2024. 8. 29. 14:05ㆍGCC/데이터 애널리틱스

데이터베이스 작업
데이터베이스에 관한 모든 내용
데이터베이스란 무엇인가?
데이터베이스는 컴퓨터 시스템에 저장된 구조화된 데이터의 모음입니다. 이 데이터는 검색, 업데이트, 삭제, 추가 등의 조작을 위해 구조화되어 있으며, 이를 통해 특정 요구 사항에 맞는 데이터를 효율적으로 관리하고 분석할 수 있습니다. 데이터베이스는 기업의 의사결정, 연구, 고객 관리, 운영 효율성 향상 등을 위해 사용됩니다.
메타데이터란 무엇인가?
메타데이터는 '데이터에 대한 데이터'를 의미합니다. 즉, 메타데이터는 데이터의 맥락, 속성, 구조 등을 설명하는 정보를 포함합니다. 예를 들어, 한 데이터베이스에 저장된 고객 정보 데이터에는 고객의 이름, 주소, 전화번호와 같은 실제 데이터가 포함되어 있지만, 메타데이터는 이러한 데이터가 어떤 형식인지, 언제 업데이트되었는지, 데이터의 출처는 무엇인지 등을 설명합니다.
메타데이터의 주요 역할은 다음과 같습니다:
- 데이터 맥락 제공: 메타데이터는 데이터의 출처, 생성 시기, 데이터 형식 등 중요한 정보를 제공하여 데이터의 의미를 이해하는 데 도움을 줍니다.
- 데이터 관리 용이성: 메타데이터를 사용하면 데이터베이스에서 데이터를 더 쉽게 검색하고, 분석하고, 관리할 수 있습니다.
- 데이터 품질 개선: 메타데이터는 데이터의 정확성과 일관성을 유지하는 데 중요한 역할을 합니다.
데이터 정렬과 분석
데이터베이스를 통해 데이터를 분석할 때는 **정렬(sorting)**과 **필터링(filtering)**이 중요합니다. 이를 통해 데이터베이스에서 원하는 데이터를 쉽게 찾고 필요한 정보를 추출할 수 있습니다.
- 정렬(Sorting): 데이터를 오름차순 또는 내림차순으로 정렬하여 특정 패턴이나 트렌드를 쉽게 식별할 수 있습니다. 예를 들어, 판매 데이터를 날짜별로 정렬하면 시간 경과에 따른 판매 트렌드를 분석할 수 있습니다.
- 필터링(Filtering): 데이터베이스에서 특정 조건에 맞는 데이터를 추출하는 것입니다. 예를 들어, 특정 기간 동안의 판매 데이터나 특정 지역에서 발생한 판매 데이터만을 필터링하여 분석할 수 있습니다.
데이터베이스로부터 스프레드시트로 데이터 가져오기
데이터 분석을 위해 데이터베이스의 데이터를 스프레드시트로 가져오는 과정은 매우 중요합니다. 이를 위해 **SQL(Structured Query Language)**과 같은 도구를 사용하여 데이터베이스에 질의를 보내고 필요한 데이터를 추출할 수 있습니다. 추출한 데이터는 스프레드시트로 불러와서 추가적인 정리 및 분석을 진행할 수 있습니다.
데이터 분석 과정에서 메타데이터의 중요성
메타데이터는 데이터 분석의 모든 과정에서 중요한 역할을 합니다. 메타데이터가 없으면 데이터의 출처나 의미를 이해하기 어려워져 잘못된 결론에 이를 수 있습니다. 또한, 메타데이터는 데이터가 분석에 적합한지 여부를 결정하는 데 도움을 줍니다.
데이터베이스 기능
데이터베이스의 기본 개념
데이터베이스는 데이터를 체계적으로 저장하고 관리하는 시스템입니다. 데이터베이스는 다양한 형식의 데이터를 저장하고, 필요한 정보를 효율적으로 검색하고 수정할 수 있는 기능을 제공합니다. 특히 데이터베이스는 데이터 애널리스트가 데이터를 수집, 정리, 분석하는 데 필수적인 도구입니다.
관계형 데이터베이스(Relational Database)
관계형 데이터베이스는 데이터를 테이블 형식으로 저장하는 데이터베이스의 한 종류입니다. 각 테이블은 특정 주제에 관한 데이터를 저장하며, 여러 테이블이 서로 관계를 맺어 데이터를 체계적으로 관리합니다.
관계형 데이터베이스의 주요 특징:
- 테이블(Table): 데이터는 행(row)과 열(column)로 구성된 테이블에 저장됩니다.
- 레코드(Record): 각 행은 데이터베이스 내의 하나의 레코드를 나타냅니다.
- 필드(Field): 각 열은 특정 데이터 속성을 나타내며, 데이터의 유형을 정의합니다.
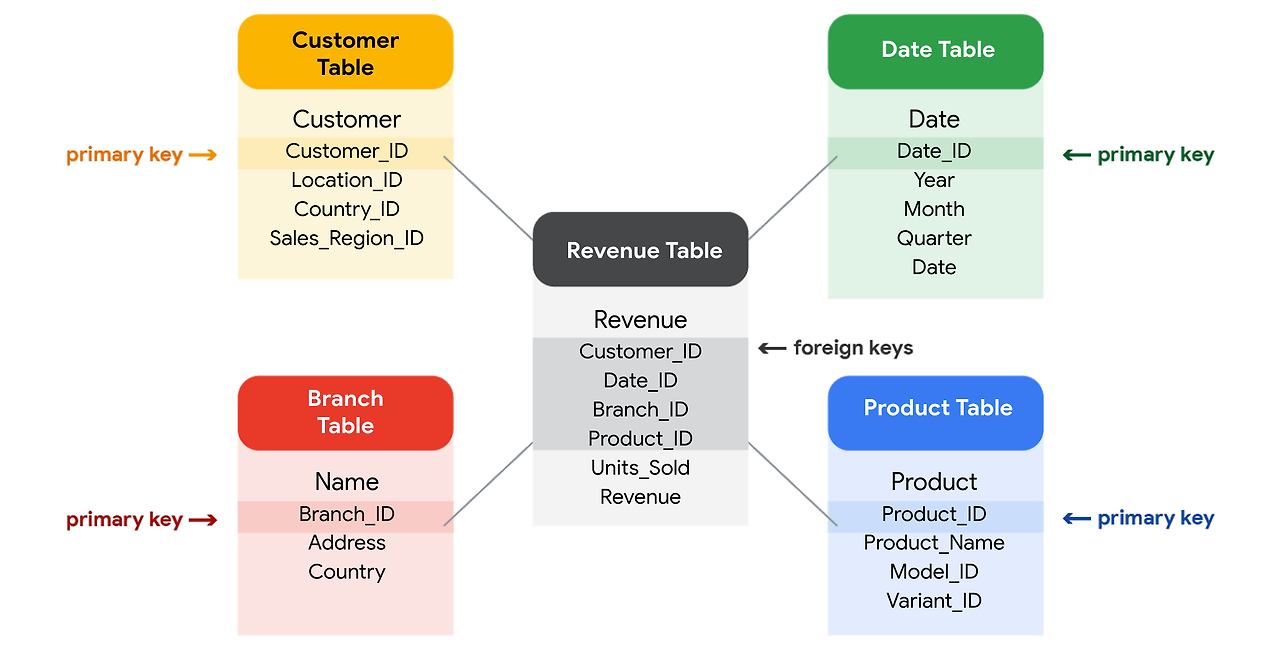
키(Key)의 개념
관계형 데이터베이스에서 키는 테이블 내의 데이터를 고유하게 식별하거나, 다른 테이블과의 관계를 정의하는 데 사용됩니다.
- 기본 키(Primary Key):
- 정의: 테이블 내의 각 레코드를 고유하게 식별하는 하나의 열(column)입니다.
- 특징:
- 기본 키는 고유한 값(unique value)을 가져야 하며, 각 행마다 유일해야 합니다.
- 기본 키는 null(빈 값)을 가질 수 없습니다.
- 테이블당 하나의 기본 키만 있을 수 있습니다.
- 예시:
- 'Car dealerships' 테이블에서 Branch ID가 기본 키일 수 있습니다. 이는 각 대리점의 고유 식별자를 나타냅니다.
- 'Product details' 테이블에서 VIN(Vehicle Identification Number)은 각 차량의 고유 식별자로 기본 키 역할을 합니다.
- 외래 키(Foreign Key):
- 정의: 다른 테이블의 기본 키를 참조하는 열입니다. 외래 키는 두 테이블 간의 관계를 정의합니다.
- 특징:
- 외래 키는 테이블의 특정 열을 사용하여 다른 테이블의 기본 키와 연결됩니다.
- 외래 키는 테이블에 여러 개 있을 수 있으며, 데이터베이스에서 데이터 무결성을 유지하는 데 중요한 역할을 합니다.
- 예시:
- 'Repair parts' 테이블에서 Part ID는 각 부품의 고유 식별자로 기본 키 역할을 합니다.
- 같은 테이블에서 VIN은 외래 키로 사용되어, 'Product details' 테이블의 차량과 연결됩니다.
관계형 데이터베이스의 구조 이해
관계형 데이터베이스에서 테이블 간의 관계를 정의하는 것은 데이터를 효율적으로 관리하고 분석하는 데 매우 중요합니다. 관계형 데이터베이스에서는 다음과 같은 방식으로 테이블 간 관계를 설정합니다:
- 일대일 관계(One-to-One): 한 테이블의 각 행이 다른 테이블의 행과 정확히 하나의 관계를 가질 때 사용됩니다.
- 일대다 관계(One-to-Many): 한 테이블의 각 행이 다른 테이블의 여러 행과 관계를 가질 때 사용됩니다. 예를 들어, 한 대리점은 여러 차량을 판매할 수 있습니다.
- 다대다 관계(Many-to-Many): 한 테이블의 여러 행이 다른 테이블의 여러 행과 관계를 가질 때 사용됩니다. 이 경우 중간 테이블을 사용하여 다대다 관계를 나타냅니다.
데이터베이스에서 데이터 분석
데이터 애널리스트는 데이터베이스를 사용하여 데이터를 수집하고, 정리하며, 분석합니다. 이를 통해 비즈니스 문제를 해결하거나 중요한 의사결정을 내리는 데 필요한 정보를 얻을 수 있습니다.
- 데이터 쿼리: SQL(Structured Query Language)과 같은 쿼리 언어를 사용하여 데이터베이스에서 필요한 데이터를 추출합니다.
- 데이터 정리: 추출한 데이터를 정리하고, 필요에 따라 데이터 클렌징(data cleansing)을 수행하여 분석에 적합한 상태로 만듭니다.
- 데이터 분석: 데이터를 분석하여 패턴을 발견하거나, 문제를 해결하기 위한 인사이트를 도출합니다.
데이터베이스는 데이터 애널리스트에게 필수적인 도구이며, 관계형 데이터베이스의 구조와 키의 개념을 이해하는 것은 데이터 분석의 기본입니다. 기본 키와 외래 키의 차이와 역할을 명확히 이해하면 데이터베이스 내에서 데이터를 효과적으로 관리하고 관계를 설정할 수 있습니다. 이를 바탕으로 다음 단계에서는 실제 데이터베이스에서 데이터를 불러오고 분석하는 방법을 배워보겠습니다.
데이터 애널리틱스에서의 데이터베이스
애널리스트는 데이터베이스에서 데이터를 조작, 보관, 처리하여 데이터를 훨씬 효율적으로 검색하고 가장 유용한 정보를 얻을 수 있습니다.

관계형 데이터베이스
관계형 데이터베이스는 연결되어 관계를 나타낼 수 있는 일련의 테이블을 포함하는 데이터베이스입니다. 관계형 데이터베이스를 활용하면 기본적으로 데이터의 공통점에 따라 데이터를 구성하고 연결할 수 있습니다.
비관계형 테이블에서는 분석 대상을 비롯해 모든 변수가 그룹화되어 있어 정렬하기가 까다로울 수 있습니다. 이런 이유로 데이터 분석에서는 관계형 데이터베이스를 흔히 사용합니다. 관계형 데이터베이스를 사용하면 수많은 분석 과정이 단순해지고 전체 데이터베이스에서 데이터를 쉽게 찾아 사용할 수 있습니다.
관계형 데이터베이스의 키
관계형 데이터베이스의 테이블은 공통 필드를 기준으로 연결됩니다. 이전에 기본 키와 외래 키에 대해 배운 내용을 기억하실 것입니다. 간단히 복습하자면 기본 키는 모든 값이 고윳값인 열을 참조하는 식별자입니다. 즉 해당 테이블의 각 레코드를 고유하게 식별하는 테이블의 열입니다. 특정 행의 기본 키 값은 전체 테이블에서 고유해야 합니다. 예를 들어
데이터베이스 언어: SQL
데이터베이스는 쿼리 언어라는 특수 언어를 사용합니다. 구조적 쿼리 언어(SQL)는 데이터 애널리스트가 데이터베이스와 상호작용하는 데 사용하는 쿼리 언어의 한 유형입니다. 데이터 애널리스트는 SQL로 쿼리를 작성해 더 큰 데이터 세트에서 원하는 특정 데이터를 볼 수 있습니다. 관계형 데이터베이스의 경우 데이터 애널리스트는 쿼리를 작성하여 관련 테이블에서 데이터를 가져옵니다. SQL은 데이터베이스 작업에 정말 유용한 도구이므로 앞으로 자세히 알아볼 것입니다.
메타 데이터를 통한 데이터 관리
메타데이터 살펴보기
메타데이터란 무엇인가?
**메타데이터(Metadata)**는 '데이터에 관한 데이터'를 의미합니다. 이는 데이터 자체는 아니지만, 데이터를 설명하고 정의하는 정보를 제공합니다. 예를 들어, 사진 파일을 찍었을 때 사진 자체는 데이터이지만, 사진이 찍힌 시간, 장소, 촬영 기기 정보 등은 메타데이터입니다. 메타데이터는 데이터를 더 잘 이해하고 조직하며, 필요한 정보를 더 쉽게 찾을 수 있도록 돕습니다.
일상생활에서의 메타데이터 예시
- 사진 메타데이터:
- 스마트폰으로 사진을 찍을 때마다 자동으로 생성됩니다.
- 메타데이터에는 사진이 찍힌 날짜, 시간, 위치, 사용된 기기 정보 등이 포함됩니다. 이는 사진 파일의 속성에서 확인할 수 있습니다. 예를 들어, 컴퓨터에서 사진 파일을 마우스 오른쪽 버튼으로 클릭하여 '속성(Properties)'을 확인하면 메타데이터를 볼 수 있습니다.
- 이메일 메타데이터:
- 이메일을 주고받을 때마다 메타데이터가 함께 전송됩니다.
- 메타데이터에는 이메일의 제목, 보낸 사람, 받는 사람, 전송된 날짜와 시간 등의 정보가 포함됩니다. 이메일의 메타데이터는 일반적으로 '원본 보기(View Original)' 또는 '메시지 세부 정보 보기(View Message Details)'에서 확인할 수 있습니다. 메타데이터는 또한 이메일이 전송된 후 얼마나 빨리 전달되었는지 등의 정보도 포함하고 있습니다.
메타데이터의 유형
데이터 애널리스트는 다양한 메타데이터를 사용하여 데이터의 맥락을 이해하고 분석합니다. 메타데이터는 세 가지 주요 유형으로 분류됩니다:
- 기술용 메타데이터 (Technical Metadata):
- 정의: 데이터의 기술적 특성을 설명합니다. 이는 데이터 식별, 인덱싱, 저장을 돕는 정보를 포함합니다.
- 예시:
- 도서의 ISBN(국제 표준 도서 번호), 저자, 제목 등이 포함됩니다.
- 파일 형식, 크기, 생성 날짜 등도 기술용 메타데이터입니다.
- 구조용 메타데이터 (Structural Metadata):
- 정의: 데이터의 구성 방식과 데이터 간의 관계를 설명합니다.
- 예시:
- 도서에서 페이지들이 어떻게 장으로 나뉘어 있는지, 즉 문서의 구조를 나타냅니다.
- 원고의 디지털 문서가 인쇄본의 실제 원본과 일치한다는 정보도 구조용 메타데이터에 포함됩니다.
- 구조용 메타데이터는 데이터 간의 관계를 추적하여 데이터 모음의 논리적 구조를 제공합니다.
- 관리용 메타데이터 (Administrative Metadata):
- 정의: 디지털 자산의 관리와 관련된 정보를 포함합니다. 이는 데이터의 사용, 접근 권한, 소유권 등을 관리하는 데 필요합니다.
- 예시:
- 사진 파일의 메타데이터, 즉 파일 형식, 생성 날짜, 촬영 기기 정보 등이 포함됩니다.
- 관리용 메타데이터는 데이터의 접근성, 보존, 권리 관리와 같은 관리적 측면을 지원합니다.
메타데이터의 중요성
메타데이터는 데이터베이스 관리와 데이터 분석에서 매우 중요합니다. 메타데이터는 데이터를 맥락 속에서 이해할 수 있도록 도와주며, 데이터를 검색, 조직화, 저장하는 데 중요한 역할을 합니다. 또한, 메타데이터는 데이터의 출처와 신뢰성을 확인하는 데 도움을 줍니다.
데이터 애널리스트는 메타데이터를 사용하여 데이터가 수집된 방법과 이유를 이해하고, 데이터의 신뢰성과 정확성을 평가하며, 데이터를 분석하는 데 필요한 추가 정보를 얻습니다. 예를 들어, 데이터의 출처와 수집 방법을 이해하면 데이터의 편향 가능성을 평가할 수 있습니다.
메타데이터는 데이터베이스와 데이터 분석에서 핵심적인 요소로, 데이터를 더 깊이 이해하고 효과적으로 활용할 수 있게 도와줍니다. 데이터 애널리스트는 메타데이터를 통해 데이터를 정확히 이해하고, 이를 바탕으로 데이터 기반의 결정을 내릴 수 있습니다. 데이터 분석에 있어 메타데이터의 중요성을 이해하는 것은 데이터 애널리스트로서의 성공을 위한 중요한 단계입니다.
데이터만큼 중요한 메타데이터
데이터 애널리틱스는 데이터 수집과 구성이 핵심인 분야입니다. 이 읽기 자료에서는 데이터의 모든 관점을 분석하고 완전히 이해하는 방법을 알아봅니다.

여러분이 찾은 데이터를 한번 보세요. 어떤 데이터인가요? 데이터의 출처는 무엇인가요? 데이터가 유용한가요? 판단할 수 있는 근거는 무엇인가요? 이러한 질문에 답하려면 메타데이터가 필요합니다. 메타데이터를 활용하면 데이터를 보다 심층적으로 이해할 수 있습니다. 간단히 말해서 메타데이터는 데이터에 관한 데이터입니다. 데이터베이스 관리에서 메타데이터는 다른 데이터에 관한 정보를 제공하고 데이터 애널리스트가 데이터베이스 내 데이터 콘텐츠를 해석하는 데 도움이 됩니다.
작업하는 데이터의 규모와 관계없이 메타데이터는 비즈니스 전반에 걸쳐 데이터와 관련된 의사소통 및 원활한 데이터 재사용에 도움이 되므로 유능한 애널리틱스 팀이라면 반드시 사용합니다. 본질적으로 메타데이터는 데이터의 육하원칙(언제, 어디서, 누가, 무엇을, 어떻게, 왜)을 알려줍니다.
메타데이터의 요소
메타데이터의 예를 살펴보기 전에 메타데이터가 일반적으로 제공하는 정보 유형을 이해해야 합니다.
제목 및 설명
조사 중인 파일 또는 웹사이트의 이름은 무엇인가요? 어떤 유형의 콘텐츠가 포함되어 있나요?
태그 및 카테고리
보유한 데이터의 일반적인 개요는 무엇인가요? 특정 방식으로 데이터에 색인을 지정하거나 데이터를 설명할 수 있나요?
제작자 및 제작 시기
데이터의 출처는 무엇이며, 언제 데이터가 생성되었나요? 최근에 생성되었나요, 아니면 오래전부터 있었나요?
마지막으로 수정한 사람 및 수정 시기
데이터에 변경사항이 있나요? 그렇다면 최근에 수정되었나요?
액세스 또는 업데이트 권한이 있는 사람
공개 데이터 세트인가요? 데이터 세트를 맞춤설정하거나 수정하려면 특별한 권한이 필요한가요?
메타데이터의 예
오늘날의 디지털 세계에서는 메타데이터가 어디에나 존재하며 상호 작용하는 많은 미디어와 정보에 메타데이터를 제공하는 일이 일반적인 관행이 되고 있습니다. 다음은 메타데이터를 찾을 수 있는 실제 예입니다.
사진
카메라로 사진을 캡처할 때마다 카메라 파일 이름, 날짜, 시간, 위치정보와 같은 메타데이터가 수집되어 사진과 함께 저장됩니다.
이메일
제목, 보낸 사람, 받는 사람, 보낸 날짜, 보낸 시간과 같이 이메일을 주고받을 때 표시되는 메타데이터가 있으며, 서버 이름, IP 주소, HTML 형식, 소프트웨어 세부정보를 포함하는 숨겨진 메타데이터도 있습니다.
스프레드시트 및 문서
스프레드시트와 문서에는 이미 상당한 양의 데이터가 있으므로 당연히 메타데이터도 함께 제공됩니다. 제목, 작성자, 만든 날짜, 페이지 수, 사용자 댓글, 탭 이름, 테이블 이름, 열 이름은 모두 스프레드시트와 문서에서 찾을 수 있는 메타데이터입니다.
웹사이트
모든 웹페이지에는 태그, 카테고리, 사이트 제작자 이름, 웹페이지 제목 및 설명, 생성 시간, 아이코노그래피와 같은 다양한 표준 메타데이터 필드가 있습니다.
디지털 파일
일반적으로 컴퓨터 파일을 마우스 오른쪽 버튼으로 클릭하면 파일의 메타데이터를 볼 수 있습니다. 파일 이름, 파일 크기, 생성 날짜, 수정 날짜, 파일 유형으로 구성됩니다.
도서
메타데이터는 디지털에 국한되지 않습니다. 모든 도서의 표지와 내부에는 제목, 저자 이름, 목차, 출판사 정보, 저작권 설명, 색인, 내용 요약을 알려주는 여러 표준 메타데이터가 있습니다.
데이터 파악의 이점
데이터의 콘텐츠 및 맥락뿐 아니라 구조를 파악하는 스킬은 데이터 애널리스트 커리어에 큰 도움이 됩니다. 데이터를 분석할 때는 항상 그림 전체를 이해해야 하며, 현재 데이터를 처리할 때뿐만 아니라 데이터를 결합할 때도 마찬가지입니다. 메타데이터는 향후 데이터를 찾고 사용하고 보존하고 재사용하는 데 유용합니다. 데이터 전체를 관리하고 사용할 책임은 데이터 애널리스트인 여러분에게 있으며, 메타데이터는 데이터 자체만큼이나 중요하다는 사실을 명심하세요.
애널리스트의 메타데이터 활용법
메타데이터를 사용하는 이유와 이점
- 데이터의 일관성과 균일성 유지:
- 메타데이터는 데이터를 일관되고 균일하게 유지하여, 데이터베이스가 단일 정보 소스로 작동할 수 있도록 돕습니다. 이를 통해 애널리스트는 데이터를 체계적으로 구성하고 분류할 수 있으며, 필요할 때 쉽게 접근할 수 있습니다.
- 데이터가 일관되게 유지되면 데이터베이스 내의 데이터와 외부 데이터 간의 관계를 쉽게 파악할 수 있습니다. 이는 데이터 분석 시에 매우 중요한 요소입니다.
- 데이터의 신뢰성 향상:
- 메타데이터는 데이터의 정확성, 정밀성, 관련성, 그리고 시기적절성을 보장하는 데 도움을 줍니다. 이렇게 하면 데이터의 품질이 향상되고, 데이터 애널리스트가 분석에서 더 나은 결과를 도출할 수 있습니다.
- 데이터의 신뢰성을 확보하면 애널리스트는 발생 가능한 문제의 근본 원인을 더 쉽게 식별하고, 이를 해결하기 위한 조치를 정확하게 취할 수 있습니다.
- 메타데이터 저장소의 활용:
- 메타데이터 저장소는 메타데이터를 중앙에서 관리하고 쉽게 접근할 수 있도록 돕는 시스템입니다. 이 저장소는 물리적일 수도 있고, 클라우드 기반일 수도 있으며, 메타데이터의 출처, 구조, 위치 등을 명확하게 설명합니다.
- 저장소를 통해 여러 소스의 데이터를 쉽게 통합할 수 있어, 다양한 데이터 분석 프로젝트를 효율적으로 수행할 수 있습니다. 메타데이터 저장소는 또한 누가 언제 메타데이터에 접근했는지 추적할 수 있어, 보안 및 접근 관리 측면에서도 유리합니다.
- 외부 데이터의 신뢰성 평가:
- 데이터 애널리스트는 종종 내부 데이터뿐만 아니라 서드 파티(Third-party) 데이터와 같은 외부 데이터도 사용해야 합니다. 이 경우 데이터의 신뢰성과 품질에 대해 확신이 필요합니다.
- 메타데이터를 통해 외부 데이터의 수집 방식, 정확성, 관련성 등을 평가할 수 있습니다. 이는 외부 소스의 데이터가 신뢰할 만하고, 분석에 적합한지 판단하는 데 큰 도움이 됩니다.
- 데이터 사용 권한 확인:
- 외부 데이터와 작업할 때, 데이터 사용 권한을 확인하는 것이 중요합니다. 메타데이터는 데이터의 소유자, 접근 권한, 사용 제한 사항 등을 명확히 하는 정보를 제공하여 법적 문제를 방지할 수 있습니다.
실제 사례: Google에서의 데이터 분석
Google에서 데이터 애널리스트로 일하는 경우, 다양한 유형의 데이터를 분석하게 됩니다. 여기에는 내부 데이터뿐만 아니라, 서드 파티 데이터와 같은 외부 데이터도 포함됩니다. 이 경우 메타데이터는 데이터를 이해하고 신뢰성을 보장하는 데 중요한 역할을 합니다.
- 서드 파티 데이터 사용: 서드 파티 데이터는 외부 소스에서 수집된 데이터로, 그 품질과 신뢰성에 대한 불확실성이 있을 수 있습니다. 메타데이터를 통해 이 데이터가 어떻게 수집되었고, 얼마나 정확한지 평가할 수 있습니다. 이를 통해 애널리스트는 데이터가 분석에 적합한지 결정할 수 있습니다.
- 데이터의 신뢰성 확보: 메타데이터는 데이터를 수집한 방법, 시기, 출처 등을 설명하여 데이터가 신뢰할 수 있는지 확인할 수 있게 합니다. 데이터가 신뢰할 수 없다면 그 결과도 신뢰할 수 없으므로, 메타데이터는 데이터 분석의 기초를 형성합니다.
메타데이터는 데이터 애널리스트가 데이터를 효과적으로 사용하고 관리하는 데 필수적인 도구입니다. 메타데이터를 통해 데이터의 일관성, 신뢰성, 그리고 정확성을 보장할 수 있으며, 데이터 분석 과정에서 발생할 수 있는 다양한 문제를 해결하는 데 큰 도움이 됩니다. 메타데이터 저장소와 같은 시스템을 활용하면 데이터 관리와 분석을 더욱 효율적으로 수행할 수 있습니다.
메타데이터 관리
메타데이터의 중요성과 이점
메타데이터는 데이터 애널리스트가 데이터를 관리하고 분석하는 데 필수적인 도구입니다. 데이터가 일관되고 정확하며 신뢰할 수 있는지 보장하기 위해 메타데이터는 다음과 같은 역할을 합니다:
- 단일 정보 소스 생성: 메타데이터와 메타데이터 저장소는 모든 데이터에 대해 일관된 정보를 제공하는 중앙 위치를 제공합니다. 이를 통해 데이터베이스 내의 데이터를 체계적으로 관리하고 분석할 수 있습니다.
- 데이터 접근성 향상: 메타데이터는 데이터에 쉽게 접근하고 사용하게 하는 프로세스를 표준화합니다. 이를 통해 데이터 애널리스트와 다른 이해관계자들이 필요한 데이터를 빠르고 효율적으로 찾을 수 있습니다.
- 데이터 품질 관리: 메타데이터는 데이터의 정확성, 정밀성, 관련성, 시기적절성을 보장하는 역할을 합니다. 메타데이터를 통해 데이터 애널리스트는 데이터를 보다 신뢰성 있게 관리할 수 있습니다.
메타데이터 애널리스트의 역할
메타데이터 애널리스트는 메타데이터와 관련된 여러 가지 책임을 맡고 있습니다. 그들의 주요 역할은 회사의 데이터 품질을 보장하고 데이터를 쉽게 찾고 사용할 수 있도록 지원하는 것입니다.
- 데이터 식별 정보와 검색 정보 생성: 메타데이터 애널리스트는 각 데이터 세트의 기본적인 식별 정보와 검색 정보를 만듭니다. 이러한 정보는 데이터베이스 내의 데이터를 체계적으로 분류하고, 쉽게 접근할 수 있게 합니다.
- 데이터 연결 방식 설명: 메타데이터는 다양한 시스템 간의 데이터가 어떻게 연결되어 있는지를 설명합니다. 이를 통해 데이터 애널리스트는 여러 출처의 데이터를 통합하여 분석할 수 있습니다.
- 데이터 구성 모델 생성: 메타데이터 애널리스트는 데이터의 표준화된 구성을 위해 데이터 구성 모델을 만듭니다. 이 모델은 데이터가 어떻게 저장되고, 접근되고, 사용되는지를 설명합니다.
- 데이터 거버넌스 지원: 메타데이터 애널리스트는 데이터 거버넌스를 지원합니다. 데이터 거버넌스는 데이터의 보안, 개인정보 보호, 무결성, 사용성 등을 관리하는 절차로, 메타데이터는 이러한 절차를 지원하는 데 중요한 역할을 합니다.
- 협업 및 지원: 메타데이터 애널리스트는 다른 팀원들과의 협업을 통해 데이터를 관리하고, 필요한 경우 데이터에 대한 접근을 지원합니다. 이들은 조직 내 다양한 이해관계자와 협력하여 데이터 활용을 극대화하고, 데이터 기반 의사결정을 돕습니다.
메타데이터 애널리스트와 데이터 애널리스트의 차이점
- 메타데이터 애널리스트는 주로 데이터의 구조와 관리, 거버넌스에 중점을 둡니다. 이들은 데이터를 체계적으로 구성하고, 저장소를 관리하며, 데이터 품질을 보장하는 역할을 합니다.
- 데이터 애널리스트는 데이터를 분석하고 해석하여 인사이트를 도출하는 데 중점을 둡니다. 이들은 데이터에서 패턴을 찾고, 비즈니스 의사결정을 지원하는 역할을 합니다.
이 두 역할 모두 데이터를 중심으로 하지만, 데이터 애널리스트가 데이터를 직접 분석하여 비즈니스 문제를 해결하는 데 집중하는 반면, 메타데이터 애널리스트는 데이터의 조직, 관리, 접근성을 보장하는 데 집중합니다.
메타데이터와 메타데이터 저장소는 데이터 애널리스트와 메타데이터 애널리스트 모두에게 필수적인 도구입니다. 메타데이터는 데이터를 일관성 있게 유지하고, 쉽게 접근할 수 있게 하며, 데이터의 품질을 보장하는 역할을 합니다. 메타데이터 애널리스트는 이 모든 과정을 지원하고, 데이터가 조직 내에서 효과적으로 사용될 수 있도록 돕습니다. 데이터에 대한 깊은 이해와 관리 능력을 가지고 있으며, 다양한 이해관계자와 협력하여 데이터 중심의 문제 해결을 지원하는 역할을 수행합니다.
다양한 데이터 소스의 액세스
다양한 소스의 데이터 작업
내부 데이터와 외부 데이터의 정의
- 내부 데이터:
- 정의: 내부 데이터는 회사 내부에서 생성되고, 회사의 자체 시스템에 저장된 데이터입니다. 보통 회사의 운영, 고객, 판매, 재무 등과 관련된 정보를 포함하고 있습니다.
- 예시: 내부 데이터에는 매출 데이터, 고객 데이터, 마케팅 캠페인 성과, 직원 정보 등이 포함될 수 있습니다.
- 특징: 내부 데이터는 회사가 이미 소유하고 있기 때문에 추가 비용 없이 사용할 수 있으며, 문제 해결에 필요한 맞춤형 정보를 제공할 수 있습니다. 그러나 부서마다 데이터가 분산되어 있고, 수집과 정리가 복잡할 수 있습니다.
- 외부 데이터:
- 정의: 외부 데이터는 회사 외부에서 생성되고, 다양한 외부 출처에서 수집된 데이터입니다. 외부 데이터는 여러 형태로 존재하며, 공개 데이터와 상업적 목적으로 판매되는 데이터 등을 포함합니다.
- 예시: 외부 데이터에는 시장 조사 보고서, 경쟁사 데이터, 정부의 공개 데이터, 뉴스 기사, 소셜 미디어 데이터 등이 포함될 수 있습니다.
- 특징: 외부 데이터는 내부 데이터로는 알 수 없는 새로운 인사이트를 제공하며, 회사의 데이터를 보완하는 데 사용될 수 있습니다. 예를 들어, 시장 트렌드, 경제 지표, 소비자 행동 패턴 등을 분석할 때 유용합니다.
내부 데이터와 외부 데이터의 활용 사례
- 내부 데이터의 활용:
- 비용 효율적: 회사가 이미 소유한 데이터이기 때문에 비용이 들지 않습니다.
- 관련성 높은 정보 제공: 회사의 내부 프로세스와 직접 관련된 데이터를 제공하여 문제 해결과 의사결정에 도움이 됩니다.
- 데이터 일관성: 데이터 애널리스트는 한 시스템 내에서 일관된 데이터를 사용할 수 있어 분석의 정확성을 높일 수 있습니다.
- 외부 데이터의 활용:
- 전체 그림 파악: 외부 데이터를 통해 내부 데이터만으로는 얻을 수 없는 더 넓은 맥락을 이해할 수 있습니다.
- 다양한 관점 제공: 외부 데이터는 시장, 경제, 경쟁 상황 등 외부 환경에 대한 정보를 제공하여 분석에 다양한 관점을 더합니다.
- 공개 데이터의 활용: 정부나 기타 조직에서 제공하는 공개 데이터는 무료로 사용할 수 있으며, 사회적, 경제적, 환경적 이슈를 분석하는 데 유용합니다.
데이터 애널리스트의 역할
데이터 애널리스트는 내부와 외부 데이터를 수집, 정리, 분석하여 비즈니스 의사결정에 필요한 인사이트를 도출합니다. 이를 위해 다양한 부서와 협력하여 필요한 데이터를 수집하고, 외부 소스로부터 데이터를 가져와서 내부 데이터와 결합합니다.
- 내부 데이터의 수집: 데이터 애널리스트는 회사 내의 다양한 부서와 협력하여 필요한 데이터를 수집합니다. 예를 들어, 마케팅 팀에서 판매 데이터를, 인사팀에서 직원 데이터를 요청할 수 있습니다.
- 외부 데이터의 수집: 외부 데이터는 다양한 출처에서 얻을 수 있으며, 데이터 애널리스트는 이러한 출처를 파악하고 필요한 데이터를 적절히 활용합니다. 예를 들어, 정부의 공개 데이터베이스에서 사회 경제적 데이터를 다운로드하거나, 시장 조사 기관에서 제공하는 보고서를 구매할 수 있습니다.
- 데이터 분석: 데이터를 수집한 후, 데이터 애널리스트는 데이터를 정리하고, 분석하여 의미 있는 인사이트를 도출합니다. 이를 통해 비즈니스 문제를 해결하고, 전략적 결정을 지원합니다.
내부 데이터와 외부 데이터는 데이터 애널리스트가 데이터를 분석하고 비즈니스 문제를 해결하는 데 필수적인 두 가지 데이터 유형입니다. 내부 데이터는 회사의 운영과 관련된 중요한 정보를 제공하며, 외부 데이터는 더 넓은 맥락을 제공하여 분석의 폭을 넓힙니다. 두 데이터 유형 모두를 효과적으로 활용하는 것이 데이터 애널리스트의 핵심 역량 중 하나입니다.
스프레드시트 및 데이터베이스의 데이터 가져오기
CSV 파일 가져오기 과정 요약
CSV 파일은 데이터 분석에 매우 유용한 파일 형식으로, 데이터를 테이블 형식으로 저장하여 쉽게 접근하고 사용할 수 있게 합니다. CSV는 "쉼표로 구분된 값"을 의미하며, 각 데이터 항목은 쉼표로 구분되어 있습니다. CSV 파일을 스프레드시트로 가져오는 과정은 다음과 같습니다:
- 스프레드시트 애플리케이션 열기: Excel, Google 스프레드시트 등 사용 중인 스프레드시트 애플리케이션을 엽니다.
- 파일 가져오기: 메뉴에서 'File'을 선택하고 'Import'를 클릭하여 CSV 파일을 가져옵니다.
- 파일 선택 및 업로드: 가져오려는 CSV 파일이 저장된 위치로 이동하여 해당 파일을 선택하고 열기(Open)를 클릭합니다.
- 새 시트로 데이터 삽입: 데이터를 가져올 방법을 선택합니다. 예를 들어, 새 시트로 삽입하거나 기존 시트에 추가할 수 있습니다.
- 데이터 포맷 검토: 가져온 데이터가 올바르게 표시되는지 확인합니다. 만약 데이터가 구분자로 인해 제대로 나누어지지 않았다면, 옵션을 수정하여 올바르게 구분되도록 합니다.
- 데이터 변환 옵션 선택: 필요에 따라 텍스트 데이터를 숫자 형식이나 다른 형식으로 변환할 수 있는 옵션을 선택합니다.
- 데이터 가져오기 완료: 'Import data' 버튼을 클릭하여 데이터를 스프레드시트로 가져옵니다. 이제 데이터를 검토하고 필요한 대로 분석을 시작할 수 있습니다.
실제 데이터 수집과 활용
CSV 파일을 가져오는 것은 데이터 애널리스트가 여러 데이터 소스에서 데이터를 수집하여 분석 가능한 형태로 만드는 기본적인 단계입니다. 예를 들어:
- 외부 데이터 세트 활용: Google의 의료 데이터 애널리스트로서 다양한 데이터 소스를 사용하여 특정 주제에 관한 통찰을 도출합니다. 원격 의료 서비스의 검색 트렌드와 같은 특정 데이터를 분석하기 위해, 외부 데이터 소스에서 관련 데이터를 수집하고 이를 스프레드시트로 가져옵니다.
- 오픈소스 데이터 액세스: 세계보건기구(WHO)와 같은 기관에서 제공하는 오픈소스 데이터 저장소를 활용할 수 있습니다. 이러한 저장소에서 데이터를 다운로드하고 CSV 파일로 저장한 후 스프레드시트로 가져와 데이터를 분석합니다.
데이터 정리 및 준비
스프레드시트로 데이터를 가져온 후에는 데이터를 정리하고 준비하는 과정이 필요합니다. 이 과정에서는 다음과 같은 작업을 수행할 수 있습니다:
- 데이터 정렬: 특정 기준(예: 날짜, 알파벳 순서 등)에 따라 데이터를 정렬하여 쉽게 분석할 수 있습니다.
- 데이터 필터링: 원하는 데이터만 선택적으로 볼 수 있도록 필터를 적용합니다. 예를 들어, 특정 연도나 국가의 데이터만을 필터링할 수 있습니다.
- 데이터 클렌징: 가져온 데이터가 오류 없이 정확한지 확인하고, 불필요한 데이터나 중복 데이터를 제거하여 클린 데이터를 만듭니다.
공개 데이터 세트 살펴보기
공개 데이터는 데이터 기반 의사결정을 위해 액세스하는 수많은 공개 데이터 세트를 생성하는 데 도움이 됩니다. 다음은 공개 데이터 세트를 직접 검색하기 위해 사용할 수 있는 몇 가지 리소스입니다.
- Google Cloud 공개 데이터 세트: 데이터 애널리스트가 수요가 많은 공개 데이터 세트에 액세스할 수 있으며 클라우드에서 유용한 정보를 쉽게 찾을 수 있습니다.
- 데이터 세트 검색: 키워드 검색을 통해 온라인에서 사용 가능한 데이터 세트를 찾는 데 도움이 됩니다.
- Kaggle: 연습할 데이터 세트를 찾는 데 도움이 되는 공개 데이터 검색 기능이 있습니다.
- BigQuery: 액세스 및 사용 가능한 150개 이상의 공개 데이터 세트를 호스팅합니다.
보건 공개 데이터 세트
- 전 세계 보건 관측 데이터: 이 페이지에 나와 있는 데이터 세트를 검색하거나 세계보건기구의 주요 데이터 모음을 살펴볼 수 있습니다.
- TCIA(The Cancer Imaging Archive) 데이터 세트: 앞서 소개된 데이터 세트와 마찬가지로 여기의 데이터는 Google Cloud 공개 데이터 세트에서 호스팅되며 BigQuery에 업로드할 수 있습니다.
- 1000 Genomes: Google Cloud 공개 리소스의 또 다른 데이터 세트이며 BigQuery에 업로드할 수 있습니다.
기후 공개 데이터 세트
- 국내 기후 데이터 센터: NCDC 빠른 링크 페이지에서 살펴볼 데이터 세트를 선택할 수 있습니다.
- NOAA Public Dataset Gallery: NOAA Public Dataset Gallery에는 검색 가능한 공개 데이터 세트 모음이 있습니다.
사회 정치 공개 데이터 세트
- UNICEF State of the World’s Children: UNICEF의 데이터 세트에는 다운로드할 수 있는 테이블 모음이 있습니다.
- CPS Labor Force Statistics: 이 페이지에는 사용 가능한 여러 데이터 세트 링크가 나와 있습니다.
- The Stanford Open Policing Project: 여기의 데이터 세트는 .CSV 파일로 다운로드하여 직접 사용할 수 있습니다.
정렬 및 필터링
정렬 및 필터링
정렬 (Sorting)
정렬은 데이터를 의미 있는 순서로 배열하여 보다 쉽게 분석하고 시각화할 수 있도록 하는 기능입니다. 정렬의 주요 옵션과 활용 방법은 다음과 같습니다:
- 정렬 옵션:
- 오름차순 (Ascending): 숫자는 낮은 값에서 높은 값으로, 텍스트는 알파벳 순서로 정렬됩니다.
- 내림차순 (Descending): 숫자는 높은 값에서 낮은 값으로, 텍스트는 알파벳 역순으로 정렬됩니다.
- 단일 열 정렬: 특정 열을 기준으로 데이터를 정렬합니다.
- 다중 열 정렬: 여러 열을 기준으로 우선순위를 정하여 데이터를 정렬합니다.
- 정렬 방법:
- 헤더 고정: 정렬 시 헤더가 고정되면 각 열의 카테고리를 알 수 있습니다. View 메뉴에서 Freeze를 선택하고 1 row를 클릭하여 헤더를 고정할 수 있습니다.
- 정렬 실행: 특정 열을 선택한 후 드롭다운 화살표를 클릭하여 정렬 옵션을 선택합니다. 여러 기준으로 정렬하려면 Data 메뉴에서 Sort range를 선택하고, Add another sort column을 사용하여 추가 기준을 설정합니다.
필터링 (Filtering)
필터링은 특정 조건을 충족하는 데이터만 표시하고 나머지는 숨길 수 있는 기능입니다. 필터링의 주요 기능과 활용 방법은 다음과 같습니다:
- 필터 생성:
- Data 메뉴에서 Create a filter를 선택하여 필터를 적용합니다.
- 필터를 적용할 열을 선택한 후, 각 열 헤더에 나타나는 필터 버튼을 클릭하여 필터링 조건을 설정합니다.
- 필터 조건 설정:
- 필터 버튼을 클릭하여 원하는 값을 선택하거나 체크박스를 해제하여 특정 조건을 충족하지 않는 항목을 숨깁니다.
- 필터링 결과는 조건을 충족하지 않는 모든 항목을 일시적으로 숨깁니다. 전체 데이터를 다시 보려면 필터를 끄면 됩니다.
정렬과 필터링의 활용 예
- 정렬: 영업 담당자 목록을 근무 도시와 주별로 정렬하여 특정 지역의 담당자를 쉽게 찾을 수 있습니다.
- 필터링: 특정 제품 카테고리(예: 'Rims')에 해당하는 영업 담당자만 표시하여 필요한 정보를 추출할 수 있습니다.
정렬과 필터링은 데이터 애널리스트가 대규모 데이터를 효과적으로 관리하고 분석하는 데 필수적인 도구입니다. 이 두 기능을 사용하면 데이터의 복잡성을 줄이고 필요한 정보를 신속하게 찾을 수 있습니다.
SQL을 사용한 대규모 데이터 세트 작업
샌드박스, 결제 옵션을 비롯한 BigQuery 설정
BigQuery 계정 등급
BigQuery는 여러 가지 계정 옵션을 제공하여 사용자가 자신의 필요에 맞는 적합한 계정을 선택할 수 있습니다. 현재는 두 가지 주요 계정 유형을 사용할 수 있습니다: 샌드박스와 무료 체험입니다.
1. 샌드박스 계정
- 장점:
- 무료로 제공되며 Google 계정으로 로그인하여 사용할 수 있습니다.
- 데이터베이스에 대한 기본적인 탐색과 SQL 쿼리 실행이 가능합니다.
- 제한 사항:
- 한 번에 사용할 수 있는 프로젝트 수가 최대 12개로 제한됩니다. 13번째 프로젝트를 만들려면 기존 프로젝트 중 하나를 삭제해야 합니다.
- 데이터 조작 언어(DML) 작업, 즉 데이터 삽입이나 업데이트는 지원되지 않습니다.
- 일부 고급 기능에 접근할 수 없습니다.
샌드박스 계정은 기본적인 데이터 탐색과 학습에는 적합하지만, 실제 데이터 조작이 필요한 활동에는 제약이 있을 수 있습니다.
2. 무료 체험 계정
- 장점:
- Google Cloud에서 제공하는 300달러의 크레딧을 사용하여 다양한 BigQuery 기능을 사용할 수 있습니다.
- SQL 쿼리 연습에 충분한 크레딧을 제공합니다.
- 90일 동안 사용할 수 있으며, 이 기간 동안 대부분의 기능을 거의 제한 없이 사용할 수 있습니다.
- 제한 사항:
- 무료 체험 기간이 종료되면 계정 업그레이드 또는 비용 청구가 필요합니다.
- 체험 종료 후에도 결제 정보를 입력해야 하며, 자동으로 비용이 청구되지 않으나 결제 옵션을 설정해야 합니다.
무료 체험 계정은 더 많은 기능을 제공하며, 시간이 충분한 동안 다양한 BigQuery 기능을 시험해볼 수 있습니다.
계정 설정 방법
1. 샌드박스 계정 설정
- BigQuery 샌드박스 문서 페이지로 이동: Google 검색 또는 BigQuery 공식 문서 페이지를 통해 접근할 수 있습니다.
- Google 계정으로 로그인: 오른쪽 상단에서 로그인 버튼을 클릭하고, BigQuery 샌드박스 계정에 사용할 Google 계정으로 로그인합니다.
- ‘Go to BigQuery’ 버튼 클릭: 문서 페이지에서 이 버튼을 선택합니다.
- 국가 선택 및 서비스 약관 동의: 드롭다운 목록에서 국가를 선택하고, 서비스 약관에 동의합니다.
- SQL 작업공간으로 이동: SQL 작업공간으로 이동하여 ‘Create Project’를 선택합니다.
- 프로젝트 이름과 ID 지정: 원하는 프로젝트 이름과 ID를 입력합니다.
- ‘Create’와 ‘Done’ 선택: 프로젝트가 생성된 후 ‘Create’와 ‘Done’을 차례로 클릭하여 완료합니다.
2. 무료 체험 계정 설정
- Google Cloud 무료 체험 페이지로 이동: Google Cloud 웹사이트에서 무료 체험 페이지를 찾습니다.
- 계정 설정: Google Cloud 계정을 만들고 결제 정보를 입력하여 무료 체험을 활성화합니다.
- 크레딧 사용: 제공된 300달러 크레딧을 사용하여 BigQuery와 다른 Google Cloud 서비스를 활용합니다.
BigQuery 샌드박스와 무료 체험 계정은 각각의 필요에 따라 적절하게 선택할 수 있습니다. 샌드박스 계정은 제한된 기능으로 기본적인 작업에 적합하며, 무료 체험 계정은 더 많은 기능을 시험해볼 수 있는 기회를 제공합니다. 계정을 설정한 후에는 SQL 작업공간을 활용하여 다양한 데이터를 분석해 보세요.
BigQuery 사용법
BigQuery SQL 작업공간 사용 요약
- BigQuery 방문 및 로그인
- BigQuery 웹사이트로 이동한 후, 생성한 계정으로 로그인합니다.
- 화면 왼쪽의 메뉴에서 ‘Big Data’까지 스크롤한 후 ‘BigQuery’를 선택하여 SQL 작업공간으로 이동합니다.
- 공개 데이터 세트 검색 및 선택
- ‘Explorer’ 메뉴에서 공개 데이터 세트를 선택합니다.
- ‘Add Data’ 버튼을 클릭하고 ‘Explore public datasets’를 선택하여 마켓플레이스를 열고 원하는 데이터 세트를 검색합니다.
- 예를 들어 ‘Noaa_lightning’ 데이터 세트를 선택하고, 데이터 세트의 설명을 확인한 후 ‘View dataset’을 클릭합니다.
- 데이터 세트 미리보기 및 쿼리 작성
- ‘Explorer’ 메뉴에서 원하는 데이터 세트를 선택합니다.
- ‘Schema’ 탭에서 데이터 세트의 열 이름을 확인하고, ‘Details’ 탭에서 추가 메타데이터를 확인합니다.
- ‘Preview’ 탭에서 데이터 세트의 첫 번째 행을 미리 봅니다.
- ‘Query’ 버튼을 클릭하여 새로운 쿼리 편집 창을 열고, SQL 쿼리를 작성하여 실행합니다.
- 자체 데이터 업로드
- 원하는 프로젝트 ID를 선택한 후, 점 3개 아이콘을 클릭하여 프로젝트 옵션을 연 다음 ‘Create dataset’을 선택합니다.
- 데이터 세트의 이름을 지정하고 ‘Create dataset’을 클릭합니다.
- ‘Explorer’ 메뉴에서 데이터 세트를 선택한 후, ‘Create table’을 클릭합니다.
- ‘Create table from’에서 ‘Upload’를 선택하고, CSV 파일 등 원하는 파일을 업로드합니다.
- 테이블에 적절한 이름을 설정하고 ‘Auto detect’로 스키마를 설정한 후 ‘Create table’을 클릭합니다.
참고 사항
- 인터페이스 차이: BigQuery 인터페이스는 지속적으로 업데이트되므로 화면의 구성이 다를 수 있습니다. 그러나 기본적인 작업 방식은 유사합니다.
- 쿼리 실행 결과: 쿼리를 실행하면 결과가 편집기 인터페이스 아래의 창에 표시됩니다. 이는 데이터 세트의 행을 반환하는 방식입니다.
- 연습과 반복: BigQuery의 다양한 기능을 익히려면 이 동영상을 반복 시청하고, 실제 데이터를 사용하여 연습하는 것이 좋습니다.
활용 방법
- 데이터 분석: BigQuery SQL을 사용하여 대량의 데이터를 분석하고 인사이트를 도출합니다.
- 데이터 업로드 및 관리: 자체 데이터를 BigQuery에 업로드하여 분석할 수 있으며, 데이터 세트를 효과적으로 관리합니다.
- 공개 데이터 활용: 공개 데이터 세트를 활용하여 다양한 분석을 시도하고, 다른 데이터 세트와의 관계를 탐색합니다.
BigQuery 실제 활용
데이터베이스에서 데이터를 정렬하고 필터링하여 원하는 정보를 얻는 것은 데이터 애널리스트에게 매우 중요한 기술입니다. 스프레드시트에서 데이터를 조작하는 것과 유사하지만, 데이터베이스에서 SQL을 사용하면 훨씬 더 강력하고 유연한 방식으로 대량의 데이터를 처리할 수 있습니다.
SQL 쿼리 작성 개요
- 쿼리 시작:
- SELECT: 조회할 열을 지정합니다. 모든 열을 선택할 때는 *를 사용합니다.
- FROM: 데이터가 위치한 테이블을 지정합니다.
- 전체 데이터 조회:이 쿼리는 solar_potential_by_postal_code 테이블의 모든 데이터를 조회합니다.
-
sql코드 복사SELECT * FROM `solar_potential_by_postal_code`;
- 특정 조건에 맞는 데이터 조회:
- WHERE: 특정 조건을 지정하여 원하는 데이터만 필터링합니다.
- 예를 들어, 펜실베이니아의 데이터만 보고 싶을 때는 다음과 같이 쿼리를 작성합니다:
이 쿼리는 state_name 열이 'Pennsylvania'인 데이터만 반환합니다.sql코드 복사SELECT * FROM `solar_potential_by_postal_code` WHERE state_name = 'Pennsylvania'; - 쿼리 작성 팁:
- 쿼리 형식: SQL 쿼리는 여러 줄로 작성해도 되고, 한 줄로 작성해도 됩니다. 형식이 달라도 결과는 동일합니다.
- 공백과 줄 바꿈: 쿼리를 가독성 있게 유지하려면 공백과 줄 바꿈을 적절히 사용하세요. 이는 쿼리를 읽기 쉽게 만들어 줍니다.
메타데이터와 SQL 쿼리의 연결
- 메타데이터의 역할: 메타데이터는 데이터베이스의 구조와 내용을 설명합니다. 이를 통해 데이터베이스의 테이블과 열을 이해하고, 필요한 데이터를 찾는 데 도움을 줍니다.
- 데이터베이스 탐색: 테이블 뷰어에서 데이터를 미리 보고, 데이터 세트의 구조와 내용을 이해한 후 쿼리를 작성합니다.
데이터 탐정의 역할
지금까지 배운 내용을 종합하여 데이터 애널리스트로서의 역할을 확립할 수 있습니다. 메타데이터를 활용하여 데이터를 이해하고, SQL 쿼리를 작성하여 필요한 정보를 추출함으로써 비즈니스 문제를 해결할 수 있습니다.
BigQuery 사용
BigQuery는 Google Cloud의 데이터 웨어하우스로 데이터 애널리스트가 대규모 데이터 세트를 쿼리 및 필터링하고 결과를 집계하고 복잡한 작업을 처리할 수 있는 플랫폼입니다.
다음 활동에서는 BigQuery를 활용한 작업을 진행합니다. 이 읽기 자료에는 직접 BigQuery 계정을 생성하고 공개 데이터 세트를 선택하고 CSV 파일을 업로드하는 방법이 나와 있습니다. 읽기 자료를 완료하고 나면 활동을 진행하는 데 필요한 BigQuery 콘솔 액세스 가능 여부를 확인할 수 있습니다.
참고: BigQuery 대신 다른 SQL 데이터베이스 플랫폼으로 작업하는 경우를 위해 이 읽기 자료 마지막 부분에는 다른 플랫폼의 시작 안내 리소스도 나와 있습니다.
BigQuery 계정 유형
BigQuery 계정에는 샌드박스와 무료 체험의 두 가지 유형이 있습니다. 샌드박스 계정을 사용하면 무료로 쿼리를 연습하고 공개 데이터 세트를 살펴볼 수 있지만 표준 할당량 및 한도와 추가 제한사항이 있습니다. 표준 한도로 BigQuery를 사용하려면 무료 체험 계정을 설정하세요. 자세한 내용은 다음과 같습니다.
- 무료 샌드박스 계정에는 결제 수단이 필요하지 않습니다. 하지만 프로젝트 개수가 12개로 제한됩니다. 또한 데이터베이스에 새 레코드를 삽입하거나 기존 레코드의 필드 값을 업데이트할 수 없습니다. 이러한 DML(데이터 조작 언어) 작업은 샌드박스에서 지원되지 않습니다.
- 무료 체험 계정에는 청구 가능한 계정을 설정하기 위해 결제 수단이 필요하지만 체험 기간 동안 모든 기능을 사용할 수 있습니다.
두 계정 유형 모두 기존 프로젝트를 모두 유지하면서 언제든지 유료 계정으로 업그레이드할 수 있습니다. 무료 체험 계정을 설정하고 유료 계정으로 업그레이드하지 않기로 했다면 체험 기간이 종료되었을 때 무료 샌드박스 계정을 설정해도 됩니다. 그러나 체험 계정의 프로젝트는 샌드박스 계정으로 이전되지 않습니다. 처음부터 다시 시작해야 합니다.
수료증 과정에서 사용할 무료 샌드박스 계정 설정
- 단계별 안내를 따르거나 샌드박스, 결제 옵션을 비롯한 BigQuery 설정 동영상을 시청하세요.
- 샌드박스 사용법에 관한 자세한 내용은 BigQuery 샌드박스 사용 설정 문서를 참고하세요.
계정을 설정하면 BigQuery 콘솔 상단의 배너와 SANDBOX에 계정으로 생성한 프로젝트 이름이 표시됩니다.

무료 체험 계정 설정(원하는 경우)
샌드박스 제한사항 없이 BigQuery를 사용하려면 수료증 과정에서 사용할 무료 체험 계정을 설정하세요.
- 단계별 안내를 따르거나 샌드박스, 결제 옵션을 비롯한 BigQuery 설정 동영상을 시청하세요. 무료 체험의 경우 향후 90일 동안 사용 가능한 300달러의 크레딧 혜택이 제공됩니다. 이는 SQL 쿼리를 연습하는 목적으로만 BigQuery 콘솔을 사용한다면 넉넉한 지출 한도입니다. 300달러 크레딧을 사용한 후(또는 90일이 경과한 후)에는 무료 체험이 만료되며, BigQuery를 포함한 Google Cloud Platform 서비스를 개인적으로 계속 사용하려면 유료 계정 업그레이드를 선택해야 합니다. 무료 체험이 만료된 후에 비용이 결제 수단에 자동 청구되지 않습니다. 계정 업그레이드를 선택하면 비용이 청구되기 시작합니다.
계정을 설정하면 배너에 My First Project가 표시되고 배너 위에 계정 상태(크레딧 잔액 및 남은 무료 체험 일수)가 표시됩니다.

BigQuery 콘솔로 이동하는 방법
브라우저에서 console.cloud.google.com/bigquery로 이동합니다.
참고: 브라우저에서 console.cloud.google.com으로 이동하면 Google Cloud Platform의 기본 대시보드로 이동됩니다. 대시보드에서 BigQuery로 이동하려면 다음과 같이 합니다.
- 배너에서 탐색 메뉴 아이콘(햄버거 아이콘)을 클릭합니다.
- BIG DATA 섹션까지 아래로 스크롤합니다.
- BigQuery를 클릭하고 SQL workspace를 선택합니다.
BigQuery SQL 작업공간의 각 부분에 대한 소개는 BigQuery 사용법 동영상을 시청하세요.
(선택사항) BigQuery 공개 데이터 세트 살펴보기
다음 활동에서 공개 데이터 세트를 살펴보기 때문에 나중에 이 단계를 진행해도 됩니다.
- 단계별 안내를 참고하세요.
(선택사항) BigQuery에 CSV 파일 업로드
이 단계는 여기에서 직접 데이터 세트로 작업할 수 있도록 제공됩니다. 이후 강좌에서 CSV 파일을 BigQuery에 업로드하는 단계를 진행합니다.
- 단계별 안내를 참고하세요.
다른 데이터베이스 시작 안내(BigQuery를 사용하지 않는 경우)
BigQuery를 사용하면 강좌 활동을 따르기가 더 쉽지만 BigQuery 대신 다른 데이터베이스 플랫폼에 연결하여 SQL 쿼리를 연습하려면 다음의 시작 안내 리소스를 참고하세요.
- Getting started with MySQL: MySQL 설정 및 사용법 가이드입니다.
- Microsoft SQL Server 시작: SQL Server 시작 튜토리얼입니다.
- Getting started with PostgreSQL: PostgreSQL 시작 튜토리얼입니다.
- Getting started with SQLite: SQLite 빠른 시작 가이드입니다.
심층 학습: SQL 권장사항
대소문자 표기 및 구분
SQL에서는 대문자를 구분하지 않습니다. 즉, SELECT, select, SeLeCT로 작성해도 모두 작동합니다. 그러나 일관된 스타일로 대소문자를 표기하면 쿼리가 더 전문적으로 보입니다.
전문가처럼 SQL 쿼리를 작성하려면 항상 절의 시작 조건을 모두 대문자로 입력하세요(예: SELECT, FROM, WHERE 등). 함수는 모두 대문자여야 합니다(예: SUM()). 열 이름은 모두 소문자여야 하고(이 가이드 후반부의 스네이크 표기법 섹션 참고) 테이블 이름은 카멜 표기법을 따라야 합니다(이 가이드 후반부의 카멜 표기법 섹션 참고). 이러한 표기법을 따르면 쿼리를 실행할 때 반환할 데이터에 영향을 주지 않으면서 쿼리를 일관되고 읽기 쉽게 유지할 수 있습니다. 대문자 구분은 따옴표 안에 표기할 때만 중요합니다(자세한 내용은 아래 따옴표 참고).
SQL 데이터베이스 공급업체에서는 SQL 변형을 사용할 수도 있습니다. 이러한 변형을 SQL 언어라고 하며, 일부 SQL 언어는 대소문자를 구분합니다. BigQuery와 Vertica에서는 SQL 언어의 대소문자를 구분하지만 MySQL, PostgreSQL, SQL Server와 같은 대부분의 경우 대소문자를 구분하지 않습니다. 즉 country_code = ‘us’ 조건을 검색하면 'us', 'uS', 'Us', 'US'가 있는 모든 항목을 확인할 수 있습니다. 이는 BigQuery에 적용되지 않습니다. BigQuery는 대소문자를 구분하므로 이 조건을 검색하면 country_code가 정확히 'us'인 항목만 반환되며, country_code가 'US'인 항목은 결과로 반환되지 않습니다.
작은따옴표 또는 큰따옴표: ' ' 또는 " "
대부분의 경우 문자열을 참조하는 따옴표는 작은따옴표(' ')와 큰따옴표(" ")를 구분해서 사용할 필요가 없습니다. 예를 들어 SELECT가 절의 시작 조건일 때 SELECT를 'SELECT' 또는 "SELECT"와 같이 따옴표로 묶으면 SQL은 이를 텍스트 문자열로 처리합니다. 쿼리에는 SELECT 절이 필요하기 때문에 오류가 발생합니다.
그러나 다음의 두 가지 상황에서는 따옴표 종류를 구분해야 합니다.
- 모든 SQL 언어에서 문자열이 식별되게 하려는 경우
- 문자열에 아포스트로피나 따옴표가 포함된 경우
SQL 언어마다 허용 및 허용하지 않는 요소에 관한 규칙이 있지만, 거의 모든 SQL 언어의 일반적인 규칙에 따르면 문자열에 작은따옴표를 사용합니다. 이 규칙을 통해 많은 혼란을 없앨 수 있습니다. 따라서 WHERE 절에서 국가 US를 참조하려면(예: country_code = 'US') 문자열 US 주위에 작은따옴표를 사용합니다.
두 번째는 문자열 안에 따옴표가 있는 경우입니다. FavoriteFoods라는 테이블에 좋아하는 음식이 나와 있는 열이 있고 다른 열에는 친구가 나와 있습니다.
| Rachel DeSantos | Shepherd’s pie |
| Sujin Lee | Tacos |
| Najil Okoro | Spanish paella |
Rachel의 좋아하는 음식에 아포스트로피가 포함되어 있습니다. WHERE 절에 작은따옴표를 사용하여 이 음식(Shepherd’s pie)을 좋아하는 친구를 찾는 경우 쿼리는 다음과 같을 것입니다.

이 쿼리는 작동하지 않습니다. 쿼리를 실행하면 오류가 발생합니다. 그 이유는 SQL에서 텍스트 문자열이 여는 작은따옴표(')로 시작하여 닫는 작은따옴표(')로 끝나는 것으로 인식하기 때문입니다. 따라서 위의 잘못된 쿼리에서 SQL은 사용자가 찾는 Favorite_food가 'Shepherd'라고 판단합니다. Shepherd’s의 아포스트로피가 문자열을 끝내기 때문에 'Shepherd'만 인식합니다.
일반적으로 위와 같은 경우에만 작은따옴표 대신 큰따옴표를 사용하면 됩니다. 따라서 쿼리는 다음과 같습니다.

SQL은 텍스트 문자열의 시작을 작은따옴표(') 또는 큰따옴표(")로 인식합니다. 문자열이 큰따옴표로 시작되었기 때문에 SQL은 다른 큰따옴표가 있는 위치를 문자열의 끝으로 예상합니다. 결과적으로 아포스트로피는 그대로 유지한 채 'Shepherd'가 아닌 "Shepherd's pie"를 반환합니다.
메모용 주석
SQL에 익숙해지면 쿼리를 한눈에 읽고 이해할 수 있게 되지만 쿼리에 주석을 달아 처리하려는 일을 메모하는 방법 역시 좋으며 쿼리를 공유할 때는 다른 사람이 쿼리를 이해하는 데도 도움이 됩니다.
예:

위의 쿼리에서 두 개의 대시(--) 대신 #을 사용해도 괜찮지만 일부 SQL 언어의 경우 #을 인식하지 못합니다(MySQL은 #을 인식하지 못함). 따라서 --를 사용하는 것이 가장 좋으며 일관성이 있습니다. --를 사용하여 쿼리에 주석을 추가하면 데이터베이스 쿼리 엔진은 같은 줄에서 -- 뒤에 이어지는 모든 내용을 무시하고 다음 줄의 쿼리를 계속 처리합니다.
열 이름에 적합한 스네이크 표기법
항상 쿼리의 출력에는 이해하기 쉬운 이름을 사용해야 합니다. 계산이나 새 필드 연결에 따라 새 열을 만드는 경우 새 열에는 일반적으로 기본 이름(예: f0)이 주어집니다. 예:

결과는 다음과 같습니다.
| 8 | 4 | 8 | 4 |
처음 두 열은 위의 쿼리에서 이름이 지정되지 않았기 때문에 f0, f1로 이름이 지정됩니다. SQL 기본값은 f0, f1, f2, f3 등으로 지정됩니다. 마지막 두 열은 total_tickets, number_of_purchases라는 이름이 지정되었기 때문에 해당 열 이름이 쿼리 결과에 표시됩니다. 이런 이유로 특히 함수를 사용할 때 항상 열에 유용한 이름을 지정하는 것이 좋습니다. 쿼리를 실행한 후에는 예의 마지막 두 열과 같이 결과를 빠르게 파악할 수 있어야 합니다.
열 이름에서 단어 사이에 밑줄이 있다는 사실도 확인할 수 있습니다. 이름에는 공백이 없어야 합니다. 'total_tickets'에 공백이 포함되어 'total tickets'가 되면 SQL은 SUM(tickets)의 이름을 'total'로 변경합니다. 공백으로 인해 'tickets'가 의미하는 바를 이해하지 못한 상태로 'total'만 이름으로 사용하기 때문입니다. 따라서 SQL 이름에는 공백이 없어야 합니다. 공백을 사용하지 마시기 바랍니다.
권장사항은 스네이크 표기법입니다. 즉 두 단어 사이에 공백이 있는 'total tickets'는 공백 대신 밑줄이 있는 'total_tickets'로 작성해야 합니다.
테이블 이름에 적합한 카멜 표기법
테이블 이름을 지정할 때 카멜 표기법으로 대문자를 표기할 수도 있습니다. 카멜 표기법은 혹이 두 개인 쌍봉낙타처럼 각 단어의 시작 글자를 대문자로 표기합니다. 따라서 테이블 TicketsByOccasion은 카멜 표기법으로 대문자를 표기한 것입니다. 카멜 표기법의 첫 번째 단어 대문자 표기는 선택사항입니다. 첫 번째 단어를 소문자로 표기해도 됩니다. 두 방식을 구분하여 카멜 표기법과 파스칼 표기법으로 부르기도 합니다. 파스칼 표기법은 혹이 한 개 있는 단봉낙타처럼 첫 번째 단어가 대문자가 아닌 경우에 사용합니다(예: ticketsByOccasion).
결국 카멜 표기법은 방식 차이입니다. 테이블 이름은 다음과 같은 다양한 방법으로 지정할 수 있습니다.
- 전체 소문자 또는 전체 대문자(예: ticketsbyoccasion 또는 TICKETSBYOCCASION)
- 스네이크 표기법(예: tickets_by_occasion)
전체 소문자 또는 전체 대문자로 표기하면 테이블 이름을 읽기 어려울 수 있으므로 전문적인 용도로는 사용하지 않는 것이 좋습니다.
두 번째 방법인 스네이크 표기법은 엄밀히 말하면 괜찮습니다. 밑줄로 구분된 단어를 사용하면 테이블 이름을 읽기 쉬워지지만 밑줄을 추가하기 때문에 매우 길어질 수 있고 작성 시간도 더 오래 걸립니다. 따라서 이러한 이름의 테이블을 자주 사용한다면 번거로울 수 있습니다.
요약하면 테이블 이름을 작성할 때 스네이크 표기법 또는 카멜 표기법 중에서 여러분이 원하는 대로 선택하시면 됩니다. 단 테이블 이름이 읽기 쉽고 일관되는지 반드시 확인하시기 바랍니다. 또한 회사에서 선호하는 테이블 이름 명명 방식이 있는지 확인하세요. 정해진 방식이 있다면 일관성을 위해 항상 명명 규칙을 따르세요.
들여쓰기
일반적으로 한 쿼리의 각 줄 길이는 100자 이하로 유지하는 것이 좋습니다. 이렇게 하면 쿼리를 읽기가 쉽습니다. 예를 들어 100자를 초과하는 줄이 있는 다음 쿼리를 확인해보세요.

이 쿼리는 읽기 어렵고 문제를 해결하거나 편집하기도 까다롭습니다. 다음은 글자 수 100자 이하 규칙을 따르는 쿼리입니다.

SELECT 절에서 처리하려는 작업을 훨씬 쉽게 이해할 수 있습니다. 물론 들여쓰기는 SQL에서 중요하지 않기 때문에 두 쿼리 모두 문제없이 실행됩니다. 그러나 줄을 짧게 유지하려면 적절하게 들여쓰기해야 합니다. 그리고 여러분을 포함하여 여러분의 쿼리를 읽는 모두에게 유용합니다.
여러 줄 주석
주석을 여러 줄로 작성하려면 각 줄에 --를 사용하면 됩니다. 주석이 세 줄 이상인 경우에는 /*를 사용하여 주석을 시작하고 */를 사용하여 주석을 닫는 방법이 더 쉽고 깔끔해 보일 수 있습니다. 예를 들어 다음과 같이 --를 사용합니다.

또는 다음과 같이 /* */를 사용합니다.

SQL에서는 둘 중 어떤 방법을 사용해도 괜찮습니다. SQL은 작성자가 #, --, /* */ 중 무엇을 사용하든 주석을 무시합니다. 따라서 작성 방법은 작성자의 개인적인 취향에 달려 있습니다. 여러 줄 주석에 /* */를 사용하면 일반적으로 더 깔끔하게 보이며 쿼리에서 주석을 구분하는 데 도움이 됩니다. 그러나 각 방법의 옳고 그름을 판단할 수는 없습니다.
SQL 텍스트 편집기
회사마다 사용하는 SQL 플랫폼과 SQL 언어가 서로 다를 것입니다. 다양한 SQL 플랫폼(예: BigQuery, MySQL, SQL Server)에서 SQL 쿼리를 작성하고 실행할 수 있습니다. 그러나 모든 SQL 플랫폼에서 SQL 코드를 작성할 수 있는 기본 스크립트 편집기를 제공하지는 않습니다. SQL 텍스트 편집기에는 SQL 쿼리를 색상 코드 방식으로 쉽게 작성할 수 있는 인터페이스가 있습니다. 실제로 지금까지 살펴본 모든 코드는 SQL 텍스트 편집기로 작성되었습니다.
Sublime Text의 예
SQL 플랫폼에서 색상 코드를 지원하지 않는 경우 Sublime Text 또는 Atom과 같은 텍스트 편집기를 사용하는 것이 좋습니다. 이 섹션에는 Sublime Text에서 SQL이 어떻게 표시되는지 확인할 수 있습니다. Sublime Text에서 쿼리는 다음과 같이 표시됩니다.

Sublime Text를 사용하면 여러 줄의 들여쓰기 동시 삭제와 같은 고급 편집 작업도 할 수 있습니다. 예를 들어 다음과 같이 들여쓰기가 잘못된 쿼리가 있습니다.

들여쓰기를 모두 제거하고 다시 작성하고 싶을 만큼 읽기 어렵습니다. 일반 SQL 플랫폼에서는 각 줄로 이동하여 백스페이스 키를 눌러 줄마다 들여쓰기를 삭제해야 합니다. 그러나 Sublime에서는 모든 줄을 선택하고 Command(Windows의 경우 Ctrl) + [ 키를 눌러 모든 들여쓰기를 동시에 제거할 수 있습니다. 이렇게 하면 모든 줄에서 들여쓰기가 제거됩니다. 그런 다음 Command 키(Windows의 경우 Ctrl 키)를 누르고 들여 쓰려는 줄(즉 2, 4, 6번째 줄)을 선택합니다. Command 키(Windows의 경우 Ctrl 키)를 누른 상태에서 ] 키를 눌러 2, 4, 6번째 줄을 동시에 들여 씁니다. 이로써 쿼리가 정리되어 다음과 같이 표시됩니다.

Sublime Text는 정규 표현식도 지원합니다. 정규 표현식(또는 정규식)을 사용하면 쿼리에서 문자열 패턴을 검색하고 바꿀 수 있습니다. 여기에서는 정규 표현식을 다루지 않지만 매우 강력한 도구이기 때문에 정규 표현식에 관해 자세히 알아보는 것이 좋습니다.
다음 리소스를 참고해보세요.
- Sublime Text의 찾기 및 바꾸기
- 정규식 튜토리얼(정규 표현식이 처음인 경우)
- 정규식 요약본