2024. 10. 1. 12:59ㆍGCC/데이터 애널리틱스

데이터와 R 살펴보기
R 데이터 프레임
데이터 프레임 및 Tibble 사용에 관한 요약
- 데이터 프레임 정의
- 데이터 프레임은 열의 모음으로, 스프레드시트나 SQL 테이블과 유사한 구조를 가집니다.
- 각 열은 하나의 변수를 나타내며, 행에는 해당 변수에 대한 값이 포함됩니다.
- 데이터 프레임은 데이터를 요약하고 사용하기 쉬운 형식으로 만들기 위해 사용됩니다.
- 열 이름은 반드시 있어야 하며, 데이터 항목의 개수는 동일해야 합니다.
- 데이터 프레임의 주요 속성
- 데이터 프레임에는 수치, 팩터, 문자 등 다양한 데이터 유형이 포함될 수 있습니다.
- 날짜, 타임스탬프, 논리 벡터와 같은 데이터 유형도 지원됩니다.
- 각 열의 데이터는 일관된 개수를 가져야 하며, 데이터가 누락되더라도 행은 유지됩니다.
- Tibble이란?
- Tibble은 간소화된 데이터 프레임으로, tidyverse 패키지에서 제공됩니다.
- 데이터 유형을 자동으로 변환하지 않으며, 입력된 데이터를 그대로 유지합니다.
- Tibble은 데이터 정리가 더 쉽고, 데이터를 불러오는 데 소요되는 시간이 적습니다.
- 행 이름을 생성하지 않으며, 열 이름도 유지하여 보다 일관된 출력을 제공합니다.
- Tibble의 장점
- 대규모 데이터를 다룰 때, 화면에 맞게 자동으로 열과 행을 가져오도록 설정되어 콘솔에 과도한 데이터를 불러오는 실수를 방지합니다.
- R 분석의 기본적인 요소로, 데이터 프레임과 tibble을 잘 다루면 분석의 재현성과 효율성을 높일 수 있습니다.
- 타이디 데이터 원칙
- 변수는 열로, 관측값은 행으로, 각 값은 고유한 셀에 구성됩니다.
- 이러한 표준화된 데이터 구조를 통해 데이터를 보다 효율적으로 정리하고 작업할 수 있습니다.
데이터 프레임 작업
R에서 데이터 프레임 생성 및 작업
- 데이터 프레임의 중요성
- 데이터 프레임은 데이터 애널리스트가 데이터를 구성하고 분석하는 데 중요한 역할을 합니다.
- 스프레드시트와 유사하게 열과 행의 구조를 가지며, 애널리스트가 데이터와 상호작용하는 기본 형식입니다.
- 기본 제공 데이터 세트 사용
- R에는 여러 기본 제공 데이터 세트가 있습니다. 이번 예시에서는 ggplot2 패키지에 포함된 diamonds 데이터 세트를 사용합니다.
- data() 함수를 통해 데이터 세트를 불러오고, 필요에 따라 이를 데이터 뷰어에 추가할 수 있습니다.
- 데이터 프레임 미리보기
- 데이터 프레임의 일부만 미리 보고 싶을 때는 head() 함수를 사용하여 첫 6행만 출력할 수 있습니다.
- str() 함수를 사용하면 데이터 프레임의 구조를 출력하고, colnames() 함수를 사용해 열 이름만 확인할 수도 있습니다.
- 이러한 함수들은 데이터 프레임의 대략적인 정보를 얻는 데 유용합니다.
- 데이터 프레임 수정: mutate 함수
- mutate() 함수는 데이터 프레임에 새로운 열을 추가하거나 기존 열을 수정할 때 사용됩니다.
- 예를 들어, diamonds 데이터 세트에서 carat 값을 읽기 쉽게 하기 위해 carat 열에 100을 곱한 새로운 열 carat_2를 생성할 수 있습니다.
- 이때, 새 열을 추가하더라도 기존 열은 삭제되지 않고 그대로 유지됩니다.
- 결론
- 데이터 분석의 대부분은 데이터 프레임을 다루는 것에서 시작되므로, 데이터 프레임을 생성하고 수정하는 방법을 아는 것은 매우 중요합니다.
데이터 가져오기 기본사항
data() 함수
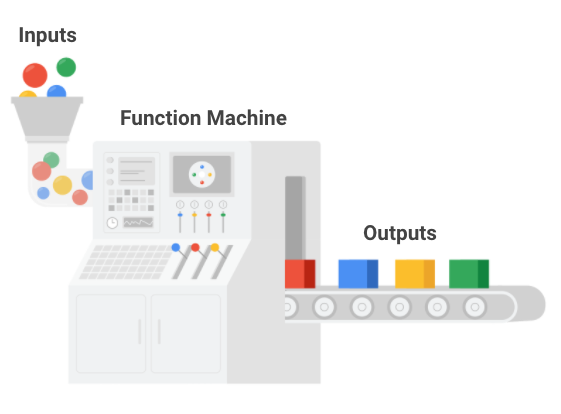
R을 설치하면 연습을 위해 미리 로드된 여러 데이터 세트가 기본적으로 제공됩니다. 연습은 R 스킬을 발전시키고 중요한 데이터 분석 함수를 배우는 데 큰 도움이 됩니다. 또한 많은 온라인 리소스와 튜토리얼에서도 이러한 샘플 데이터 세트를 사용하여 R의 코딩 개념을 설명합니다.
data() 함수를 사용하면 R에서 샘플 데이터 세트를 로드할 수 있습니다. 인수 없이 data 함수를 실행하는 경우 R에서 사용 가능한 데이터 세트의 목록을 표시합니다.
data()
여기에는 datasets 패키지의 미리 로드된 데이터 세트 목록도 포함됩니다.
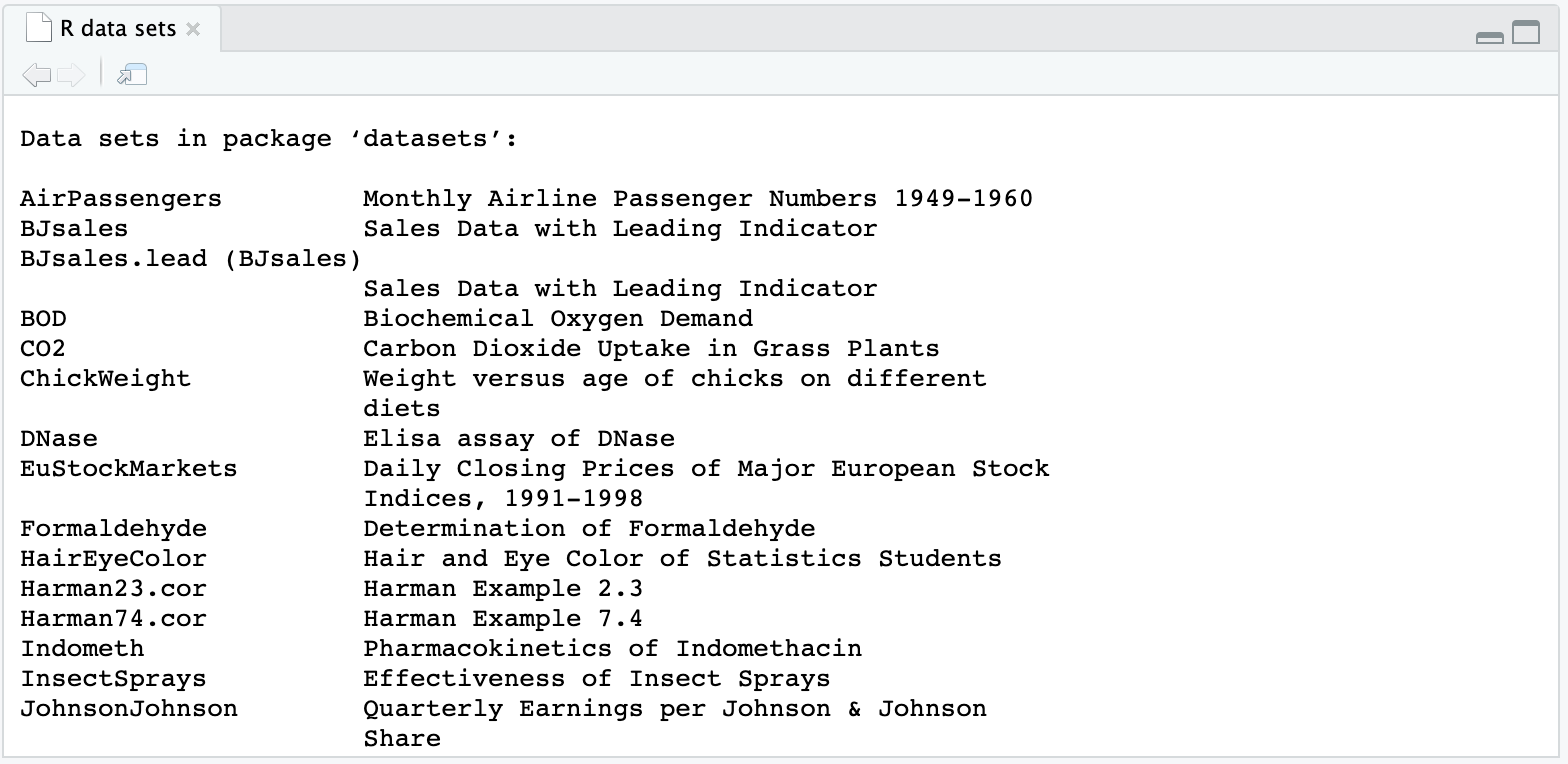
특정 데이터 세트를 로드하려면 data() 함수의 괄호 안에 이름을 입력하기만 하면 됩니다. 예를 들어 Motor Trend 잡지의 이전 호에 실린 자동차 관련 정보를 담은 mtcars 데이터 세트를 로드해보겠습니다.
data(mtcars)
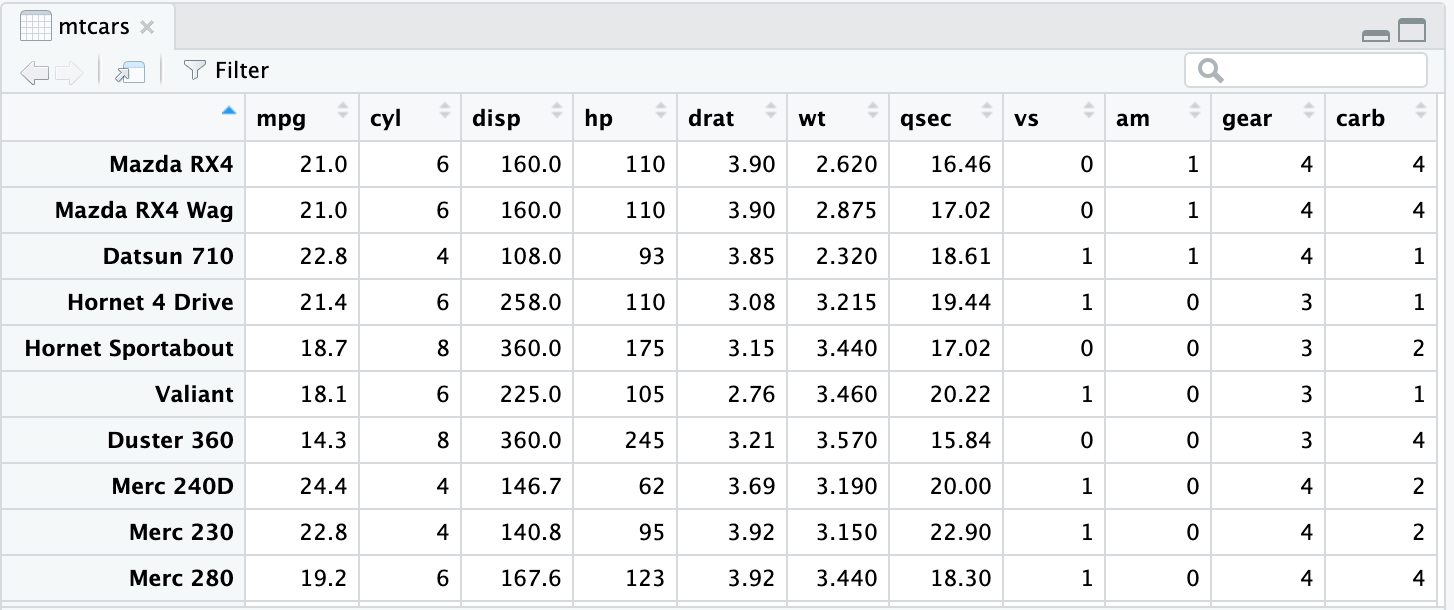
함수를 실행하면 R에서 해당 데이터 세트를 로드합니다. 데이터 세트는 RStudio의 환경 창에도 표시됩니다. 환경 창에는 데이터 프레임이나 변수 등 현재 작업공간에 있는 데이터 객체의 이름이 표시됩니다. 다음 이미지에서 mtcars는 창의 다섯 번째 행에 있습니다. R은 해당 데이터 세트에 32개의 관측값과 11개의 변수가 있다고 알려줍니다.
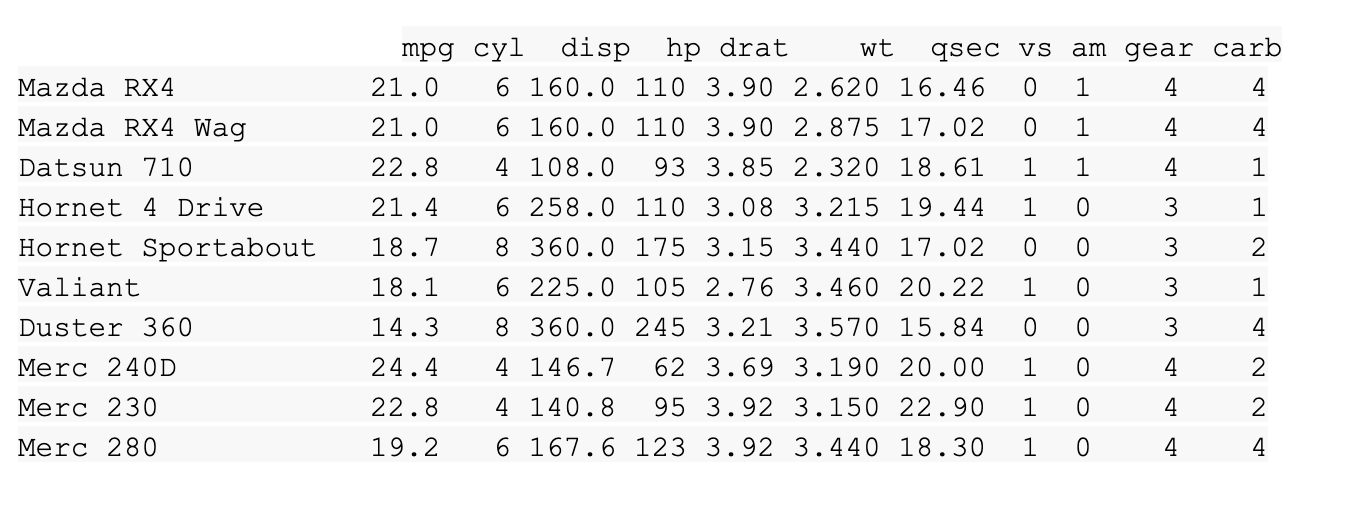
데이터 세트를 로드했으니 R 콘솔 창에 미리보기를 표시할 수 있습니다. 다음 이름을 입력합니다.
mtcars
그런 다음 Ctrl(또는 Cmnd)과 Enter 키를 누릅니다.
환경 창에서 데이터 세트의 이름을 직접 클릭하여 데이터 세트를 표시하는 방법도 있습니다. 환경 창에서 mtcars를 클릭하면 R에서 자동으로 View() 함수를 실행하고 RStudio 데이터 뷰어에 데이터 세트를 표시합니다.
더 연습해보려면 목록에 있는 다른 데이터 세트를 사용해보세요.
readr 패키지
R에 기본 제공되는 데이터 세트가 아닌 다른 소스에서 데이터를 가져와서 연습이나 분석을 위해 사용할 수도 있습니다. R의 readr 패키지는 직사각형 데이터를 읽는 데 좋은 도구입니다. 직사각형 데이터란 직사각형 모양의 행과 열 안에 꼭 맞게 들어가는 데이터로 각 열이 하나의 변수를, 각 행이 하나의 관측값을 나타냅니다.
직사각형 데이터를 저장하는 파일 형식의 예는 다음과 같습니다.
- .csv(쉼표로 구분된 값): .csv 파일은 데이터 목록이 포함된 일반 텍스트 파일입니다. 주로 쉼표(또는 구분자)로 데이터를 구분하지만 세미콜론과 같은 문자를 사용하기도 합니다.
- .tsv(탭으로 구분된 값): .tsv 파일은 데이터 열이 탭으로 구분된 데이터 테이블을 저장합니다. 예로는 데이터베이스 테이블 또는 스프레드시트 데이터가 있습니다.
- .fwf(고정 너비 파일): .fwf 파일은 텍스트 데이터를 구성된 방식으로 저장할 수 있는 특정 형식입니다.
- .log: .log 파일은 운영체제 및 기타 소프트웨어 프로그램의 이벤트를 기록하는 컴퓨터 생성 파일입니다.
Base R에도 파일을 읽는 함수가 있지만 그에 상응하는 readr의 함수들이 훨씬 빠릅니다. readr의 함수는 사용하거나 읽기 쉬운 tibble도 만들 수 있습니다.
readr 패키지는 핵심 tidyverse의 일부입니다. 따라서 이미 tidyverse를 설치했다면 바로 readr로 작업할 수 있습니다. 아직 설치하지 않았다면 지금 tidyverse를 설치하세요.
readr 함수
readr은 직사각형 데이터를 빠르고 쉽게 읽는 방법을 제공하는 역할을 하며, 몇 가지 read_ 함수를 지원합니다. 각 함수는 특정 파일 형식을 나타냅니다.
- read_csv(): 쉼표로 구분된 값(.csv) 파일
- read_tsv(): 탭으로 구분된 값 파일
- read_delim(): 일반 구분자 파일
- read_fwf(): 고정 너비 파일
- read_table(): 열이 공백으로 구분되는 표 형식의 파일
- read_log(): 웹 로그 파일
이러한 함수는 구문이 서로 비슷하기 때문에 한 가지 함수의 사용 방법을 배우면 응용하여 나머지 함수도 사용할 수 있습니다. .csv 파일은 흔한 데이터 저장 형식 중 하나이며, 앞으로 자주 사용할 것이므로 이 읽기 자료에서는 read_csv() 함수를 중점적으로 다룹니다.
대부분의 경우 readr 함수는 자동으로 작동합니다. 파일 경로를 입력하고 함수를 실행하면 파일의 데이터를 표시하는 tibble이 반환됩니다. 이때 readr 함수는 전체 파일을 파싱하고 각 열을 문자 벡터에서 가장 적합한 데이터 유형으로 변환할 방법을 지정합니다.
readr로 .csv 파일 읽기
readr 패키지에는 기본 제공된 데이터 세트의 샘플 파일이 포함되어 있어 예시 코드에 사용해볼 수 있습니다. 샘플 파일 목록을 보려면 readr_example() 함수를 인수 없이 실행하세요.
readr_example()
[1] "challenge.csv" "epa78.txt" "example.log"
[4] "fwf-sample.txt" "massey-rating.txt" "mtcars.csv"
[7] "mtcars.csv.bz2" "mtcars.csv.zip"
‘mtcars.csv’ 파일은 앞서 말한 mtcars 데이터 세트입니다. read_csv() 함수로 ‘mtcars.csv’ 파일을 읽어보겠습니다. 괄호 안에 파일 경로를 입력합니다. 이 경우에는 ‘readr_example(“mtcars.csv”)’입니다.
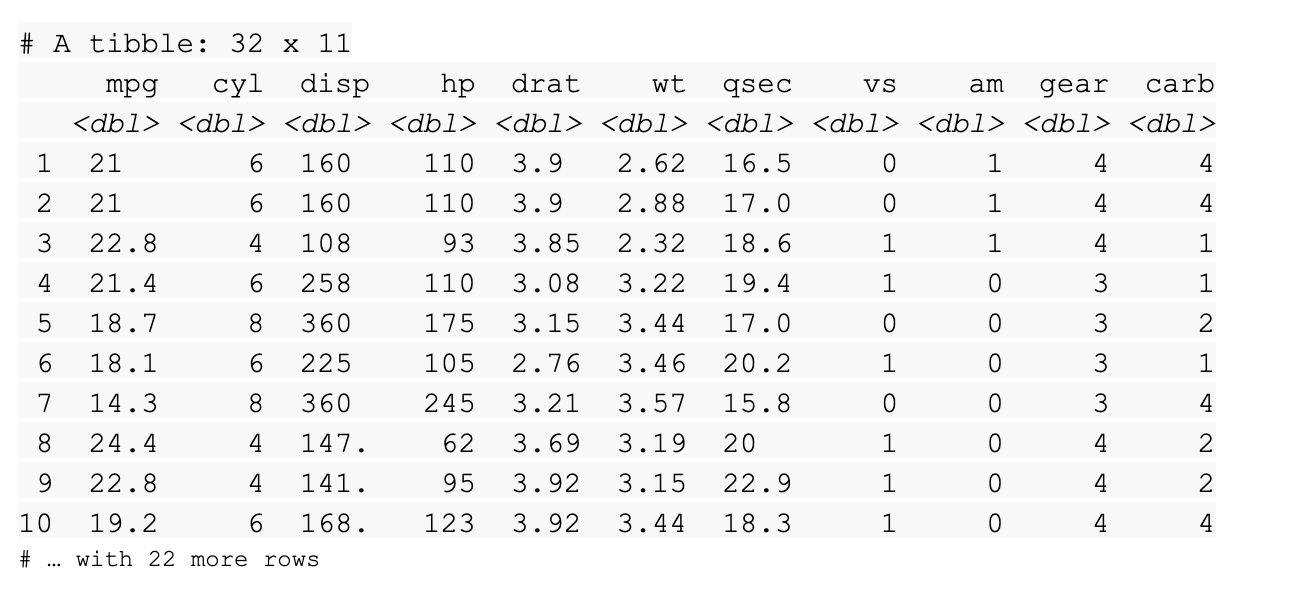
read_csv(readr_example("mtcars.csv"))
함수를 실행하면 R에서 각 열의 이름과 유형을 설명하는 열 사양을 출력합니다.

tibble도 출력합니다.
------------------------------------------------------------------------------------------------------
선택사항: readxl 패키지
readxl 패키지를 사용하여 R로 스프레드시트 데이터를 가져올 수 있습니다. readxl 패키지를 사용하면 Excel에서 R로 데이터를 쉽게 전송할 수 있습니다. readxl은 기존 .xls 파일 형식과 최신 xml 기반 .xlsx 파일 형식을 모두 지원합니다.
readxl 패키지는 tidyverse의 일부지만, 핵심 tidyverse 패키지는 아니기 때문에 R에서 readxl을 로드하려면 library() 함수를 실행해야 합니다.
library(readxl)
readxl로 .csv 파일 읽기
readr 패키지처럼 readxl에도 연습에 사용하도록 기본 제공된 데이터 세트의 샘플 파일이 포함되어 있습니다. 목록을 보려면 readxl_example() 코드를 실행하면 됩니다.
read_csv() 함수를 사용해 .csv 파일을 읽었던 것처럼 read_excel() 함수를 사용하여 스프레드시트 파일을 읽을 수 있습니다. 예시 파일 ‘type-me.xlsx’를 읽기 위한 코드의 함수 괄호 안에 파일 경로를 입력합니다. read_excel(readxl_example("type-me.xlsx"))
excel_sheets() 함수를 사용하면 개별 시트의 이름 목록이 나옵니다.
excel_sheets(readxl_example("type-me.xlsx"))
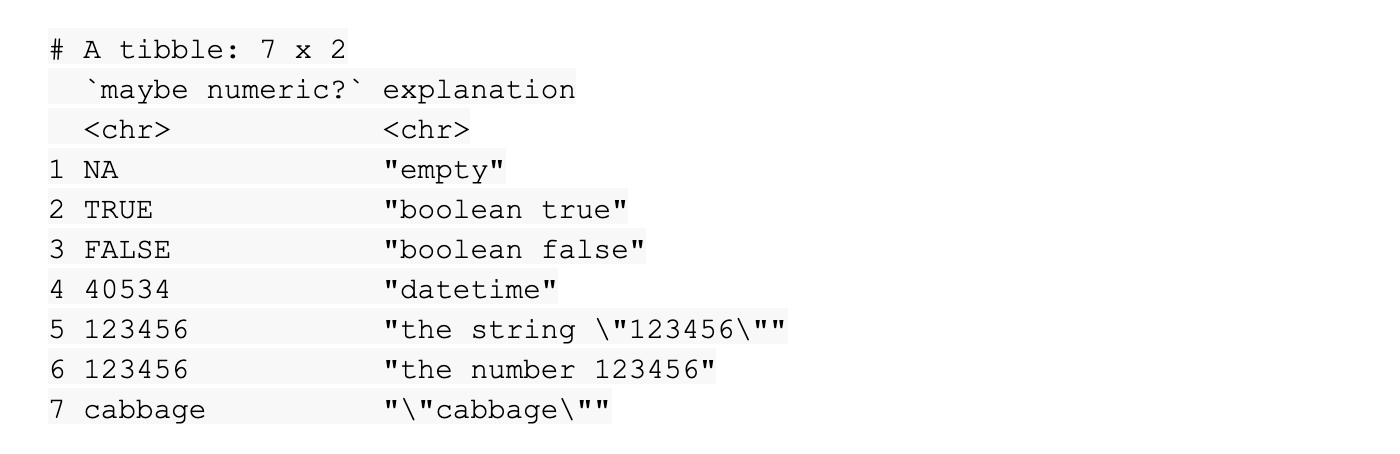
[1] "logical_coercion" "numeric_coercion" "date_coercion" "text_coercion"
이름 또는 번호로 시트를 지정할 수도 있습니다. ‘sheet =’ 뒤에 시트 이름 또는 번호를 입력하세요. 예를 들어 위 목록에 있는 ‘numeric_coercion’ 시트를 사용해보겠습니다.
read_excel(readxl_example("type-me.xlsx"), sheet = "numeric_coercion")
함수를 실행하면 R에서 시트의 tibble을 반환합니다.
추가 리소스
- readr 함수로 보다 복잡한 파일을 처리하는 방법을 배우려면 ‘R for Data Science’의 Data Import 장을 참고하세요. 파일을 읽을 때 발생할 수 있는 몇 가지 일반적인 문제와 readr을 사용하여 이러한 문제를 처리하는 방법을 살펴볼 수 있습니다.
- tidyverse 문서의 readxl에서 readxl의 기본 함수에 관한 간단한 개요, 패키지 작동 방식과 관련 코딩 개념의 자세한 설명, 유용한 기타 리소스 링크를 확인할 수 있습니다.
- R ‘datasets’ 패키지 안에는 미리 로드된 유용한 데이터 세트가 많습니다. The R Datasets Package에서 미리 로드된 데이터 세트 목록을 확인하세요. 목록에는 각 데이터 세트에 관한 자세한 설명으로 연결되는 링크가 포함되어 있습니다.
데이터 정리
정리를 위한 기본사항
R에서 데이터 정리, 표준화, 열 조작 및 시각화 요약
- 데이터 정리의 중요성
- 데이터 애널리스트의 중요한 작업 중 하나는 데이터 정리입니다.
- 데이터를 정리하고 표준화하여 분석에 적합한 형태로 만드는 과정이 필요합니다.
- 패키지 설치 및 사용
- 이번에는 데이터를 정리하는 데 유용한 몇 가지 패키지를 설치해보겠습니다.
- here: 파일 경로 참조를 쉽게 만들어주는 패키지. install.packages("here") 명령어로 설치 후 library(here)로 로드.
- skimr: 데이터를 빠르게 요약해주는 패키지. 데이터 세트를 빠르게 훑어보는 데 유용. install.packages("skimr") 명령어로 설치.
- janitor: 데이터 정리 작업을 간소화하는 패키지. install.packages("janitor") 명령어로 설치.
- dplyr: 데이터 조작을 돕는 패키지. 데이터 프레임 작업에 자주 사용됨.
- 이번에는 데이터를 정리하는 데 유용한 몇 가지 패키지를 설치해보겠습니다.
- 데이터 세트 로드
- palmerpenguins 데이터 세트를 사용하여 실습합니다. 이 데이터에는 남극 팔머 군도에 서식하는 펭귄 세 종에 대한 정보가 포함되어 있습니다.
- 데이터 프레임의 열을 정리하고 분석하는 다양한 함수를 적용할 수 있습니다.
- 데이터 요약 및 열 정리 함수
- skim_without_charts(): 데이터 세트의 전체 요약을 제공합니다. 열의 유형, 데이터의 개요 등을 반환합니다.
- glimpse(): 데이터 세트의 간략한 개요를 확인할 수 있습니다.
- head(): 첫 몇 행을 출력하여 데이터 세트를 미리보기합니다.
- select(): 특정 열만 선택하여 표시하거나, 제외하고 싶을 때 사용합니다. 예를 들어, select(-species)는 species 열을 제외하고 나머지를 표시합니다.
- 열 이름 변경 및 표준화
- rename(): 열 이름을 수동으로 변경할 때 사용합니다. 예를 들어, rename(island_new = island)은 island 열을 island_new로 변경합니다.
- rename_with(): 열 이름을 일괄적으로 변경할 때 사용됩니다. 대문자 또는 소문자로 변환하는 등의 작업이 가능합니다.
- clean_names(): 열 이름의 일관성을 자동으로 확인하고, 모든 열 이름이 고유하고 깔끔하게 만들어집니다. 특수 문자나 공백을 제거하고, 밑줄만 남깁니다.
- 데이터 정리 실습
- 직접 palmerpenguins 데이터로 연습해보는 것이 중요합니다. 이번 시간에는 데이터를 정리하고 열을 조작하는 다양한 방법을 배웠습니다.
- 결론
- 데이터를 정리하고 표준화하는 과정은 데이터 분석의 중요한 부분입니다. R에서 제공하는 다양한 패키지와 함수를 통해 데이터를 보다 효율적으로 다룰 수 있습니다.
R 연산자 자세히 알아보기
앞서 연산자란 수식에서 수행할 연산이나 계산 유형을 보여주는 기호라고 배웠습니다. 이전 동영상에서는 대입 및 산술 연산자를 사용해 변수를 대입하고 계산을 수행하는 방법을 배웠습니다. 이 읽기 자료에서는 R의 주요 연산자 유형에 관한 자세한 요약을 살펴보고 R 코드에서 특정 연산자를 사용하는 방법을 배웁니다.
연산자
R의 주요 연산자는 다음 네 가지입니다.
- 산술 연산자
- 관계 연산자
- 논리 연산자
- 대입 연산자
각 카테고리에 해당하는 구체적인 연산자를 살펴보고 예시를 통해 R 코드에서 연산자를 사용하는 방법을 확인해보세요.
산술 연산자
산술 연산자로는 덧셈, 뺄셈, 곱셈, 나눗셈 등의 기본적인 수학 연산을 수행할 수 있습니다.
다음 표에는 R에서 사용하는 다양한 산술 연산자가 요약되어 있습니다. 표에 제시된 예는 두 변수 ‘x는 2이고 y는 5이다’의 생성을 전제로 합니다. 다음과 같이 대입 연산자를 사용해 값을 저장합니다.
x <- 2
y <- 5
| 연산자 | 설명 | 예시 코드 | 결과/출력값 |
| + | 덧셈 | x + y | [1] 7 |
| - | 뺄셈 | x - y | [1] -3 |
| * | 곱셈 | x * y | [1] 10 |
| / | 나눗셈 | x / y | [1] 0.4 |
| %% | 나머지(나눗셈 후 나머지 반환) | y %% x | [1] 1 |
| %/% | 정수 나눗셈(나눗셈 후 정숫값 반환) | y%/% x | [1] 2 |
| ^ | 지수 | y ^ x | [1]25 |
관계 연산자
관계 연산자는 비교 연산자로고도 알려져 있으며 값을 비교하는 데 사용합니다. 관계 연산자는 R 객체 간의 관계를 규명합니다. 즉, 한 객체가 다른 객체보다 작거나 큰지, 서로 같은지 확인합니다. 관계 연산자의 출력값은 TRUE 또는 FALSE(논리적 데이터 유형, 즉 불리언)입니다.
다음 표에는 R에서 사용하는 6개의 관계 연산자가 요약되어 있습니다. 표에 제시된 예는 두 변수 ‘x는 2이고 y는 5이다’의 생성을 전제로 합니다. 다음과 같이 대입 연산자를 사용해 값을 지정합니다.
x <- 2
y <- 5
각 연산자로 계산을 수행하면 다음과 같은 결과를 얻게 됩니다. 이 경우 출력값은 불리언, 즉 TRUE 또는 FALSE입니다. 각 출력값 앞의 [1]은 RStudio에서 출력값이 어떻게 표시되는지 보여주기 위해 사용되었습니다.
| 연산자 | 설명 | 예시 코드 | 결과/출력값 |
| < | (왼쪽이 오른쪽보다) 작다 | x < y | [1] TRUE |
| > | (왼쪽이 오른쪽보다) 크다 | x > y | [1] FALSE |
| <= | (왼쪽이 오른쪽보다) 작거나 같다 | x < = 2 | [1] TRUE |
| >= | (왼쪽이 오른쪽보다) 크거나 같다 | y >= 10 | [1] FALSE |
| == | 같다 | y == 5 | [1] TRUE |
| != | 같지 않다 | x != 2 | [1] FALSE |
논리 연산자
논리 연산자를 사용하면 논릿값을 결합할 수 있습니다. 논리 연산자는 논리적 데이터 유형, 즉 불리언(TRUE 또는 FALSE)을 반환합니다. 앞의 읽기 자료인 논리 연산자 및 조건문에서 논리 연산자를 이미 살펴봤으나 간단히 복습해보세요.
다음 표에는 R에서 사용하는 논리 연산자가 요약되어 있습니다.
| 연산자 | 설명 |
| & | 요소별 논리 AND |
| && | 논리 AND |
| | | 요소별 논리 OR |
| || | 논리 OR |
| ! | 논리 NOT |
이제 몇 가지 예시를 통해 R 코드에서 논리 연산자가 작동하는 방법을 살펴보겠습니다.
요소별 논리 AND(&) 및 OR(|)
논리 AND(&) 및 OR(|)은 수치 비교를 통해 설명할 수 있습니다. 먼저 변수 x의 값이 10인 식을 만듭니다.
x <- 10
AND 연산자는 개별 값이 둘 다 TRUE인 경우에만 TRUE를 반환합니다.
x > 2 & x < 12
[1] TRUE
10은 2보다 큽니다. 그리고 10은 12보다 작습니다. 따라서 연산은 TRUE로 평가됩니다.
OR 연산자(|)는 AND 연산자(&)와 비슷하게 작동합니다. 가장 큰 차이는 OR 연산에서 단 하나의 값이 TRUE이면 OR 연산 전체가 TRUE로 평가된다는 점입니다. 값이 둘 다 FALSE인 경우에만 전체 OR 연산이 FALSE로 평가됩니다.
같은 변수 (x <- 10)를 가지고 다른 예를 들어보겠습니다.
x > 2 | x < 8
[1] TRUE
10은 2보다 큽니다. 하지만 10은 8보다 작지 않습니다. 최소 하나의 값(10>2)이 TRUE이므로 OR 연산은 TRUE로 평가됩니다.
논리 NOT(!)
NOT 연산자는 단순히 논릿값을 부정하고 반대로 평가합니다. R에서 0은 FALSE로 간주되며 0이 아닌 모든 숫자는 TRUE로 간주됩니다.
앞에서 만든 변수(x <- 10)에 NOT 연산자를 적용해보겠습니다.
!(x < 15)
[1] FALSE
NOT 연산은 x < 15 문의 논릿값인 TRUE(10은 15보다 작음)의 반대 논릿값을 취하므로 FALSE로 평가됩니다.
대입 연산자
대입 연산자를 사용하면 변수에 값을 대입할 수 있습니다.
많은 스크립트 프로그래밍 언어에서는 등호(=)를 사용하면 간단히 변수를 대입할 수 있습니다. R에서는 화살표 대입 기호 사용(<-)이 권장됩니다. 원칙적으로 단일 화살표 대입 기호는 왼쪽 방향과 오른쪽 방향 모두 사용할 수 있습니다. 그러나 오른쪽 기호는 R 코드에서 잘 사용하지 않습니다.
범위 대입이라고 알려진 이중 화살표 대입 기호도 사용할 수 있습니다. 그러나 범위 대입은 고급 R 사용자에게 적합하기 때문에 이 읽기 자료에서는 다루지 않습니다.
다음 표에는 R의 대입 연산자와 예시 코드가 요약되어 있습니다. 각 변수의 출력값은 변수의 대입 값이 됩니다.
| 연산자 | 설명 | 예시 코드(아래의 샘플 코드를 실행한 후 x를 입력하면 오른쪽 열의 출력값이 반환됨) | 결과/출력값 |
| <- | 왼쪽으로 대입 | x <- 2 | [1] 2 |
| <<- | 왼쪽으로 대입 | x <<- 7 | [1] 7 |
| = | 왼쪽으로 대입 | x = 9 | [1] 9 |
| -> | 오른쪽으로 대입 | 11 -> x | [1] 11 |
| ->> | 오른쪽으로 대입 | 21 ->> x | [1] 21 |
이 읽기 자료에서 배운 연산자는 R 연산자를 사용하는 데 좋은 토대가 될 것입니다.
추가 리소스
R Coder 웹사이트의 R Operators는 다양한 유형의 R 연산자에 관한 종합 가이드입니다. 이 게시글에는 유용한 코딩 예시와 함께 기타 연산자, 중위 연산자, 파이프 연산자에 관한 다양한 정보가 포함되어 있습니다.
데이터 구성
데이터 구성과 필터링: arrange, group_by, filter
1. 데이터 정렬 - arrange 함수
- 기능: 데이터를 지정된 열의 값을 기준으로 정렬.
- 사용법: arrange(data, 열 이름) 명령을 사용하여 데이터를 정렬.
- 예: arrange(penguins, bill_length) → 부리 길이를 기준으로 오름차순 정렬.
- 내림차순 정렬: 열 이름 앞에 -를 추가 (arrange(penguins, -bill_length)).
- 데이터 저장: 정렬된 데이터를 데이터 프레임으로 저장하려면 변수 이름을 지정하여 할당.
- 예: penguins2 <- arrange(penguins, bill_length)
2. 데이터 그룹화 - group_by 함수
- 기능: 데이터를 특정 기준으로 그룹화하여 요약 통계를 계산할 때 사용.
- 사용법: group_by(data, 열 이름)으로 그룹을 지정한 후, summarize()를 사용해 통계값 계산.
- 예: penguins %>% group_by(island) %>% summarize(mean_bill_length_mm = mean(bill_length, na.rm = TRUE))
- NA 처리: drop_na()를 사용해 누락된 데이터를 제외할 수 있음.
- 다중 그룹화: 여러 열을 기준으로 그룹화 가능. 그룹마다 통계값 계산 가능.
- 예: penguins %>% group_by(species, island) %>% summarize(mean_bill_length_mm = mean(bill_length, na.rm = TRUE), max_bill_length_mm = max(bill_length, na.rm = TRUE))
3. 데이터 필터링 - filter 함수
- 기능: 특정 조건에 맞는 데이터를 필터링하여 추출.
- 사용법: filter(data, 조건) 형식으로 사용. 조건에는 ==을 사용하여 정확한 일치를 지정.
- 예: filter(penguins, species == "Adelie") → 아델리 펭귄의 데이터만 추출.
- 활용: 분석 범위를 좁혀 특정 데이터를 집중적으로 다룰 때 유용.
선택사항: 데이터 프레임 수동 생성
다음 동영상에서는 R에서 데이터를 변환하는 방법을 배워보겠습니다. 이 동영상에서는 R 패키지의 데이터 세트 대신 수동으로 입력한 데이터를 사용합니다.
동영상을 따라 여러분의 RStudio 콘솔에서 실습하려면 다음 코드를 복사하고 붙여넣어 데이터를 입력하고 데이터 프레임을 생성해보세요.
id <- c(1:10)
name <- c("John Mendes", "Rob Stewart", "Rachel Abrahamson", "Christy Hickman", "Johnson Harper", "Candace Miller", "Carlson Landy", "Pansy Jordan", "Darius Berry", "Claudia Garcia")
job_title <- c("Professional", "Programmer", "Management", "Clerical", "Developer", "Programmer", "Management", "Clerical", "Developer", "Programmer")
employee <- data.frame(id, name, job_title)
이렇게 하면 동영상에 나오는 함수를 여러분의 콘솔에서 실행하여 R에서 데이터를 변환하고 정리하는 과정을 연습하실 수 있습니다. 동영상을 따라 연습하면 함수의 원래 작동 방식을 살펴보면서 직접 함수를 실행하는 데 도움이 됩니다. 또한 동영상이 끝난 후에도 이 데이터 프레임을 사용해 더 연습해볼 수 있습니다.
데이터 변환
데이터 변환: separate, unite, mutate
1. 열 분리 - separate 함수
- 기능: 하나의 열에 있는 데이터를 여러 개의 열로 분리할 수 있음.
- 사용법:
- 데이터 프레임에서 하나의 열을 선택하여 원하는 기준으로 여러 열로 나눔.
- 예: 직원 이름이 포함된 열을 성(first_name)과 이름(last_name)으로 분리.
- separate(data, column, into = c("new_column1", "new_column2"))를 사용해 공백 등을 기준으로 열을 나누어 저장.
- 결과: 'first_name'과 'last_name' 열이 새롭게 생성됨.
2. 열 병합 - unite 함수
- 기능: 여러 개의 열을 하나로 병합.
- 사용법:
- 예: 성(first_name)과 이름(last_name)을 결합하여 하나의 이름(full_name) 열로 생성.
- unite(data, "new_column", c(column1, column2), sep = " ")로 열을 병합하고 공백이나 구분자를 설정할 수 있음.
- 결과: 병합된 'full_name' 열이 생성됨.
3. 새로운 변수 추가 - mutate 함수
- 기능: 데이터 프레임에 새로운 열을 추가하거나 기존 데이터를 변환할 때 사용.
- 사용법:
- 새로운 계산된 변수나 변환된 값을 추가.
- 예: 펭귄 데이터에서 체질량을 그램(body_mass_g)에서 킬로그램으로 변환한 새 열(body_mass_kg) 추가.
- mutate(data, new_column = calculation) 형식으로 새 열을 추가 가능.
- 여러 변수를 동시에 추가할 수도 있음.
separate 함수로 열을 분리하고, unite 함수로 열을 병합하며, mutate 함수로 계산된 열을 추가하는 방법을 배웠습니다. 이를 통해 데이터를 효율적으로 변환할 수 있으며, 데이터 변환을 통해 분석의 폭을 넓힐 수 있습니다.
tidyr을 사용해 가로형에서 세로형으로 변환
R을 사용하여 데이터를 구성하거나 정리하다 보면 가로형 데이터를 세로형 데이터로 또는 그 반대로 변환해야 하는 경우가 있습니다. 잠깐 복습하자면 스프레드시트의 가로형 데이터는 다음과 같습니다.

가로형 데이터의 경우 관측값이 여러 열에 있습니다. 각 열에는 변수의 조건별 데이터가 포함됩니다. 이 예에서는 연도가 조건에 해당합니다.
이제 같은 데이터를 세로형으로 보겠습니다.
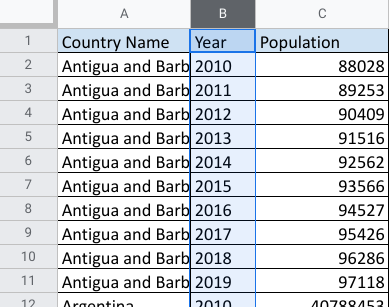
앞서 배운 차이점을 복습해보자면 세로형 데이터에서는 모든 관측값이 하나의 열에 포함되고 변수는 각기 다른 열에 포함됩니다.
pivot_longer 및 pivot_wider 함수

두 형식 모두 유용합니다. 그러나 애널리스트는 필요에 따라 어떤 데이터 정리 방법이 알맞을지 판단해야 합니다. R에서는 여러 변수와 각 변수의 조건이 포함된 가로형 데이터 프레임이 표시될 텐데 다소 복잡해 보일 수 있습니다.
이럴 때 pivot_longer()를 사용하면 됩니다. tidyr 패키지에 속한 이 R 함수를 사용하면 행 수를 늘리고 열 수를 줄여 데이터의 데이터 프레임을 세로형으로 만들 수 있습니다. 마찬가지로 열 수를 늘리고 행 수를 줄이도록 데이터를 변환하고 싶은 경우 pivot_wider() 함수를 사용하면 됩니다.
추가 리소스
두 가지 함수와 이를 R 프로그래밍에 적용하는 방법을 자세히 알아보려면 다음 리소스를 참고하세요.
- Pivoting: 가로형 및 세로형 변환을 통해 데이터를 정리하는 출발점으로 활용하기에 유용한 리소스입니다. 이 웹페이지에는 tidyverse.org에서 직접 가져온 tidyr 패키지 정보가 나와 있습니다. 구체적인 세부정보, 예시, 정의를 사용해 pivot_longer 및 pivot_wider 함수의 구성요소를 설명합니다.
- CleanItUp 5: R-Ladies Sydney: Wide to Long to Wide to…PIVOT: pivot_longer 및 pivot_wider 함수의 추가 세부정보를 다루는 리소스입니다. 흥미로운 데이터 세트 예시를 통해 데이터를 가로형에서 세로형으로 변환한 후 다시 가로형으로 변환하는 방법을 설명합니다.
- Plotting multiple variables: 데이터 정리를 위해 ggplot2를 사용하여 가로형 및 세로형 데이터를 시각화하는 방법을 설명하는 리소스입니다. pivot_longer를 사용하여 데이터를 재구성하고 여러 변수의 유사한 플롯을 한 번에 만드는 방법을 중점적으로 다룹니다. 이러한 외부 리소스에서 알게 된 내용을 토대로 pivot 함수를 더욱 폭넓게 이해할 수 있습니다.
데이터 자세히 살펴보기
같은 데이터, 다른 결과
앤스컴 콰르텟을 통한 데이터 요약 및 시각화
1. 앤스컴 콰르텟 데이터 세트
- 특징: 4개의 데이터 세트로 이루어져 있으며, 요약 통계(평균, 표준 편차, 상관관계)가 거의 동일하지만 데이터의 형태는 서로 다름.
- 목표: 요약 통계만으로는 데이터를 잘못 해석할 수 있으므로, 데이터를 시각화하여 각 데이터 세트의 숨겨진 차이를 발견하는 것이 중요함.
2. 데이터 요약
- 그룹화 및 요약:
- 데이터를 그룹화하고 summarize 함수를 사용해 각 데이터 세트의 평균, 표준 편차, 상관관계를 요약.
- x의 평균은 9, y의 평균은 7.5이며, x와 y의 표준 편차는 각각 3.32, 2.03, 상관관계는 0.816로 동일.
- 이러한 통계적 요약은 네 세트가 동일하다고 오해할 수 있음.
3. 데이터 시각화
- 목적: 시각화를 통해 4개의 데이터 세트가 실제로는 매우 다르다는 사실을 확인함.
- 그래프 생성: 간단한 그래프를 생성하여 각 데이터 세트의 모양을 비교. 시각적으로는 네 세트가 모두 다른 패턴을 가짐.
- 시각화의 중요성: 요약 통계만으로는 숨겨진 차이를 알기 어려우며, 시각화는 이러한 차이를 명확하게 보여줌.
4. datasauRus 패키지
- 추가 기능: datasauRus 패키지를 사용하여 데이터 플롯을 다양한 모양으로 생성.
- 예시: 공룡, 황소의 눈, 별 모양 등의 다양한 형태를 플로팅하며, R의 시각화 능력을 보여줌.
bias 함수
편향 없는 데이터 분석
1. 데이터의 편향성
- 편향 확인의 중요성: 데이터가 편향되면 잘못된 예측이나 결정을 내릴 수 있음. 따라서 편향을 확인하고 조정하는 것이 중요함.
- R에서의 편향 계산: bias 함수를 사용하여 실제 결과와 예측 결과를 비교하고, 평균적으로 예측이 얼마나 편향되었는지 확인할 수 있음.
2. bias 함수 사용법
- sim design 패키지: 편향 계산을 위한 bias 함수는 sim design 패키지에 포함되어 있으며, 패키지를 설치하고 로드해야 함.
- bias 함수의 역할: 실제 결과와 예측 결과 간의 차이를 정량화하여 평균적인 편향을 계산함.
- 편향이 없으면 결과는 0에 가까움.
- 편향이 크면 데이터가 왜곡되었거나, 예측에 오류가 있을 가능성이 큼.
3. 예제 1: 지역 일기 예보 편향 확인
- 실제 기온(actual_temp)과 예측 기온을 비교하여 편향을 계산함.
- bias 함수를 사용한 결과, 값은 0.71로 0에 가까워 약간의 편향이 있음을 보여줌. 예측 기온이 실제 기온보다 약간 낮게 편향됨.
4. 예제 2: 게임 매장에서의 재고 편향 확인
- **실제 판매량(actual_sales)과 예측 판매량(predicted_sales)**을 비교하여 편향을 계산.
- 결과값이 -35로 나타나, 예측 값이 실제 값보다 훨씬 크다는 것을 의미함. 즉, 너무 많은 재고를 주문하고 있음.
5. 결론
- 편향 확인의 중요성: bias 함수를 통해 실제 값과 예측 값의 차이를 확인함으로써, 데이터를 더 공정하고 정확하게 분석할 수 있음.
- R의 시각화와 더 많은 기능: 이번 시간에 배운 것처럼 R은 데이터 분석과 시각화에 강력한 도구를 제공하며, 앞으로 더 많은 시각화 방법을 배우게 될 예정.
R에서 편향을 정량화하는 방법을 학습했고, bias 함수를 활용해 예측 데이터와 실제 데이터를 비교하는 과정을 배웠습니다. 데이터를 분석할 때, 단순한 요약 통계만이 아닌 편향성을 확인하는 것이 중요하며, 이를 통해 데이터 분석의 신뢰성을 높일 수 있습니다. 다음 시간에는 R의 데이터 시각화에 대해 더 깊이 학습할 예정입니다.
데이터 편향 해결
데이터 애널리스트라면 누구나 데이터 분석 과정 중에 편향된 요소를 발견하게 됩니다. 따라서 어떤 단계에서든 데이터 편향을 식별하고 관리하는 방법을 알고 있어야 합니다. 앞서 3강에서 편향에 관해 자세히 살펴봤습니다. 이 읽기 자료에서는 데이터에서 편향을 발견한 애널리스트의 실제 사례를 살펴보고 R을 사용해 편향을 해결하는 방법을 배워봅니다.
R을 사용해 데이터 편향 해결
전 세계에서 인적 데이터를 수집하는 양적 애널리스트가 겪은 사례를 소개합니다. 애널리스트의 이야기를 통해 데이터에서 편향을 발견하여 R에서 편향을 해결한 내용을 확인해보세요.
“저는 설문조사 데이터를 수집하는 팀에서 일합니다. 팀에서는 나란히 비교한 결과를 수집하는 업무도 처리합니다. 예를 들어 사용자에게 두 광고를 동시에 나란히 보여준 후 설문조사에서 두 광고 중 무엇을 선호하는지 묻습니다. 한 사례에서 여러 번 반복한 끝에 첫 번째 항목을 선호하는 일관된 편향을 발견했습니다. 게다가 첫 번째 항목의 위치를 두 번째로 바꾸면 항목의 선호도가 눈에 띄게 감소했습니다.
따라서 R을 사용해 광고의 위치를 무작위로 지정하는 코드를 추가하기로 했으며, 이때 항목이 첫 번째와 두 번째 위치에 나타나는 빈도가 비슷해야 했습니다. sample() 함수를 사용해 R 프로그래밍에 요소를 무작위로 지정하는 코드를 추가했습니다. R에서 sample() 함수를 사용하면 데이터 세트 요소 중 일부를 무작위로 가져올 수 있습니다. 이 코드를 추가하여 데이터 세트의 행 순서를 무작위로 섞을 수 있었습니다. 결과적으로 사용자에게 광고를 게재할 때 광고의 위치가 무작위로 지정되어 편향을 제어할 수 있게 되었습니다. 이는 설문조사의 유효성을 개선하고 데이터의 신뢰성을 높였습니다.”
핵심 요약
sample() 함수는 R에서 데이터 편향을 해결하기 위해 사용할 수 있는 다양한 함수와 방법의 하나입니다. 실시하는 분석의 종류에 따라 프로그래밍에 고급 과정이 요구될 수도 있습니다. 여기에서는 고급 과정에 관해 자세히 다루지 않지만, 데이터 애널리틱스 분야에서 경험을 쌓다 보면 고급 과정에 관해 자세히 알게 되실 것입니다.
편향과 데이터 윤리에 관해 자세히 알아보려면 다음 리소스를 참고하세요.
- Data Science Ethics: 슬라이드, 동영상, 실습을 통해 데이터 애널리틱스 분야의 윤리에 관해 자세히 배울 수 있는 온라인 강좌입니다. 데이터 개인정보 보호 및 데이터 왜곡에 관한 정보와 시각화 윤리에 관해 확인할 수 있습니다.
- Bias function: R의 bias 함수가 분석에서 편향을 식별하고 관리하는 데 얼마나 유용한지 배우기에 좋은 출발점인 웹페이지입니다.