2024. 9. 30. 11:28ㆍGCC/데이터 애널리틱스

기본 프로그래밍 개념의 이해
프로그래밍 기본
R 기초 개념 학습
이번 스크립트에서는 R 프로그래밍의 기초 개념을 다루었습니다. 함수, 주석, 변수, 데이터 유형, 벡터, 파이프라는 여섯 가지 주요 개념이 중심이 되었습니다.
1. 함수
- 함수는 R에서 특정 작업을 처리하는 코드 묶음으로, 재사용 가능한 기능입니다. 함수는 함수명(인수) 형식으로 사용됩니다.
- 대표적인 예로 print 함수가 있으며, 괄호 안에 값을 입력하면 이를 출력합니다. 예: print('Coding in R')는 'Coding in R'이라는 문자열을 출력합니다.
- 함수의 작동 방식에 대한 도움말은 ?함수명을 통해 RStudio에서 확인할 수 있습니다.
2. 주석
- 주석은 코드의 가독성을 높이고, 코드의 목적을 설명하는 문장으로, # 기호를 앞에 붙여 작성합니다. 주석은 R에서 실행되지 않으며, 코드에 대한 설명을 덧붙이는 데 유용합니다.
3. 변수
- 변수는 값을 저장하고 이를 나중에 불러올 수 있게 해주는 도구입니다. 변수는 SQL에서도 활용된 바 있습니다. R에서 변수는 <- 연산자를 통해 값을 할당받습니다.
- 예: first_variable <- 'This is my variable'는 first_variable이라는 변수에 해당 문자열을 저장합니다.
- 변수명은 숫자로 시작할 수 없으며 소문자로 시작하는 것이 일반적입니다.
4. 데이터 유형
- R에서 다루는 데이터 유형에는 문자열, 숫자, 논리형(TRUE/FALSE), 날짜형 등이 있습니다. 변수에 데이터 유형을 할당하여 원하는 데이터 처리를 할 수 있습니다.
5. 벡터
- 벡터는 동일한 유형의 데이터를 순차적으로 저장한 요소 집합입니다. 벡터를 생성할 때는 c() 함수를 사용하며, 쉼표로 구분된 값을 넣어 구성합니다.
- 예: vec_1 <- c(1, 2, 3, 4)는 숫자 1, 2, 3, 4가 포함된 벡터를 생성합니다.
6. 파이프
- **파이프(%>%)**는 데이터를 연속적으로 처리할 수 있게 해주는 도구로, 한 함수의 출력을 다른 함수로 전달할 때 사용됩니다. 이를 통해 여러 명령을 연결해 더 간결하고 읽기 쉬운 코드를 작성할 수 있습니다.
R의 벡터와 리스트
프로그래밍에서 데이터 구조란 데이터를 구성하고 저장하기 위한 형식을 의미합니다. 데이터 분석에 R을 사용하는 경우 주로 데이터 구조를 기반으로 작업하기 때문에 데이터 구조를 이해해야 합니다. R 프로그래밍 언어에서 가장 일반적인 데이터 구조는 다음과 같습니다.
- 벡터
- 데이터 프레임
- 행렬
- 배열
데이터 구조를 데이터로 쌓은 집이라고 생각하세요.
이 읽기 자료에서는 벡터에 관해 중점적으로 살펴봅니다. 데이터 프레임, 행렬, 배열에 관해서는 나중에 자세히 배웁니다.
벡터에는 상수 벡터와 리스트의 두 가지 벡터 유형이 있습니다. 상수 벡터 및 리스트의 기본 속성과 R 코드를 사용하여 상수 벡터 및 리스트를 생성하는 방법을 배워보겠습니다.
상수 벡터
우선 다양한 유형의 상수 벡터를 살펴보겠습니다. 그런 다음 R 코드를 사용하여 벡터를 생성하고 식별하고 명명하는 방법을 배웁니다.
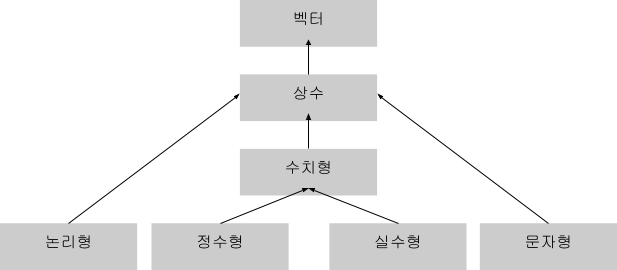
앞서 벡터는 R에 순차적으로 저장되는 동일한 유형의 데이터 요소군임을 배웠습니다. 벡터에는 논리형과 수치형 중 하나만 포함할 수 있습니다.
상수 벡터의 주요 유형은 논리형, 정수형, 실수형, 문자형(문자열 포함), 복소수형, 원시형 등 여섯 가지입니다. 복소수형과 원시형은 데이터 분석에서 흔히 사용되지 않으므로 나머지 네 가지 유형을 집중적으로 살펴봅니다. 정수형과 실수형 벡터는 둘 다 숫자를 포함하기 때문에 함께 수치형 벡터라고 합니다. 다음은 벡터의 네 가지 주요 유형을 요약한 표입니다.
| 유형 | 설명 | 예 |
| 논리형 | 참/거짓 | TRUE |
| 정수형 | 양의 정수 및 음의 정수 | 3 |
| 실수형 | 소수점 값 | 101.175 |
| 문자형 | 문자열/문자 값 | “Coding” |
다음은 벡터의 네 가지 주요 유형 간 계층 관계를 보여주는 다이어그램입니다.
벡터 생성
벡터를 생성하는 한 가지 방법은 c() 함수(‘결합’ 함수라고 함)입니다. R에서 c() 함수는 다수의 값을 하나의 벡터로 결합합니다. R에서 c() 함수를 사용하려면 ‘c’를 입력한 뒤 벡터에 넣을 값을 쉼표로 구분하여 괄호 안에 입력하면 됩니다. 예를 들면 c(x, y, z, ...)와 같습니다.
c() 함수를 사용하면 벡터 안에 수치 데이터를 저장할 수 있습니다.
c(2.5, 48.5, 101.5)
c() 함수로 정수형 벡터를 생성하려면 각 숫자 바로 뒤에 'L'을 입력해야 합니다.
c(1L, 5L, 15L)
문자 또는 논리가 포함된 벡터를 생성할 수도 있습니다.
c(“Sara” , “Lisa” , “Anna”)
c(TRUE, FALSE, TRUE)
벡터 속성 판정
생성하는 모든 벡터에는 유형과 길이라는 두 가지 주요 속성이 있습니다.
typeof() 함수를 사용하면 어떤 벡터 유형에서 작업 중인지 판정할 수 있습니다. 함수의 괄호 안에 벡터 코드를 입력합니다. 함수를 실행하면 유형이 표시됩니다. 예:
typeof(c(“a” , “b”))
#> [1] "character"
이 예시에서 typeof 함수의 출력은 “character”입니다. 마찬가지로 정숫값이 있는 벡터에 typeof 함수를 사용하면 출력은 “integer” 입니다.
typeof(c(1L , 3L))
#> [1] "integer"
length() 함수를 사용하면 기존 벡터의 길이, 즉 포함된 요소의 개수를 판정할 수 있습니다. 이 예시에서는 대입 연산자를 사용하여 벡터를 변수 x에 대입합니다. 그런 다음 length() 함수를 변수에 적용합니다. 함수를 실행하면 3 이 표시되어 벡터의 길이가 3임을 알 수 있습니다.
x <- c(33.5, 57.75, 120.05)
length(x)
#> [1] 3
is 함수를 사용하면 벡터가 특정 유형인지 확인할 수도 있습니다. is 함수로는 is.logical(), is.double(), is.integer(), is.character()가 있습니다. 이 예시에서는 벡터에 정수가 포함되어 있으므로 TRUE 가 반환됩니다.
x <- c(2L, 5L, 11L)
is.integer(x)
#> [1] TRUE
이 예시에서는 벡터에 문자가 포함되어 있지 않고 논리가 포함되어 있으므로 FALSE 가 반환됩니다.
y <- c(TRUE, TRUE, FALSE)
is.character(y)
#> [1] FALSE
벡터 명명
모든 유형의 벡터는 명명할 수 있습니다. R에서 이름은 코드의 가독성을 높이고 객체를 설명하는 데 도움이 됩니다. names() 함수로 벡터의 요소를 명명할 수 있습니다. 예를 들어 변수 x에 요소가 3개인 새 벡터를 대입해봅시다.
x <- c(1, 3, 5)
names() 함수를 사용하면 벡터의 요소별로 각기 다른 이름을 대입할 수 있습니다.
names(x) <- c("a", "b", "c")
이제 코드를 실행하면 벡터의 첫째 요소를 a, 둘째 요소를 b, 셋째 요소를 c 로 명명한 결과가 반환됩니다.
x
#> a b c
#> 1 3 5
상수 벡터는 동일한 유형의 요소만 포함할 수 있다는 점에 유의하세요. 같은 데이터 구조에 서로 다른 유형의 요소를 저장하려면 리스트를 사용하면 됩니다.
리스트 생성
리스트는 날짜, 데이터 프레임, 벡터, 행렬 등 어떤 유형이든 요소로 포함할 수 있다는 점에서 상수 벡터와 다릅니다. 리스트에 다른 리스트를 포함할 수도 있습니다.
리스트는 list() 함수를 사용하여 생성합니다. c() 함수와 마찬가지로 list() 함수를 사용하려면 list 를 입력한 뒤 리스트에 넣을 값을 괄호 안에 입력하면 됩니다. 예를 들면 list(x, y, z, …)와 같습니다. 이 예시에서는 문자 ("a"), 정수 (1L), 실수 (1.5), 논리 (TRUE) 의 네 가지 요소 유형을 포함하는 리스트를 생성합니다.
list("a", 1L, 1.5, TRUE)
앞서 말했듯 리스트에는 다른 리스트를 포함할 수 있습니다. 원한다면 리스트 안에 리스트를 넣는 과정을 계속 반복할 수도 있습니다.
list(list(list(1 , 3, 5)))
리스트 구조 판정
str() 함수를 사용하면 리스트에 포함된 요소 유형을 알아낼 수 있습니다. 그렇게 하려면 함수의 괄호 안에 리스트 코드를 넣으면 됩니다. 함수를 실행하면 요소와 그 유형의 설명이 표시되어 리스트의 데이터 구조를 알 수 있습니다.
첫 예시 리스트에 str() 함수를 적용해보겠습니다.
str(list("a", 1L, 1.5, TRUE))
함수를 실행하면 리스트에 4개의 요소가 있으며, 요소의 유형은 문자 (chr), 정수 (int), 숫자 (num), 논리 (logi) 등 네 가지임을 알 수 있습니다.
#> List of 4
#> $ : chr "a"
#> $ : int 1
#> $ : num 1.5
#> $ : logi TRUE
str() 함수를 사용하여 두 번째 예시의 구조를 살펴보겠습니다. 우선 str() 함수에 넣기 쉽도록 리스트를 변수 z에 대입합니다.
z <- list(list(list(1 , 3, 5)))
함수를 실행합니다.
str(z)
#> List of 1
#> $ :List of 1
#> ..$ :List of 3
#> .. ..$ : num 1
#> .. ..$ : num 3
#> .. ..$ : num 5
들여쓰기된 $ 기호는 이 리스트의 중첩 구조를 나타내며, 이 예시는 3중 구조(리스트 안의 리스트 안의 리스트)입니다.
리스트 명명
리스트는 벡터처럼 명명이 가능합니다. list() 함수로 리스트를 만들 때 다음과 같이 요소를 명명할 수 있습니다.
list('Chicago' = 1, 'New York' = 2, 'Los Angeles' = 3)
$Chicago
[1] 1
$`New York`
[1] 2
$`Los Angeles`
[1] 3
추가 리소스
벡터와 리스트에 관해 자세히 알아보려면 R for Data Science의 20장: Vectors 를 참고하세요. R for Data Science는 데이터 사이언스 및 데이터 분석을 위해 R을 사용하는 방법을 배울 때 널리 사용되는 리소스입니다. 정리부터 시각화까지 데이터를 전달하는 데 필요한 모든 내용을 다룹니다. 벡터 및 리스트에 관해 자세히 알아보고 싶다면 Vectors 장에서 시작해보세요.
R의 날짜 및 시간
이 읽기 자료에서는 lubridate 패키지를 사용하여 R에서 날짜 및 시간을 대상으로 작업하는 방법을 배웁니다. lubridate 패키지의 도구를 사용하여 R에서 다양한 데이터 유형을 날짜 및 날짜/시간 형식으로 변환하는 방법을 배워보겠습니다.

tidyverse 및 lubridate 패키지 로드하기
날짜와 시간을 대상으로 작업하기 전에 tidyverse와 lubridate를 로드해야 합니다. lubridate는 tidyverse의 일부입니다.
우선 RStudio를 엽니다.
아직 tidyverse를 설치하지 않았다면 다음과 같이 install.packages() 함수를 사용해 설치하세요.
- install.packages("tidyverse")
다음으로 library() 함수를 사용하여 tidyverse와 lubridate 패키지를 로드합니다. 우선 현재 R 세션에서 사용할 수 있도록 핵심 tidyverse를 로드하세요.
- library(tidyverse)
그런 다음 lubridate 패키지를 로드합니다.
- library(lubridate)
이제 lubridate 패키지의 도구를 배울 준비가 됐습니다.
날짜 및 시간을 대상으로 작업
여기에서는 R의 날짜 및 시간 데이터 유형을 알아보고 문자열을 날짜/시간 형식으로 변환하는 방법을 배웁니다.
유형
R에는 현재 시간을 나타내는 다음의 세 가지 데이터 유형이 있습니다.
- 날짜 ("2016-08-16")
- 시간 (“20:11:59 UTC")
- 날짜/시간, 즉 날짜와 시간 ("2018-03-31 18:15:48 UTC")
시간은 협정 세계시(UTC, Universal Time Coordinated) 기준입니다. UTC는 시계와 시간을 조정하는 데 사용하는 국제 표준입니다.
today() 함수를 사용하면 현재 날짜를 알아낼 수 있습니다. 날짜는 연, 월, 일로 표시됩니다.
today()
#> [1] "2021-01-20"
now() 함수를 사용하면 현재 날짜/시간을 알아낼 수 있습니다. 시간이 가장 가까운 초로 표시된다는 점에 유의하세요.
now()
#> [1] "2021-01-20 16:25:05 UTC"
R에서는 다음의 세 가지 방법으로 날짜/시간 형식을 만들 수 있습니다.
- 문자열 사용
- 개별 날짜 사용
- 기존 날짜/시간 객체 사용
R에서 생성되는 날짜의 기본 형식은 표준 형식인 yyyy-mm-dd입니다.
각 방법을 살펴보겠습니다.
문자열에서 변환
날짜/시간 데이터는 문자열로 되어 있는 경우가 많습니다. lubridate에서 제공하는 도구를 사용하여 문자열을 날짜 및 날짜/시간으로 변환할 수 있습니다. 이 도구들은 날짜/시간 형식을 자동으로 파악합니다. 우선 날짜에서 연, 월, 일이 표시되는 순서를 확인하세요. 그런 다음 해당 날짜와 동일한 순서로 y, m, d를 배열합니다. 이는 날짜를 파싱할 lubridate 함수의 이름이 됩니다. 예를 들어 2021-01-20인 경우 ymd 순입니다.
ymd("2021-01-20")
함수를 실행하면 날짜가 yyyy-mm-dd 형식으로 반환됩니다.
#> [1] "2021-01-20"
이는 어떤 순서든 동일하게 작동합니다. 예를 들어 월, 일, 연도 순서에서도 yyyy-mm-dd 날짜 형식으로 반환됩니다.
mdy("January 20th, 2021")
#> [1] "2021-01-20"
일, 월, 연도 순서에서도 yyyy-mm-dd 날짜 형식으로 반환됩니다.
dmy("20-Jan-2021")
#> [1] "2021-01-20"
이 함수들은 따옴표 처리되지 않은 숫자도 yyyy-mm-dd 형식으로 변환합니다.
ymd(20210120)
#> [1] "2021-01-20"
날짜/시간 구성요소 생성
ymd() 함수와 그 변형 함수들은 날짜를 생성합니다. 날짜를 사용해 날짜/시간을 생성하려면 밑줄을 넣고 h, m, s(시, 분, 초) 중 최소 하나를 함수 이름에 추가하면 됩니다.
ymd_hms("2021-01-20 20:11:59")
#> [1] "2021-01-20 20:11:59 UTC"
mdy_hm("01/20/2021 08:01")
#> [1] "2021-01-20 08:01:00 UTC"
선택사항: 기존 날짜/시간 객체 간 전환
마지막으로, 날짜/시간과 날짜 형식 사이에서 전환해야 하는 경우
함수 as_date()를 사용하면 날짜/시간을 날짜로 변환할 수 있습니다. 예를 들어 now() 함수의 괄호 안에 현재 날짜/시간을 넣으면 결과는 다음과 같습니다.
as_date(now())
#> [1] "2021-01-20"
추가 리소스
R에서 날짜 및 시간을 대상으로 작업하는 방법을 자세히 알아보려면 다음 리소스를 참고하세요.
- lubridate.tidyverse: 다양한 tidyverse 패키지의 종합 참고 가이드로 활용할 수 있는 공식 tidyverse 설명서의 ‘lubridate’ 항목입니다. 이 링크에서 핵심 개념 및 함수의 개요를 확인해보세요.
- Dates and times with lubridate: Cheat Sheet: lubridate 패키지로 가능한 모든 작업을 자세히 살펴볼 수 있는 지도 요약본입니다. 포함된 내용을 모두 알 필요는 없지만, R에서의 날짜 및 시간 작업과 관련해 질문이 있을 때 유용하게 참고할 수 있는 자료입니다.
다른 일반 데이터 구조
이 읽기 자료에서는 데이터 구조 내용이 이어지며, 데이터 프레임 및 행렬에 관해 소개합니다. 각 구조의 기본 속성과 R 코드로 기본 속성을 활용하는 간단한 방법을 배웁니다. 데이터 및 관련 정보를 저장하고 이에 액세스하는 데 주로 사용되는 파일에 관해서도 간단하게 살펴봅니다.
데이터 구조
데이터 구조는 데이터가 있는 집이라는 비유를 다시 떠올려보세요.

데이터 프레임
데이터 프레임은 R에서 데이터를 저장 및 분석하는 가장 일반적인 방식입니다. 그러므로 데이터 프레임이 무엇인지, 이를 어떻게 생성하는지 이해해야 합니다. 데이터 프레임은 스프레드시트 또는 SQL 테이블과 유사한 열 모음입니다. 각 열 상단에는 변수를 나타내는 이름이 있으며, 행마다 하나의 관측값이 포함됩니다. 데이터 프레임은 데이터를 요약하여, 읽고 사용하기 쉬운 형식으로 구성하는 데 유용합니다.
예를 들어 아래 데이터 프레임은 R에 미리 로드된 데이터 세트 중 하나인 ‘diamonds’ 데이터 세트를 보여줍니다. 각 열에는 캐럿, 컷, 색상, 투명도, 깊이 등 다이아몬드와 관련된 변수가 하나씩 포함되어 있습니다. 각 행은 하나의 관측값을 보여줍니다.
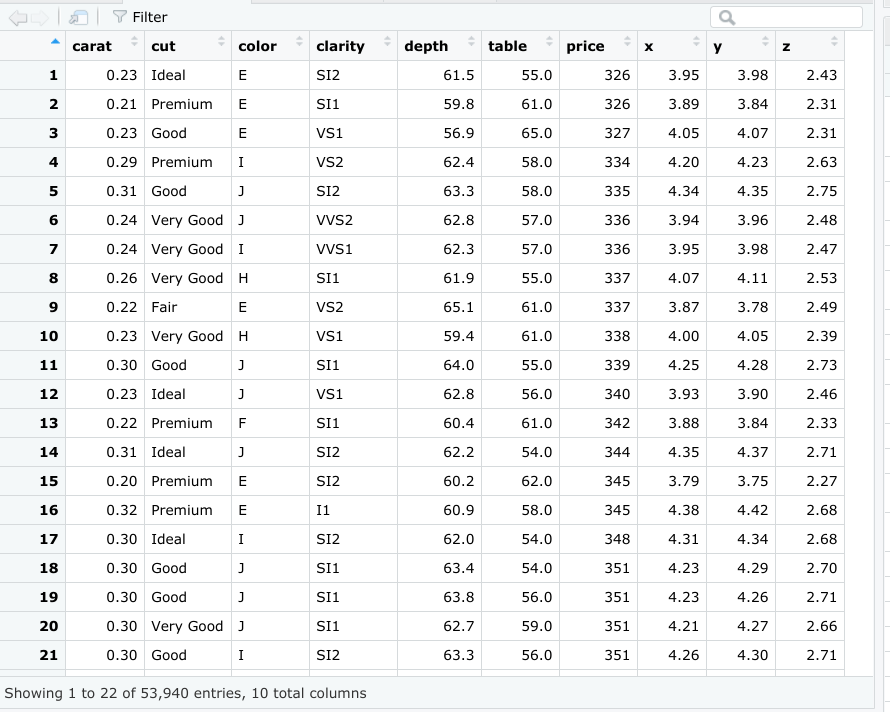
데이터 프레임으로 작업할 때 기억해야 할 주요 사항이 몇 가지 있습니다.
- 첫째, 열에 이름이 있어야 합니다.
- 둘째, 데이터 프레임에는 숫자, 논리, 문자 등 다양한 데이터 유형을 포함할 수 있습니다.
- 셋째, 같은 열의 요소는 같은 유형이어야 합니다.
데이터 프레임에 관해 나중에 자세히 배우겠지만, 위 내용을 먼저 기억해두시는 것이 좋습니다.
data.frame() 함수를 사용하면 R에서 직접 데이터 프레임을 생성할 수 있습니다. data.frame() 함수에는 벡터를 입력할 수 있습니다. 괄호 안에 열 이름, 등호, 열에 입력할 벡터를 차례로 적습니다. 이 예시에서 x 열은 요소 1, 2, 3이 있는 벡터이며 y 열은 요소 1.5, 5.5, 7.5가 있는 벡터입니다.
data.frame(x = c(1, 2, 3) , y = c(1.5, 5.5, 7.5))
이 함수를 실행하면 R은 데이터 프레임을 열과 행으로 구성하여 표시합니다.
x y
1 1 1.5
2 2 5.5
3 3 7.5
대부분의 경우 데이터 프레임을 직접 만들 필요가 없습니다. 대개 .csv 파일, 관계형 데이터베이스, 소프트웨어 프로그램 등 다른 소스에서 데이터를 가져오기 때문입니다.
파일
R에서 파일을 생성, 복사, 삭제하는 방법을 알아보겠습니다. R에서 파일로 작업하는 방법에 관한 자세한 정보는 RDocumentation: files를 참고하세요. RDocumentation은 거의 모든 R 패키지의 설명서를 쉽게 찾고 살펴볼 수 있는 CRAN의 도구입니다. R 코드 함수를 참고하기에 유용한 가이드입니다. 파일로 작업할 때 가장 유용한 함수 몇 가지를 살펴보겠습니다.
dir.create 함수를 사용하여 파일을 저장할 새 폴더 또는 디렉터리를 생성합니다. 함수의 괄호 안에 폴더 이름을 입력하세요.
dir.create ("destination_folder")
file.create() 함수를 사용하여 빈 파일을 생성합니다. 함수의 괄호 안에 파일 이름과 유형을 입력하세요. 파일 유형은 보통 .txt, .docx, .csv입니다.
file.create (“new_text_file.txt”)
file.create (“new_word_file.docx”)
file.create (“new_csv_file.csv”)
함수를 실행하여 파일이 생성되면 TRUE (실패한 경우 FALSE) 가 반환됩니다.
file.create (“new_csv_file.csv”)
[1] TRUE
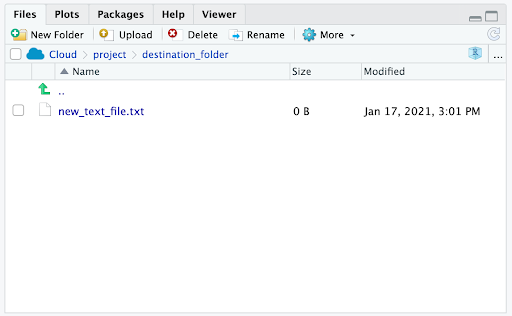
file.copy() 함수를 사용하면 파일을 복사할 수 있습니다. 괄호 안에 복사할 파일 이름을 추가합니다. 그런 다음 쉼표를 입력하고 해당 파일을 복사할 대상 폴더의 이름을 넣습니다.
file.copy (“new_text_file.txt” , “destination_folder”)
RStudio에서 Files 창을 확인하면 관련 폴더에 파일 사본이 나타납니다.
unlink() 함수를 사용하면 R 파일을 삭제할 수 있습니다. 함수의 괄호 안에 파일 이름을 입력합니다.
unlink (“some_.file.csv”)
--------------------------------------------------------------------------------------------------------------------------------------
선택사항: 행렬
행렬은 2차원 데이터 요소의 모음입니다. 즉 행과 열이 모두 있습니다. 이와 달리 벡터는 1차원 데이터 요소의 모음입니다. 그러나 벡터와 마찬가지로 행렬도 하나의 데이터 유형만 포함할 수 있습니다. 예를 들어 한 행렬에 논리와 숫자를 모두 포함할 수 없습니다.
matrix() 함수를 사용하면 R에서 행렬을 생성할 수 있습니다. matrix() 함수에는 괄호에 입력할 두 개의 주요 인수가 있습니다. 먼저 벡터를 추가합니다. 벡터에는 행렬에 넣을 값을 포함합니다. 다음으로 최소 하나의 행렬 차원을 추가합니다. nrow = 또는 ncol = 코드를 사용하면 행 수 또는 열 수를 지정할 수 있습니다.
예를 들어 3~8의 값을 포함하는 2x3(행 2개, 열 3개) 행렬을 생성한다고 가정해보겠습니다. 먼저 숫자를 포함하는 벡터를 입력합니다. c(3:8)입니다.그런 다음 쉼표를 입력합니다. 마지막으로 nrow = 2 를 입력하여 행 수를 지정합니다.
matrix(c(3:8), nrow = 2)
이 함수를 실행하면 열 3개와 행 2개(보통 ‘2x3’으로 칭함)의 구성으로 수치 3, 4, 5, 6, 7, 8을 포함한 행렬이 표시됩니다. 벡터의 첫 번째 값(3)이 행렬의 최상단 행의 가장 왼쪽 열에 배치되고, 나머지 값이 왼쪽에서 오른쪽으로 배치됩니다.
[,1] [,2] [,3]
[1,] 3 5 7
[2,] 4 6 8
행 수 (ncol = ) 대신 열 수 (nrow = ) 를 지정해도 됩니다.
matrix(c(3:8), ncol = 2)
이 함수를 실행하면 R에서 행 수를 자동으로 추론합니다.
[,1] [,2]
[1,] 3 6
[2,] 4 7
[3,] 5 8
R 코딩 살펴보기
연산자 및 계산
R에서 연산자를 사용하여 계산하는 방법을 배웠습니다. 이전에 배운 연산과 계산의 개념을 다시 다루면서, R에서 사용하는 다양한 연산자와 그 활용법을 설명했습니다.
1. 연산자 개념
- 연산자는 수식에서 수행할 연산이나 계산의 유형을 지정하는 기호입니다.
- R에서 연산자는 데이터를 처리하거나 분석할 때 중요한 역할을 합니다.
2. 대입 연산자
- **대입 연산자(<-)**는 값을 변수에 저장할 때 사용됩니다.
- 예: midyear_sales <- 10000는 midyear_sales 변수에 10,000이라는 값을 저장합니다.
- 벡터나 많은 수치를 처리할 때도 대입 연산자를 사용하여 쉽게 값을 변수에 대입할 수 있습니다.
3. 산술 연산자
- 산술 연산자는 수학 계산에 사용되는 기본적인 연산자입니다. R에서 사용하는 대표적인 산술 연산자는 다음과 같습니다:
- 덧셈(+): 두 수를 더합니다.
- 뺄셈(-): 두 수를 뺍니다.
- 곱셈(*): 두 수를 곱합니다.
- 나눗셈(/): 두 수를 나눕니다.
- 예를 들어, total_sales <- Q1_sales + Q2_sales 코드는 1분기와 2분기 매출을 더한 값을 total_sales라는 변수에 저장합니다.
4. 예시: 1년 치 총매출 계산
- 1, 2분기의 매출 합계를 구한 후, 여기에 2를 곱하여 1년 치 총매출을 대략적으로 예측할 수 있습니다.
- 예: annual_sales <- midyear_sales * 2는 1년 예상 매출을 계산하는 코드입니다.
5. R과 다른 도구와의 유사성
- SQL이나 스프레드시트와 마찬가지로, R에서도 연산자를 통해 데이터를 처리하고 계산할 수 있습니다. 이러한 도구 간의 유사성을 이해하면 작업 전환 시에도 쉽게 적응할 수 있습니다.
6. 스크립트 저장
- R에서 작업한 코드는 스크립트로 저장하여 언제든 다시 사용할 수 있습니다. Save As 기능을 통해 파일을 저장하고, 나중에 필요할 때 파일을 열어 계속 작업할 수 있습니다.
논리 연산자 및 조건문
앞서 연산자란 수식에서 수행할 연산이나 계산 유형을 보여주는 기호라고 배웠습니다. 이 읽기 자료에서는 주요 논리 연산자 유형과 이를 사용해 R 코드로 조건문을 만드는 방법을 배웁니다.

- AND 연산자는 두 개의 논릿값을 취합니다. 그리고 개별 값이 둘 다 TRUE인 경우에만 TRUE를 반환합니다. 즉, TRUE & TRUE는 TRUE로 평가됩니다. 반면, FALSE & TRUE, TRUE & FALSE, FALSE & FALSE는 모두 FALSE로 평가됩니다.
- R에서 AND에 해당하는 코드를 실행하면 다음과 같은 결과를 얻게 됩니다. > TRUE & TRUE [1] TRUE > TRUE & FALSE [1] FALSE > FALSE & TRUE [1] FALSE > FALSE & FALSE [1] FALSE 결과를 비교하여 위 결과를 설명할 수 있습니다. 변수 x가 10이라고 가정해봅시다. x <- 10 ‘x’가 3보다 크고 12보다 작은지 확인하기 위해 ‘AND’ 표현식의 값으로 x > 3 & x < 12를 사용합니다. x > 3 & x < 12 이 함수를 실행하면 R에서 결과로 TRUE를 반환합니다. [1] TRUE 첫 번째 부분인 x > 3은 10이 3보다 크기 때문에 TRUE로 평가됩니다. 두 번째 부분인 x < 12는 10이 12보다 작기 때문에 TRUE로 평가됩니다. 값이 둘 다 TRUE이므로 AND 표현식의 결과는 TRUE입니다. 숫자 10은 숫자 3과 12 사이에 있습니다. 그러나 x가 20이라면 표현식 x > 3 & x < 12는 다른 결과를 반환합니다. x <- 20 x > 3 & x < 12 [1] FALSE x > 3은 TRUE(20 > 3)지만 x < 12는 FALSE(20 < 12)입니다. AND 표현식에서는 한 부분이 FALSE면 전체 표현식이 FALSE가 됩니다(TRUE & FALSE = FALSE). 따라서 R에서 결과로 FALSE를 반환합니다.
OR 연산자 ‘|’
- OR 연산자(|)는 AND 연산자(&)와 비슷하게 작동합니다. 가장 큰 차이는 OR 연산에서 최소 하나의 값이 TRUE이면 OR 연산 전체가 TRUE로 평가된다는 점입니다. 즉 TRUE | TRUE, TRUE | FALSE, FALSE | TRUE는 모두 TRUE로 평가됩니다. 값이 둘 다 FALSE라면 결과는 FALSE입니다.
- 코드를 작성하면 다음과 같은 결과를 얻게 됩니다. > TRUE | TRUE [1] TRUE > TRUE | FALSE [1] TRUE > FALSE | TRUE [1] TRUE > FALSE | FALSE [1] FALSE 예를 들어 변수 y의 값이 7이라고 가정해봅시다. y가 8보다 작거나 16보다 큰지 확인하기 위해 다음 표현식을 사용합니다. y <- 7 y < 8 | y > 16 비교 결과는 TRUE (7은 8보다 작음) | FALSE (7은 16보다 크지 않음)입니다. OR 표현식에서는 하나의 값만 TRUE이면 전체 표현식이 TRUE이므로 R에서 결과로 TRUE를 반환합니다. [1] TRUE 이제 y를 12로 가정해봅시다. 표현식 y < 8 | y > 16은 FALSE (12 < 8) | FALSE (12 > 16)으로 평가됩니다. 두 비교 결과가 모두 FALSE이므로 결과는 FALSE입니다. y <- 12 y < 8 | y > 16 [1] FALSE
NOT 연산자 ‘!’
- NOT 연산자(!)는 해당 연산자가 적용되는 논릿값을 부정합니다. 다시 말해서 !TRUE는 FALSE로 평가되고 !FALSE는 TRUE로 평가됩니다.
- NOT 코드를 실행하면 다음과 같은 결과를 얻게 됩니다. > !TRUE [1] FALSE > !FALSE [1] TRUE OR 및 AND 연산자와 마찬가지로 NOT 연산자를 논리 연산자와 함께 사용할 수 있습니다. 0은 FALSE로 간주되며 0이 아닌 숫자는 TRUE로 간주됩니다. NOT 연산자는 반대 논릿값으로 평가됩니다. 변수 x가 2라고 가정해봅시다. x <- 2 NOT 연산은 0이 아닌 숫자의 논릿값(TRUE)을 반대로 취하기 때문에 FALSE로 평가됩니다. > !x [1] FALSE
-----------------
논리 연산자를 사용하여 데이터를 분석하는 방법의 예를 살펴보겠습니다. RStudio에 미리 로드된 airquality 데이터 세트로 작업한다고 가정해봅시다. 이 데이터 세트에는 1973년 5월부터 9월까지 뉴욕의 일일 대기질 측정값 데이터가 있습니다.
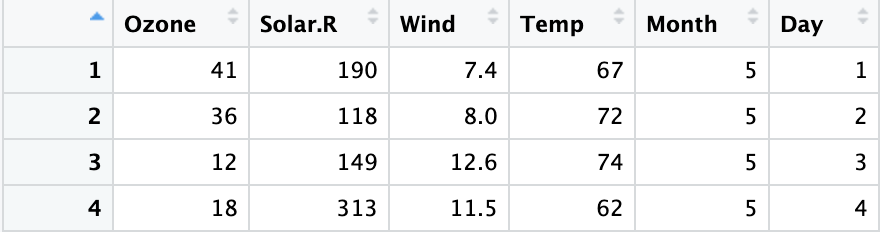
이러한 데이터 세트에서 AND, OR, NOT 연산자를 어떻게 활용할 수 있는지 살펴봅시다.
AND 예
Solar 측정값 150 초과, Wind 측정값 10 초과로 정의되는 매우 화창하고 바람이 강한 날의 행을 특정하려고 합니다.
이러한 논리문을 R로 표현하면 Solar.R > 150 & Wind > 10입니다.

OR 예
다음으로 Solar 측정값 150 초과 또는 Wind 측정값 10 초과로 정의되는 매우 화창하거나 바람이 강한 날의 행을 특정하려고 합니다.
이러한 논리문을 R로 표현하면 Solar.R > 150 | Wind > 10입니다.
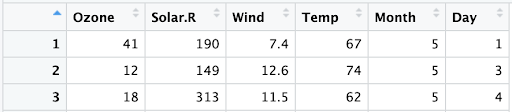
NOT 예
이번에는 1일이 아닌 날의 날씨 측정값에 주목하려고 합니다.
이러한 논리문을 R로 표현하면 Day != 1입니다.
기준을 충족하는 행은 다음과 같이 조건이 참인 행입니다.
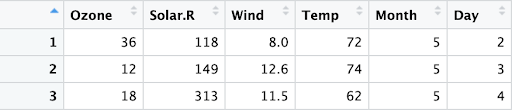
마지막으로 매우 화창한 날과 바람이 강한 날의 정의에 따라, 이번에는 매우 화창하지 않고 바람이 강하지 않은 날에 주목하려고 합니다. 다시 말해 ‘Solar 측정값 150 초과 또는 Wind 측정값 10 초과’라는 문장이 참이 아닌 경우입니다.
이는 앞에서 사용한 OR 문의 반대입니다. 이러한 논리문을 R로 표현하면 앞서 사용한 OR 문 앞에 느낌표(!)를 넣은 !(Solar.R > 150 | Wind > 10)입니다. R은 NOT 연산자를 괄호 안의 모든 항목에 적용합니다.
이 예에서 기준을 충족하는 행은 다음과 같이 한 개입니다.

----------------------------------------------------------------------------------------------------------------------------------------
선택사항: 조건문
조건문은 특정 조건이 성립하면 특정 사건이 발생해야 한다는 선언입니다. ‘만약 기온이 0도보다 높으면 나는 산책하러 나간다’가 그러한 예입니다. 첫 번째 조건(기온이 0도보다 높음)이 참이면 두 번째 조건(나는 산책하러 나감)이 발생합니다. R 코드의 조건문도 이와 논리가 비슷합니다.
R에서 다음 세 가지 관련 문을 사용하여 조건문을 만드는 방법을 알아봅시다.
- if()
- else()
- else if()
if 문
if 문은 조건을 설정합니다. 조건이 TRUE로 평가되면 if 문과 연결된 R 코드가 실행됩니다.
R에서는 조건에 해당하는 코드를 if 문의 괄호 안에 넣습니다. 조건이 TRUE일 때 실행할 코드는 중괄호 안에 넣어 조건 뒤에 배치합니다(‘expr’ 참고). 이 예에서 닫는 중괄호는 새로운 코드 줄에 배치되어 실행할 코드의 끝을 표시합니다.
if (condition) {
expr
}
예를 들어 변수 x의 값이 4인 식을 만들어봅니다.
x <- 4
다음으로 x가 0보다 크면 R에서 “x is a positive number”라는 문자열을 출력한다는 조건문을 작성합니다.
if (x > 0) {
print("x is a positive number")
}
x = 4이므로 조건은 참입니다(4 > 0). 그러므로 코드를 실행하면 R에서 “x is a positive number”라는 문자열을 출력합니다.
[1] "x is a positive number"
그러나 x를 -4와 같은 음수로 바꾼다면 조건은 FALSE가 됩니다(-4 > 0). 코드를 실행하면 R에서 print 문이 실행되지 않습니다. 대신 빈 줄이 결과로 표시됩니다.
else 문
else 문은 if 문과 함께 사용됩니다. R에서 else 문의 코드 구성은 다음과 같습니다.
if (condition) {
expr1
} else {
expr2
}
else 문과 연결된 코드는 if 문의 조건이 TRUE가 아닌 경우에 실행됩니다. 다시 말해 조건이 TRUE인 경우 R에서 if 문 안의 코드(expr1)를 실행하고, 조건이 TRUE가 아닌 경우 else 문 안의 코드(expr2)를 실행합니다.
예를 통해 살펴보겠습니다. 먼저 변수 x의 값이 7인 식을 만듭니다.
x <- 7
조건을 다음과 같이 설정합니다.
- x가 0보다 크면 R에서 “x is a positive number”를 출력한다.
- x가 0보다 작거나 같으면 R에서 “x is either a negative number or zero”를 출력한다.
이 코드에서 첫 번째 조건(x > 0)은 if 문에 포함되고 두 번째 조건(x가 0보다 작거나 같음)은 else 문에 포함됩니다. x > 0이면 R에서 “x is a positive number”를 출력합니다. 그 밖의 경우 R에서 “x is either a negative number or zero”를 출력합니다.
x <- 7
if (x > 0) {
print ("x is a positive number")
} else {
print ("x is either a negative number or zero")
}
7은 0보다 크기 때문에 if 문의 조건은 참입니다. 따라서 코드를 실행하면 R에서 “x is a positive number”를 출력합니다.
[1] "x is a positive number"
그러나 x가 -7이라면 if 문의 조건은 참이 아닙니다(-7은 0보다 크지 않음). 그러므로 R에서 else 문의 코드를 실행합니다. 코드를 실행하면 R에서 “x is either a negative number or zero”를 출력합니다.
x <- -7
if (x > 0) {
print("x is a positive number")
} else {
print ("x is either a negative number or zero")
}
[1] "x is either a negative number or zero"
else if 문
경우에 따라 else if 문을 추가하여 조건문을 더욱 맞춤화할 수 있습니다. else if 문은 if 문과 else 문 사이에 위치합니다. 코드 구조는 다음과 같습니다.
if (condition1) {
expr1
} else if (condition2) {
expr2
} else {
expr3
}
if 조건(condition1)이 충족되면 R에서 첫 번째 식(expr1)을 실행합니다. if 조건이 충족되지 않고 else if 조건(condition2)이 충족되면 R에서 두 번째 식(expr2)을 실행합니다. 두 조건 중 어느 조건도 충족되지 않으면 R에서 세 번째 식(expr3)을 실행합니다.
이전 예에서는 if 문과 else 문만 사용했기 때문에 x가 0이거나 x가 0보다 작은 경우에도 R에서 “x is either a negative number or zero”만 출력할 수 있었습니다. 그런데 x가 0이면 R에서 “x is zero”라는 문자열을 출력해야 한다고 가정해봅시다. 그럴 때는 else if 문을 사용해 다른 조건을 추가해야 합니다.
예를 통해 살펴보겠습니다. 먼저 변수 x의 값이 음수 1(‘-1’)인 식을 만듭니다.
x <- -1
이제 다음과 같이 조건을 설정합니다.
- x가 0보다 작으면 “x is a negative number”를 출력한다.
- x가 0이면 “x is zero”를 출력한다.
- 그 밖의 경우 “x is a positive number”를 출력한다.
이 코드에서 첫 번째 조건은 if 문에 포함되고, 두 번째 조건은 else if 문에 포함되고, 세 번째 조건은 else 문에 포함됩니다. x < 0이면 R에서 “x is a negative number”를 출력합니다. x = 0이면 R에서 “x is zero”를 출력합니다. 그 밖의 경우 R에서 “x is a positive number”를 출력합니다.
x <- -1
if (x < 0) {
print("x is a negative number")
} else if (x == 0) {
print("x is zero")
} else {
print("x is a positive number")
}
-1은 0보다 작기 때문에 if 문의 조건은 TRUE로 평가되고 R에서 “x is a negative number”를 출력합니다.
[1] "x is a negative number"
x가 0인 경우 R에서 먼저 if 조건(x < 0)을 확인하고 FALSE로 판단합니다. 그런 다음 R에서 else if 조건을 평가합니다. else if의 조건은 x==0이므로 TRUE입니다. 따라서 이 경우 R에서 “x is zero”를 출력합니다.
x가 1인 경우 if 조건과 else if 조건이 모두 FALSE로 평가됩니다. 따라서 R에서 else 문을 실행하여 “x is a positive number”를 출력합니다.
R은 TRUE로 판단되는 조건을 발견한 후 곧바로 조건에 해당하는 코드를 실행하고 나머지는 무시합니다.
추가 리소스
논리 연산자 및 조건문에 관한 자세한 내용은 DataCamp의 Conditionals and Control Flow in R 튜토리얼을 참고하세요. DataCamp는 컴퓨터 프로그래밍 학습자들에게 인기 있는 리소스입니다. 이 튜토리얼에서는 여러 코딩 애플리케이션에서의 유용한 논리 연산자, 조건문, 관계 연산자 예시를 참고할 수 있으며, 각 주제 및 해당 주제와 관련된 다른 주제의 요약을 확인할 수 있습니다.
R 패키지 알아보기
끊임없는 선물
R 패키지에 대한 개념과 활용 방법을 배웠습니다. R 패키지는 R 사용자가 작성한 재사용 가능한 함수 모음으로, 데이터 분석 및 프로그래밍 작업을 효율적으로 처리하는 데 중요한 역할을 합니다.
1. R 패키지란?
- R 패키지는 R 커뮤니티에서 생성한 재현 가능한 R 코드의 모음입니다.
- 패키지는 함수를 묶어 제공하며, 그 외에도 샘플 데이터와 테스트 코드가 포함될 수 있습니다.
- R에는 기본적으로 Base R이라는 패키지 세트가 포함되어 있어, 처음 RStudio를 설치하고 실행할 때부터 사용할 수 있습니다.
2. 패키지 로드와 설치
- 패키지를 사용하려면 먼저 로드해야 합니다. 기본적으로 패키지는 R에 설치되어 있을 수 있지만, 로드되지 않은 상태일 수 있습니다.
- 예를 들어, library(boot) 명령어를 사용하여 'boot' 패키지를 로드할 수 있습니다.
- 패키지가 로드되면, 그 안의 함수를 R에서 사용할 수 있게 됩니다.
3. 설치된 패키지 확인
- installed.packages() 명령어를 실행하면, RStudio에 설치된 패키지 목록을 확인할 수 있습니다.
- Package 열: 패키지 이름이 나옵니다.
- Priority 열: 해당 패키지의 우선순위를 나타냅니다. 'base'는 이미 설치 및 로드된 패키지를, 'recommended'는 설치되었지만 아직 로드되지 않은 패키지를 의미합니다.
4. 패키지에 관한 정보 확인
- RStudio의 'Packages' 탭에서 패키지 이름을 클릭하면, 해당 패키지에 대한 설명을 볼 수 있습니다.
- 또한 help() 함수를 사용하여 특정 패키지나 함수에 대한 설명을 호출할 수 있습니다.
5. CRAN과 패키지 다운로드
- R 패키지의 가장 흔한 소스는 **CRAN (Comprehensive R Archive Network)**입니다.
- CRAN에는 수많은 패키지, 소스 코드, 매뉴얼, 그리고 문서가 보관되어 있습니다.
- CRAN이나 기타 검색 엔진을 통해 필요한 패키지를 검색하고 설치할 수 있습니다.
6. 패키지의 중요성
- 패키지는 데이터 분석 과정에서 필수적인 도구입니다. 함수를 사용하여 프로그래밍 작업을 더 쉽게 수행할 수 있으며, 복잡한 기능을 한 번에 처리할 수 있습니다.
- 나중에는 여러분이 직접 코드를 패키지로 만들어 다른 사람과 공유할 수도 있습니다.
사용 가능한 R 패키
데이터 분석에서 R을 최대한 활용하려면 패키지를 설치해야 합니다. 패키지는 재현 가능한 R 코드의 한 단위이며, 이를 통해 R에 기능을 추가할 수 있습니다. 다른 사용자도 액세스할 수 있도록 R 커뮤니티에서 패키지를 제작 및 공유하기 때문에 특히 유용합니다. 이 읽기 자료에서는 널리 사용되는 패키지에 관해 자세히 알아보고 패키지를 찾을 수 있는 장소를 살펴봅니다.
패키지는 설치 가능한 상태의 유용한 패키지를 모아둔 저장소에서 찾을 수 있습니다. Bioconductor, R-Forge, rOpenSci, GitHub 등에서 저장소가 제공되지만 가장 널리 사용되는 저장소는 CRAN(Comprehensive R Archive Network)입니다. CRAN은 코드 및 설명서를 저장하여 패키지를 사용자만의 RStudio 공간에 설치하도록 지원합니다.
패키지 설명서
패키지에는 코드 자체뿐만 아니라 패키지의 작성자, 함수 및 다운로드해야 하는 기타 패키지 등을 기술하는 설명서도 포함됩니다. CRAN을 참고하는 경우 패키지 설명서는 DESCRIPTION 파일 내에 있습니다.
자세한 정보는 칼 브로만의 R Package Primer를 참고하세요.
알맞은 패키지 선택
패키지가 아주 많기 때문에 설치된 패키지의 라이브러리 또는 디렉터리에 가장 유용한 패키지가 무엇인지 알기 어려울 수 있습니다. 다행히 판단하는 데 도움이 되는 리소스가 몇 가지 있습니다.
- Tidyverse: tidyverse는 데이터 작업을 위해 특별히 설계된 R 패키지 모음입니다. 대다수 데이터 애널리스트들의 표준 라이브러리지만, 패키지만 개별적으로 다운로드할 수도 있습니다.
- Quick list of useful R packages: RStudio Support의 유용한 패키지 목록입니다. 설치 안내와 기능 설명이 포함되어 있습니다.
- CRAN Task Views: 작업별로 분류된 CRAN 패키지 인덱스입니다. 필요한 작업 유형을 검색하면 해당 작업과 관련된 패키지의 페이지가 표시됩니다.
이 강좌를 진행하고 R을 자주 사용하다 보면 더 많은 패키지를 찾게 되실 것입니다. 소개해드린 리소스를 여러분의 라이브러리를 만들어가기 위한 훌륭한 출발점으로 활용하세요.
tidyverse 소개
tidyverse 패키지에 대해 소개하고, 이를 R에서 설치 및 사용하는 방법을 배웠습니다. tidyverse는 데이터 조작, 탐색, 시각화를 위한 여러 패키지를 포함한 모음으로, R에서 데이터 분석을 할 때 매우 중요한 도구입니다.
1. tidyverse란?
- tidyverse는 데이터 분석 과정 전반에서 사용되는 패키지 모음으로, 서로 잘 통합되어 동작하는 다양한 패키지를 포함하고 있습니다.
- 설문조사 프로젝트 작업을 통해 tidyverse의 중요성을 처음 알게 되었으며, R 작업의 심화된 단계를 경험하게 되었습니다.
- tidyverse는 강력한 커뮤니티 지원을 받으며, 프로그래밍과 데이터 분석의 핵심으로 자리 잡고 있습니다.
2. tidyverse 설치 방법
- tidyverse를 설치하려면 install.packages() 함수를 사용합니다.
- 예: install.packages("tidyverse")
- 이 함수는 CRAN에서 tidyverse 패키지를 다운로드하고 설치합니다.
- CRAN은 패키지의 신뢰성과 품질을 보장하기 때문에, CRAN에서 다운로드한 패키지는 검증된 패키지로 믿을 수 있습니다.
- GitHub도 R 패키지를 찾을 수 있는 주요 소스 중 하나입니다.
3. 패키지 로드와 확인
- tidyverse가 설치되면, library(tidyverse) 명령어를 사용하여 tidyverse 패키지를 R에 로드할 수 있습니다.
- tidyverse를 로드하면, ggplot2, tibble, tidyr, readr, purrr, dplyr, stringr, forcats 등의 여러 패키지가 함께 로드됩니다.
- 이 패키지들은 데이터 시각화, 데이터 변환, 탐색 등 다양한 분석 작업에 필수적입니다.
4. 패키지 충돌
- 패키지를 로드할 때 함수 충돌이 발생할 수 있습니다. 예를 들어, 다른 패키지에 동일한 이름의 함수가 있을 때 충돌이 생깁니다.
- 이 경우, 마지막으로 로드된 패키지의 함수가 우선 사용됩니다.
- 충돌 메시지는 한 번만 표시되며, 익숙해지면 어떤 함수를 사용해야 할지 쉽게 구분할 수 있습니다.
5. tidyverse 업데이트
- tidyverse의 패키지 업데이트는 매우 중요합니다. tidyverse_update() 명령어를 사용하여 tidyverse 패키지의 업데이트를 확인할 수 있습니다.
- 전체 패키지를 업데이트하려면 update.packages() 명령어를 사용합니다.
- 특정 패키지만 업데이트하려면 install.packages() 함수에 해당 패키지 이름을 입력해 업데이트할 수 있습니다.
6. 충돌 및 오류 해결
- 콘솔에 나타나는 충돌 알림 및 오류 메시지는 데이터 분석 과정에서 종종 발생할 수 있습니다.
- 'Help' 탭을 사용하여 메시지의 의미와 해결 방법을 쉽게 찾을 수 있습니다.
tidyverse 살펴보기
tidyverse 심화 학습
tidyverse의 주요 패키지들과 각 패키지가 데이터 분석 워크플로에서 어떤 역할을 하는지에 대해 설명하고 있습니다. 마치 여행을 떠나듯 tidyverse의 여러 패키지와 그 기능을 탐험하는 과정으로 비유하고 있습니다.
1. tidyverse의 핵심 패키지
- tidyverse는 ggplot2, dplyr, tidyr, readr 등 데이터 애널리스트 워크플로의 핵심 패키지를 포함합니다. 이 패키지들은 데이터 시각화, 데이터 정리, 가져오기, 그리고 데이터 조작과 관련된 작업에 자주 사용됩니다.
a. ggplot2
- ggplot2는 데이터 시각화를 위한 패키지입니다.
- 다양한 시각적 속성을 데이터에 적용하여 복잡한 플롯을 생성할 수 있습니다. 이 패키지는 플롯을 만들 때 매우 유용하며, 향후 직접 실습해 볼 예정입니다.
b. tidyr
- tidyr은 데이터를 정리하는 데 사용되며, 데이터를 타이디(Tidy) 형식으로 변환해줍니다. 타이디 데이터는 각 데이터 요소가 알맞은 위치와 형식에 맞춰져 있는 구조화된 데이터를 말합니다.
- tidyr은 가로형, 세로형 데이터 모두에서 유용하게 사용할 수 있습니다.
c. readr
- readr은 데이터 가져오기에 사용되며, 특히 CSV 파일을 가져올 때 유용합니다.
- read_csv() 함수가 가장 흔히 사용되는 함수로, CSV 파일을 읽어와 테이블 형식으로 변환합니다. R이 자동으로 열의 사양을 파악하여 적절한 데이터 유형으로 변환해 줍니다.
d. dplyr
- dplyr은 데이터 조작을 위한 함수 세트를 제공합니다.
- select() 함수로 특정 변수를 선택하거나 filter() 함수로 조건을 만족하는 데이터를 필터링할 수 있습니다.
2. 기타 패키지
tidyverse에는 덜 자주 사용되지만 유용한 다른 패키지들도 있습니다.
- tibble: 데이터 프레임을 더욱 간편하게 다룰 수 있는 기능을 제공합니다.
- purrr: 함수형 프로그래밍과 벡터 작업을 더 쉽게 처리할 수 있도록 돕습니다.
- stringr: 문자열 작업을 위한 함수들을 포함하고 있어 텍스트 데이터를 처리하는 데 유용합니다.
- forcats: 범주형 데이터(팩터)를 쉽게 다룰 수 있도록 도와줍니다.
파이프로 작업
파이프 연산자에 대해 깊이 있게 설명하고, 파이프를 사용해 데이터를 효율적으로 조작하는 방법을 다룹니다. 특히, 중첩된 함수를 사용하지 않고 여러 연산을 연속적으로 처리하는 R의 파이프 연산자 %>%를 강조하며 이를 통해 코드의 가독성과 효율성을 높이는 방법을 소개합니다.
1. 파이프의 개념
- 파이프 연산자 %>%는 연속적인 작업을 이어가는 도구입니다. 하나의 연산 결과를 다음 연산에 자동으로 전달하여 중첩 코드보다 간결하고 직관적인 코드를 작성할 수 있습니다.
- 파이프를 사용하면 함수 내에 함수를 중첩할 필요 없이, 각 연산을 하나씩 나열하는 방식으로 처리할 수 있습니다.
2. 예시: ToothGrowth 데이터 세트
- ToothGrowth 데이터 세트를 사용해 파이프 연산자를 실습합니다. 이 데이터 세트는 비타민 C가 기니피그의 이빨 성장에 미치는 영향을 분석하는 데이터입니다.
- 데이터를 필터링하고 정렬하는 작업을 통해 파이프의 사용 방법을 배웁니다.
필터링 및 정렬 예시:
r
ToothGrowth %>%
filter(dose == 0.5) %>%
arrange(len)
- filter 함수는 비타민 C 투여량이 0.5인 데이터만 선택하고, arrange 함수는 이빨 길이(len)를 기준으로 데이터를 오름차순으로 정렬합니다.
3. 파이프의 장점
- 가독성: 코드가 간결하고 명확해져 쉽게 이해할 수 있습니다.
- 유연성: 파이프를 사용하면 작업을 단계적으로 처리할 수 있어, 작업을 추가하거나 수정할 때 매우 편리합니다.
- 코드 관리: 파이프는 각 줄이 독립적으로 처리되므로 오류를 찾기 쉽고 디버깅이 수월합니다.
4. 그룹화와 요약
- 파이프를 사용해 데이터를 그룹화하고 요약하는 과정도 소개됩니다. 예를 들어, 비타민 C의 두 가지 유형(오렌지 주스 OJ, 아스코르브산 VC)에 따른 이빨 길이의 평균을 계산할 수 있습니다.
그룹화 및 요약 예시:
r
ToothGrowth %>%
filter(dose == 0.5) %>%
group_by(supp) %>%
summarize(mean_len = mean(len, na.rm = TRUE))- group_by: supp(보충제 종류)에 따라 데이터를 그룹화합니다.
- summarize: 각 그룹의 평균 이빨 길이를 계산합니다.
5. 파이프 사용 시 유의사항
- 파이프 연산자는 각 연산 뒤에 이어지지만, 마지막 연산 뒤에는 파이프를 사용하지 않습니다.
- 들여쓰기가 잘못되면 파이프 연결에 오류가 발생할 수 있으니 주의가 필요합니다.
추가 R 리소스

R 커뮤니티에는 문제의 해결책과 새로운 R 사용법을 찾기 위해 최선을 다해 서로 돕는 사용자들이 많습니다. 튜토리얼 및 기타 리소스를 찾을 수 있는 훌륭한 블로그도 많습니다. 몇 가지를 확인해보세요.
- PositRStudio: R 도움말을 찾을 수 있는 가장 좋은 곳은 바로 R입니다. '?' 또는 help() 명령어를 입력하여 R에서 검색해보세요. Help 창을 열면 더 많은 R 리소스를 찾을 수 있습니다.
- Posit Blog: 회사 소식을 포함하여 Posit에 관한 정보를 찾을 수 있는 Posit의 블로그입니다. 여기에서 최신 특집 게시물을 읽어보세요. 페이지 왼쪽의 검색창 및 카테고리 목록을 통해 흥미로운 주제를 살펴보고 특정 게시글을 검색할 수도 있습니다.
- Stack Overflow: 다른 코딩 작성자의 의견 및 조언을 확인할 수 있는 Stack Overflow의 블로그입니다. 커뮤니티 대화를 통해 관련 소식을 주고받을 수 있어 정말 유용합니다.
- R-Bloggers: 커뮤니티의 다른 R 사용자가 게시한 유용한 튜토리얼과 뉴스 기사를 확인할 수 있는 R-Bloggers 블로그입니다.
- R-Bloggers의 Tutorials for learning R: 기본 R 튜토리얼과 고급 가이드 링크를 확인할 수 있는 R-Bloggers의 블로그 게시물입니다.