알아볼 수 있는 몇 가지 리소스도 제공됩니다. JOIN은 기본 키 또는 외래 키를 사용하여 테이블을 결합하고 결합 중에 두 테이블의 정보를 정렬합니다. JOIN 함수에서 기본 키와 외래 키는 테이블 간의 관계를 파악하고 해당하는 값을 찾아내는 데 사용됩니다.
기본 키와 외래 키를 복습하려면 이 강좌의 용어집을 참고하거나 데이터 애널리틱스에서의 데이터베이스를 다시 살펴보세요.
일반 JOIN 구문
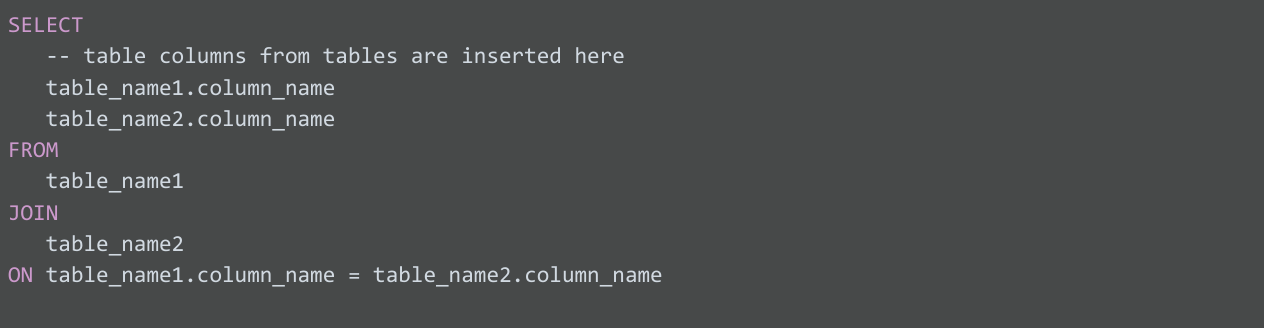
위 구문에서 볼 수 있듯이 JOIN 문은 쿼리에서 FROM 절의 일부입니다. SQL에서 JOIN은 두 테이블의 데이터를 결합한다는 의미이고, ON은 두 테이블에서 결합할 올바른 정보를 위해 테이블을 일치시킬 기준을 파악합니다.
JOIN의 유형
SQL 쿼리에서 JOIN을 실행하는 네 가지 일반적인 방법은 INNER, LEFT, RIGHT, FULL OUTER입니다.
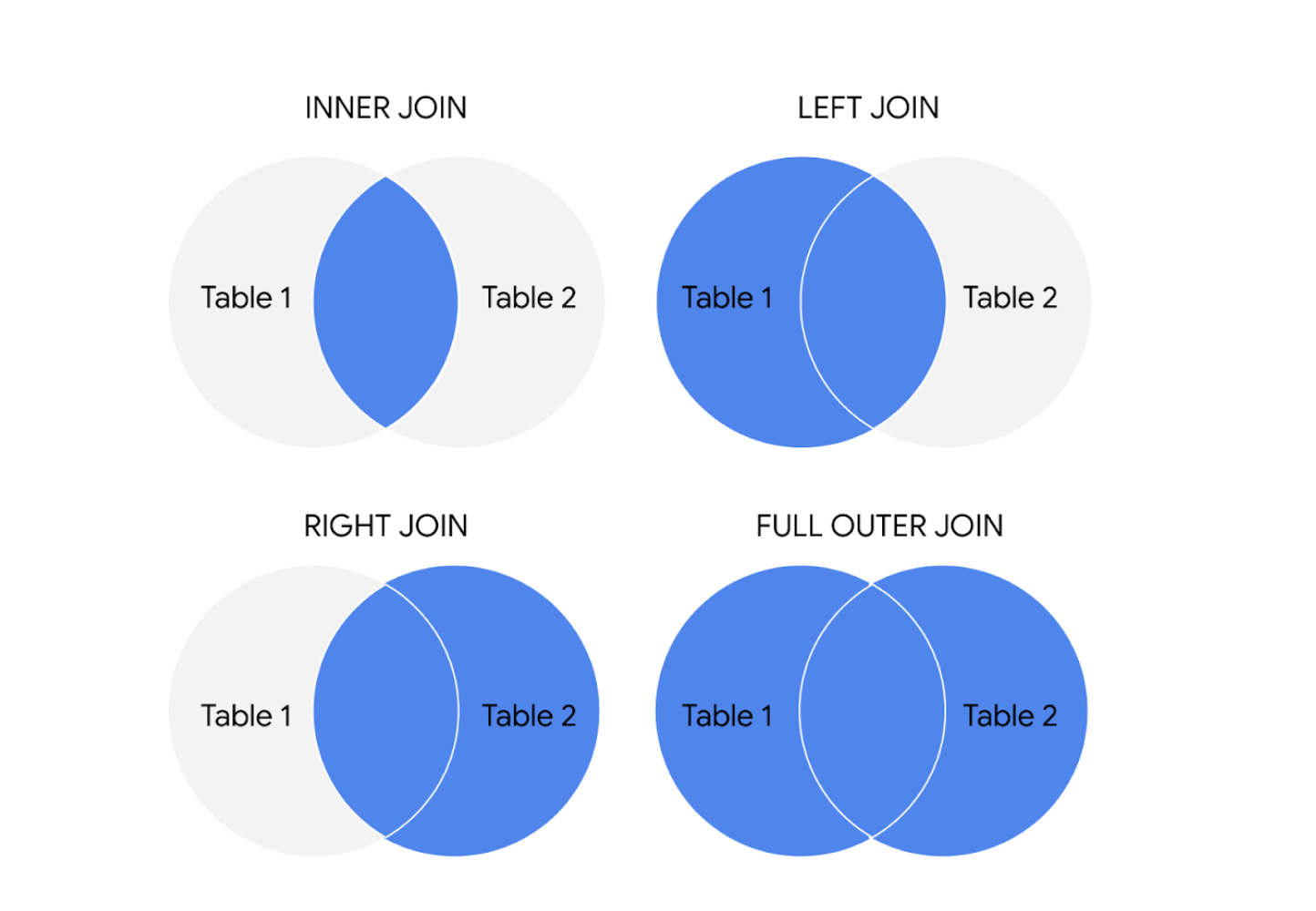
원은 왼쪽 테이블과 오른쪽 테이블을 나타내며 결합되는 영역은 파란색으로 강조표시됩니다.
다양한 JOIN 쿼리의 작동 방식은 다음과 같습니다.
INNER JOIN
INNER는 JOIN의 기본값이자 가장 흔하게 사용되는 JOIN 연산이므로 SQL 쿼리에서 작성 여부가 선택사항입니다. INNER JOIN은 JOIN으로만 표시되기도 합니다. INNER JOIN은 데이터가 두 테이블 모두에 있는 경우 레코드를 반환합니다. 예를 들어 'customers' 및 'orders' 테이블에 INNER JOIN을 사용하고 customer_id 키를 사용하여 데이터를 일치시키는 경우, 두 테이블에 존재하는 각 customer_id의 데이터가 결합됩니다. customer_id가 customers 테이블에 있지만 orders 테이블에는 없는 경우, customer_id의 데이터가 쿼리 결과로 결합되거나 반환되지 않습니다.
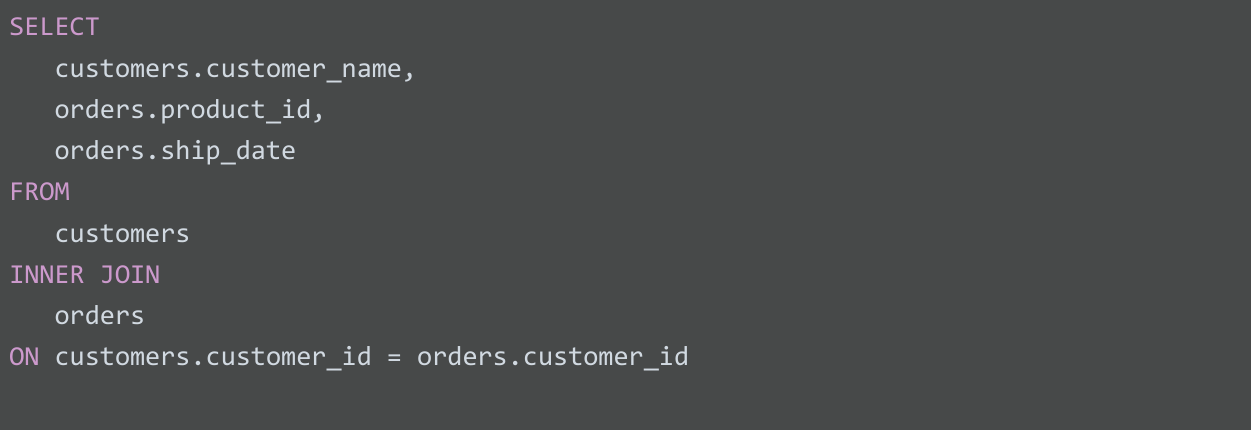
쿼리 결과는 다음과 같습니다. 여기서 customer_name은 customers 테이블에서, product_id 및 ship_date는 orders 테이블에서 가져옵니다.
| customer_name |
product_id | ship_date |
| Martin's Ice Cream | 043998 | 2021-02-23 |
| Beachside Treats | 872012 | 2021-02-25 |
| Mona's Natural Flavors | 724956 | 2021-02-28 |
| ... 기타 등등 | ... 기타 등등 | ... 기타 등등 |
두 테이블의 데이터는 두 테이블의 공통 요소인 customer_id를 일치시켜 결합되었습니다. customer_id는 쿼리 결과에 표시되지 않으며, 데이터를 결합하고 반환할 수 있도록 두 테이블의 데이터 간 관계를 설정하는 데 사용됩니다.
LEFT JOIN
LEFT JOIN은 LEFT OUTER JOIN으로 표시할 수 있지만 대부분의 사용자는 LEFT JOIN을 선호합니다. 둘 다 올바른 구문입니다. LEFT JOIN은 왼쪽 테이블에서 모든 레코드를 반환하고, 오른쪽 테이블에서 왼쪽 테이블과 일치하는 레코드만 반환합니다. 첫 번째 테이블의 모든 데이터와 두 번째 테이블의 값(있는 경우)이 필요할 때 LEFT JOIN을 사용하면 됩니다. 예를 들어 아래 쿼리에서 LEFT JOIN은 customer_name과 함께 해당 sales_rep(값이 있는 경우)을 반환합니다. 영업 담당자와 상호작용하지 않은 고객의 경우 해당 고객 이름은 쿼리 결과에 표시되지만 sales_rep에는 NULL 값이 표시됩니다.
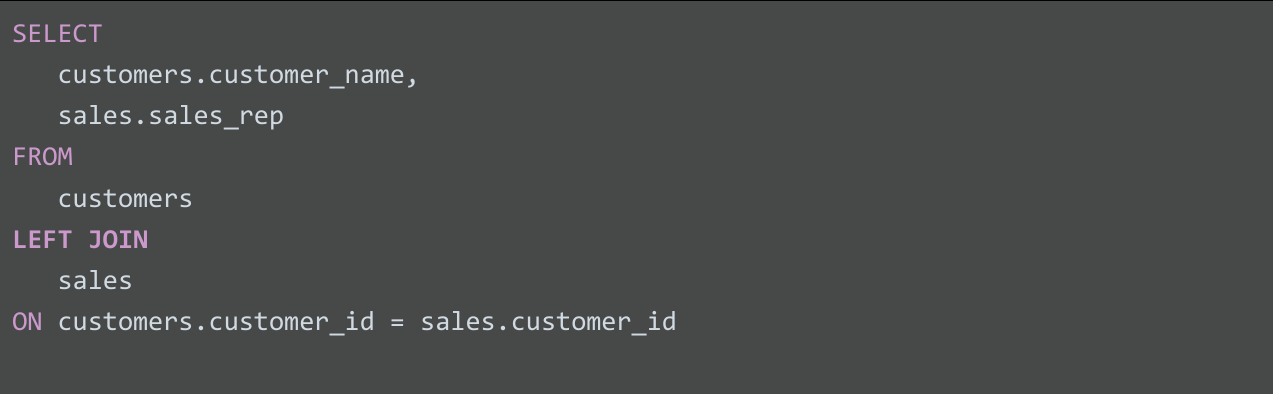
쿼리 결과는 다음과 같습니다. 여기서 customer_name은 customers 테이블에서, sales_rep은 sales 테이블에서 가져옵니다. 쿼리 결과에 customer_id가 반환되지는 않았지만 두 테이블의 데이터는 두 테이블의 공통 요소인 customer_id를 일치시켜 결합되었습니다.
| customer_name | sales_rep |
| Martin's Ice Cream | Luis Reyes |
| Beachside Treats | NULL |
| Mona's Natural Flavors | Geri Hall |
| ... 기타 등등 | ... 기타 등등 |
RIGHT JOIN
RIGHT JOIN은 RIGHT OUTER JOIN 또는 RIGHT JOIN으로 표시할 수 있습니다. RIGHT JOIN은 오른쪽 테이블에서 모든 레코드를 반환하고, 왼쪽 테이블에서는 오른쪽 테이블과 일치하는 레코드를 반환합니다. 사실 RIGHT JOIN은 거의 사용되지 않습니다. 대부분 테이블을 전환한 후 LEFT JOIN을 사용합니다. LEFT JOIN 섹션에서 나온 이전 예로 RIGHT JOIN을 사용한 쿼리는 다음과 같습니다.
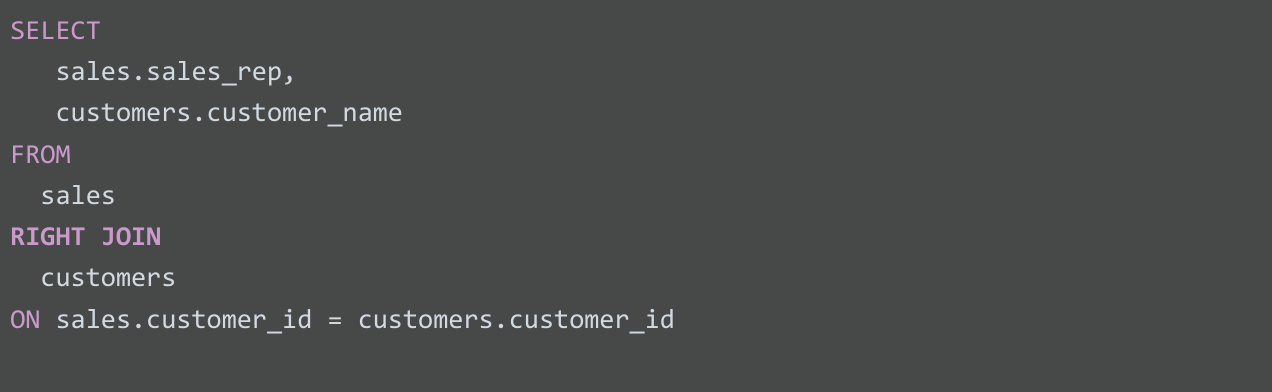
쿼리 결과는 이전 LEFT JOIN 예와 동일합니다.
| customer_name | sales_rep |
| Martin's Ice Cream | Luis Reyes |
| Beachside Treats | NULL |
| Mona's Natural Flavors | Geri Hall |
| ... 기타 등등 | ... 기타 등등 |
FULL OUTER JOIN
FULL OUTER JOIN은 FULL JOIN으로 표시되기도 합니다. FULL OUTER JOIN은 지정된 테이블의 모든 레코드를 반환합니다. 이렇게 하면 테이블이 결합되지만, 그 결과 데이터가 굉장히 커질 수 있습니다. FULL OUTER JOIN은 테이블 중 하나의 데이터가 채워져 있지 않은 경우에도 두 테이블의 모든 레코드를 반환합니다. 예를 들어 아래 쿼리에서는 모든 고객과 해당 제품의 배송일을 확인할 수 있습니다. FULL OUTER JOIN을 사용하기 때문에 배송일 없이 고객 이름만 반환되거나 고객 이름 없이 배송일만 반환될 수 있습니다. 데이터가 어느 테이블에도 존재하지 않으면 NULL 값이 반환됩니다.
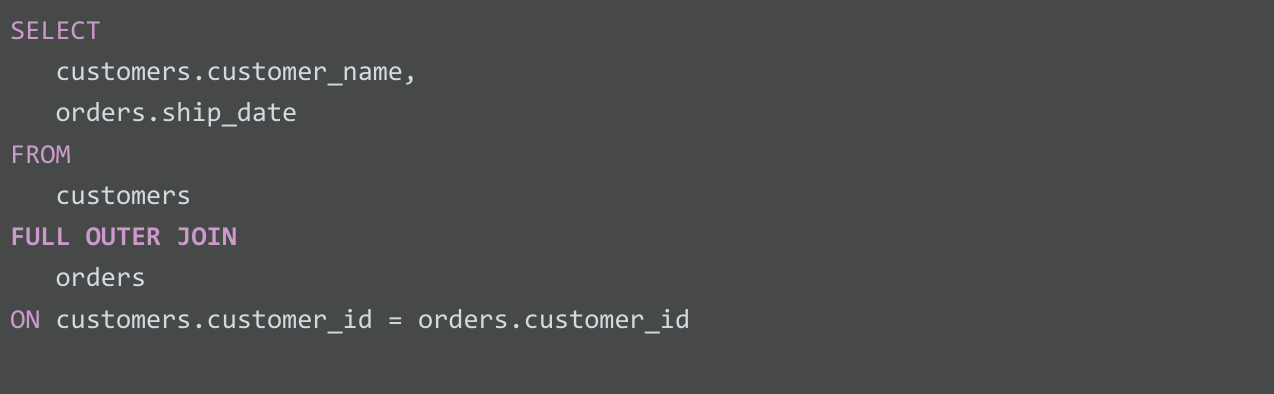
쿼리 결과는 다음과 같습니다.
| customer_name |
ship_date |
| Martin's Ice Cream | 2021-02-23 |
| Beachside Treats | 2021-02-25 |
| NULL | 2021-02-25 |
| The Daily Scoop | NULL |
| Mountain Ice Cream | NULL |
| Mona's Natural Flavors | 2021-02-28 |
| ... 기타 등등 | ... 기타 등등 |
추가 정보
JOIN은 관계형 데이터베이스 및 SQL을 사용하는 작업에 유용하며, 직접 연습해볼 기회가 많습니다. 다음은 JOIN 및 JOIN 사용 방법에 관한 자세한 정보를 확인할 수 있는 몇 가지 리소스입니다.
- SQL JOINs: 예를 사용해 JOIN을 설명한 기본 설명서입니다. 북마크에 추가한 후 다양한 JOIN의 작업을 간단히 살펴봐야 할 때 다시 참고해보세요.
- 데이터베이스 JOIN - JOIN 유형 및 개념 소개: JOIN에 관해 자세히 소개한 리소스입니다. JOIN의 정의와 사용 방법이 나와 있으며, 다양한 JOIN을 사용하는 경우 및 이유가 여러 시나리오를 기반으로 자세히 설명되어 있습니다. JOIN 작동 논리를 자세히 알고 싶은 경우 유용하게 참고할 수 있는 리소스입니다.
- 시각 자료로 보는 SQL JOIN 유형:다양한 JOIN을 시각 자료로 설명하는 리소스입니다. 시각 자료를 통한 학습이 편한 경우 JOIN에 관해 생각해보는 데 매우 유용한 방법이며 다양한 JOIN을 기억하는 데 도움이 됩니다.
- SQL JOIN: 한 번에 하나의 JOIN으로 데이터 결합: 예를 사용해 JOIN에 관해 자세히 설명하며, 단계별 안내에 따라 실습할 수 있는 예제 데이터도 제공하는 리소스입니다. 실제 데이터 일부를 사용하여 JOIN을 연습하는 데 유용합니다.
- SQL JOIN: JOIN에 관해 명확히 설명하며, 예를 사용해 JOIN의 작동 방식을 시연하는 리소스입니다. JOIN과 별칭 지정을 함께 사용하는 예도 제공됩니다. 이번 강좌에서 학습한 다른 SQL 개념을 기반으로 JOIN을 사용하는 방법을 살펴볼 수 있습니다.
COUNT 및 COUNT DISTINCT
SQL의 COUNT와 COUNT DISTINCT 사용하기
1. COUNT와 COUNT DISTINCT의 개요
- COUNT:
- 목적: 특정 범위 내의 총 행 수를 반환.
- 용도: 데이터 세트에서 특정 값의 개수를 파악할 때 사용. 예를 들어, 총 고객 수나 총 거래 수를 계산할 때 유용합니다.
- 기능: 중복을 고려하지 않고 범위 내 모든 행을 계산합니다.
- COUNT DISTINCT:
- 목적: 지정된 범위 내에서 중복 값을 제외한 고유한 값의 개수를 반환.
- 용도: 중복된 값을 제외한 고유한 항목의 수를 계산할 때 사용. 예를 들어, 고유한 고객 수나 고유한 주 수를 파악할 때 유용합니다.
- 기능: 중복된 값을 제외하고, 각 값이 몇 번 등장하는지 계산하지 않습니다.
2. 사용 사례 및 쿼리 예시
- 예시 시나리오:
- 두 개의 테이블 Warehouse와 Orders가 있다고 가정합니다. 각 테이블의 데이터는 다음과 같습니다:
- Warehouse: warehouse_ID, warehouse_alias, maximum_capacity, employees_total, state 등의 열이 포함됨.
- Orders: order_ID, order_date, warehouse_ID 등의 열이 포함됨.
- 두 개의 테이블 Warehouse와 Orders가 있다고 가정합니다. 각 테이블의 데이터는 다음과 같습니다:
- 쿼리 작성:
sql
SELECT *
FROM orders
INNER JOIN warehouse
ON orders.warehouse_ID = warehouse.warehouse_ID;
JOIN을 이용한 데이터 결합:
- 두 테이블을 결합하여 필요한 정보를 가져옵니다. 이때 INNER JOIN을 사용하여 두 테이블의 일치하는 데이터를 결합합니다.
- FROM 문에서 두 테이블을 INNER JOIN을 통해 결합하고, warehouse 테이블을 별칭으로 지정할 수도 있습니다.
COUNT 쿼리:
- 데이터 세트 내 모든 주의 개수를 계산합니다.
sql
SELECT COUNT(*)
FROM orders
INNER JOIN warehouse
ON orders.warehouse_ID = warehouse.warehouse_ID;- 이 쿼리는 모든 행을 계산하여 총 9,000개 이상의 주가 반환될 수 있습니다.
COUNT DISTINCT 쿼리:
- 중복된 값을 제외하고 고유한 주의 개수를 계산합니다.
sql
SELECT COUNT(DISTINCT warehouse.state)
FROM orders
INNER JOIN warehouse
ON orders.warehouse_ID = warehouse.warehouse_ID;- 이 쿼리는 중복된 주를 제외하고 고유한 주의 개수를 반환하며, 예를 들어 3개의 고유한 주가 반환될 수 있습니다.
3. 결과 분석
- COUNT:
- 총 행 수를 반환하며, 중복된 값이 있더라도 모든 행을 계산합니다. 따라서 데이터가 많은 경우 총 행 수가 매우 클 수 있습니다.
- COUNT DISTINCT:
- 중복을 제거한 후 고유한 값의 개수를 반환합니다. 이 방법으로 중복된 값을 제외하고 필요한 데이터의 수를 정확히 파악할 수 있습니다.
4. 실습 및 응용
- COUNT와 COUNT DISTINCT는 데이터 분석의 모든 단계에서 필수적인 도구입니다. 이들을 이해하고 적절히 활용하는 것은 데이터 집계 및 분석의 정확성을 높이는 데 도움을 줍니다.
- 데이터 세트에서 필요한 정보의 수량을 확인할 때, 이 두 함수를 적절히 사용하여 효율적인 분석을 수행할 수 있습니다.
서브쿼리로 작업
쿼리에 속한 쿼리
SQL 서브쿼리
1. 서브쿼리란?
- 정의: 서브쿼리는 하나의 SQL 쿼리 안에 포함된 또 다른 SQL 쿼리입니다. 상위 쿼리(외부 쿼리) 안에 중첩된 형태로 존재하며, 결과적으로 하나의 전체 쿼리를 형성합니다.
- 비유: 러시아의 마트료시카 인형처럼, 서브쿼리는 여러 개가 중첩되어 있으며, 각 서브쿼리는 외부 쿼리의 일부로 작용합니다.
- 실행 순서: 서브쿼리는 먼저 실행되어야 하며, 그 결과가 외부 쿼리로 전달됩니다.
2. 서브쿼리의 사용 위치
- FROM 절: 서브쿼리를 FROM 절에 중첩하여 테이블처럼 사용할 수 있습니다.
- WHERE 절: 서브쿼리를 WHERE 절에 중첩하여 조건을 추가할 수 있습니다.
3. 서브쿼리 예시
- 서브쿼리로 평균 자전거 수 비교하기
- 목표: 대여소별로 사용 가능한 자전거 수와 전체 평균 자전거 수를 비교합니다.
쿼리:
sql
SELECT station_id, available_bikes,
(SELECT AVG(available_bikes)
FROM bikes) AS avg_bikes
FROM rental_stations;-
- 설명: 서브쿼리는 전체 자전거 수의 평균을 계산하고, 이 평균을 외부 쿼리의 결과와 비교합니다.
- 서브쿼리로 대여소별 자전거 타기 횟수 집계하기
- 목표: 각 대여소에서 시작된 자전거 타기 횟수를 시간 추이에 따라 계산합니다.
쿼리:
sql
SELECT rs.station_id, rs.name, COUNT(t.number_of_rides)
FROM rental_stations AS rs
INNER JOIN
(SELECT start_station_id, COUNT(*) AS number_of_rides
FROM trips
GROUP BY start_station_id) AS t
ON rs.station_id = t.start_station_id
GROUP BY rs.station_id, rs.name
ORDER BY number_of_rides DESC;-
- 설명: 서브쿼리는 각 대여소에서 시작된 자전거 타기 횟수를 계산하고, 외부 쿼리는 이 데이터를 대여소 정보와 결합하여 결과를 정렬합니다.
- 서브쿼리로 구독자 이용 대여소 목록 찾기
- 목표: 구독자가 이용한 대여소 목록을 찾습니다.
쿼리:
sql
SELECT station_id, name
FROM rental_stations
WHERE station_id IN
(SELECT DISTINCT start_station_id
FROM trips
WHERE user_type = 'Subscriber');-
- 설명: 서브쿼리는 구독자가 이용한 대여소의 ID 목록을 반환하고, 외부 쿼리는 이 ID를 기준으로 대여소 목록을 찾습니다.
4. 서브쿼리의 장점
- 효율성: 복잡한 논리를 단일 쿼리로 통합하여 데이터 분석의 효율성을 높입니다.
- 가독성: 서브쿼리를 사용하면 쿼리가 더 명확하게 분리되어 읽기 쉬워집니다.
- 유연성: 서브쿼리는 다양한 쿼리 내에 중첩될 수 있어 복잡한 데이터 집계 작업에 유용합니다.
5. 서브쿼리 사용 시 유의사항
- 층이 많아질 수 있음: 서브쿼리가 중첩되면 쿼리가 복잡해질 수 있으며, 실행 순서를 정확히 이해해야 합니다.
- 성능: 서브쿼리의 사용이 쿼리 성능에 영향을 미칠 수 있으므로, 성능을 고려하여 최적화하는 것이 중요합니다.
서브쿼리를 사용하여 데이터 집계
SQL 서브쿼리와 데이터 집계
1. 서브쿼리 개요
- 서브쿼리: 하나의 SQL 쿼리 안에 포함된 또 다른 SQL 쿼리로, 상위 쿼리의 일부로 작용합니다.
- 사용 위치: 서브쿼리는 FROM, WHERE, SELECT 절 등 여러 위치에 중첩될 수 있습니다.
2. 새로운 함수와 절
- HAVING 절: 집계 함수와 함께 사용할 수 있는 필터링 절로, GROUP BY로 그룹화된 데이터에 조건을 추가합니다.
- CASE 문: 쿼리에서 조건부 논리를 적용할 때 사용됩니다. IF/THEN 문을 SQL로 표현하는 방식입니다.
3. 서브쿼리 예제
- 창고별 처리 주문 비율 계산
- 목표: 각 창고에서 처리한 주문의 비율을 계산하여 가장 많은 주문을 처리하는 창고를 파악합니다.
쿼리:
sql
SELECT w.warehouse_id,
CONCAT(w.state, ' ', w.warehouse_alias) AS warehouse_name,
COUNT(o.order_id) AS orders_count,
(SELECT COUNT(*) FROM Orders) AS total_orders,
CASE
WHEN COUNT(o.order_id) / (SELECT COUNT(*) FROM Orders) <= 0.2 THEN 'fulfilled 0-20% of Orders'
WHEN COUNT(o.order_id) / (SELECT COUNT(*) FROM Orders) <= 0.6 THEN 'fulfilled 21-60% of Orders'
ELSE 'Fulfilled more than 60% of Orders'
END AS fulfillment_summary
FROM Warehouse AS w
LEFT JOIN Orders AS o ON w.warehouse_id = o.warehouse_id
GROUP BY w.warehouse_id, w.state, w.warehouse_alias
HAVING COUNT(o.order_id) > 0;-
- 설명:
- JOIN: Warehouse와 Orders 테이블을 LEFT JOIN하여 창고의 모든 정보를 포함합니다.
- COUNT: 각 창고에서의 주문 수를 계산합니다.
- SUBQUERY: 전체 주문 수를 계산하여 비율을 구합니다.
- CASE: 처리한 주문 비율에 따라 창고의 카테고리를 지정합니다.
- HAVING: 최소 하나 이상의 주문을 처리한 창고만 포함하도록 필터링합니다.
- 설명:
4. 결과 분석
- 이 쿼리를 통해 각 창고의 주문 처리 비율을 확인하고, 처리 비율에 따라 창고를 분류할 수 있습니다. 또한, 아직 주문을 처리하지 않는 건설 중인 창고는 결과에서 제외됩니다.
SQL 함수 및 서브쿼리: 실용적인 관계
이 읽기 자료에서는 SQL 함수에 관한 정보와 SQL 함수를 서브쿼리와 함께 사용하는 방법에 관해 배웁니다. SQL 함수는 계산을 처리할 수 있도록 SQL에 기본 제공되는 도구입니다. 서브쿼리(내부 쿼리 또는 중첩 쿼리라고도 함)는 다른 쿼리 내에 중첩된 쿼리입니다.
SQL 함수의 작동 방식
SQL 함수는 데이터를 집계하는 데 도움이 됩니다. (잠깐 되짚어보자면 데이터 집계는 여러 소스의 데이터를 모아 하나의 요약된 모음으로 결합하는 과정입니다.) 그렇다면 SQL 함수는 어떻게 작동할까요? W3Schools로 돌아가서 다음 쿼리의 실행 방법을 보다 잘 이해하기 위해 일부 SQL 함수를 검토해보세요.
- SQL HAVING: HAVING 절에 대한 개요로, HAVING 절의 정의와 작동 방법 및 조건에 관한 튜토리얼이 포함되어 있습니다.
- SQL CASE: CASE 문의 사용 방법과 작동 방식의 예를 살펴봅니다.
- SQL IF: IF 함수에 관한 튜토리얼이며 연습할 수 있는 예를 제공합니다.
- SQL COUNT: COUNT 함수는 다른 함수만큼 중요합니다. 검토할만한 다양한 예를 제공하는 튜토리얼입니다.
서브쿼리 - 마무리 장식
쿼리를 케이크라고 생각해보세요. 케이크는 여러 층으로 쌓을 수 있고 심지어 층 안에 또 다른 층을 포함할 수도 있습니다. 케이크의 각 층이 서브쿼리에 해당하며 모든 층을 합치면 케이크, 즉 쿼리가 됩니다. 일반적으로 서브쿼리는 SELECT, FROM, WHERE 절에 중첩됩니다. 서브쿼리에는 일반적인 구문이 없지만 기본 서브쿼리의 구문은 다음과 같습니다.

SELECT account_table.* FROM ( SELECT * FROM transaction.sf_model_feature_2014_01 WHERE day_of_week = 'Friday' ) account_table WHERE account_table.availability = 'YES’
첫 번째 SELECT 절 내에 또 다른 SELECT 절이 있음을 알 수 있습니다. 두 번째 SELECT 절은 이 문에서 서브쿼리의 시작을 나타냅니다. 서브쿼리의 활용 방법은 다양하며, 관련 리소스를 참고하면 학습 시 추가적으로 도움을 받을 수 있습니다.
먼저 서브쿼리 규칙을 요약해보겠습니다.
서브쿼리와 관련해 따라야 할 몇 가지 규칙은 다음과 같습니다.
- 서브쿼리는 괄호로 묶어야 합니다.
- 서브쿼리에서는 SELECT 절에 하나의 열만 지정할 수 있습니다. 서브쿼리를 사용하여 여러 열을 비교하려면 비교할 열을 메인 쿼리에서 선택해야 합니다.
- 둘 이상의 행을 반환하는 서브쿼리는 WHERE 절에 여러 값을 지정하는 IN 연산자와 같은 다중 값 연산자에만 사용할 수 있습니다.
- 서브쿼리는 SET 명령어에 중첩될 수 없습니다. SET은 UPDATE와 함께 사용하여 테이블에서 업데이트할 열과 값을 지정하는 명령어입니다.
추가 리소스
다음 리소스는 서브쿼리 및 사용 방법에 관한 추가 지침을 제공합니다.
- SQL subqueries: 서브쿼리의 정의, SQL에서의 목적, 사용 조건 및 방법, 결과에 관해 자세히 설명하는 리소스입니다.
- Writing subqueries in SQL: 서브쿼리의 기본사항을 탐색할 수 있으며 예와 연습 문제가 제공되는 대화형 튜토리얼입니다.
SQL, 함수, 서브쿼리 사용에 관해 자세히 학습하다 보면 이러한 도움말 및 유용한 정보가 많은 시간을 절약하는 데 얼마나 도움이 되는지 알게 됩니다.
'GCC > 데이터 애널리틱스' 카테고리의 다른 글
| [Coursera Google] GCC 데이터 애널리틱스 : 시각화를 통한 데이터 공유 | 데이터 시각화 (4) | 2024.09.23 |
|---|---|
| [Coursera Google] GCC 데이터 애널리틱스 : 데이터 분석을 통한 해답 찾기 | 데이터 계산 (2) | 2024.09.13 |
| [Coursera Google] GCC 데이터 애널리틱스 : 데이터 분석을 통한 해답 찾기 | 데이터 형식 지정 및 조정 (1) | 2024.09.11 |
| [Coursera Google] GCC 데이터 애널리틱스 : 데이터 분석을 통한 해답 찾기 | 분석 시작 전 데이터 구성 (4) | 2024.09.10 |
| [Coursera Google] GCC 데이터 애널리틱스 : 데이터 정리 | 선택사항: 이력서에 데이터 추가 (4) | 2024.09.09 |